 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Inversion of Generative Models for Effective Amortized Inference
Oct 24, 2018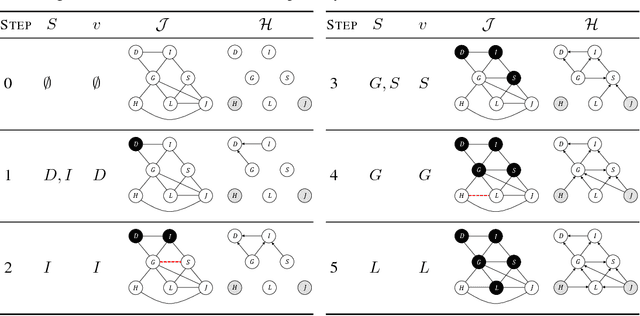
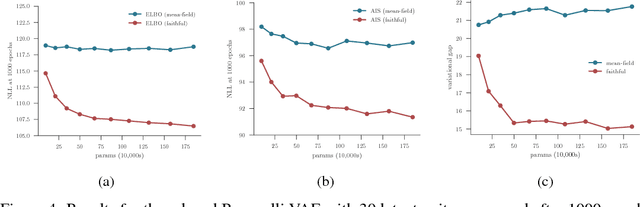

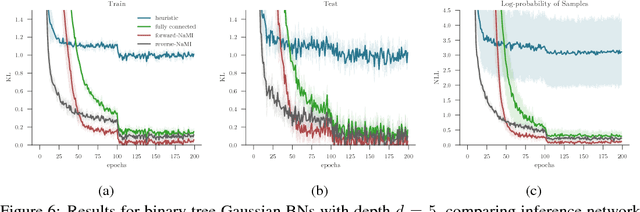
Inference amortization methods share information across multiple posterior-inference problems, allowing each to be carried out more efficiently. Generally, they require the inversion of the dependency structure in the generative model, as the modeller must learn a mapping from observations to distributions approximating the posterior. Previous approaches have involved inverting the dependency structure in a heuristic way that fails to capture these dependencies correctly, thereby limiting the achievable accuracy of the resulting approximations. We introduce an algorithm for faithfully, and minimally, inverting the graphical model structure of any generative model. Such inverses have two crucial properties: (a) they do not encode any independence assertions that are absent from the model and; (b) they are local maxima for the number of true independencies encoded. We prove the correctness of our approach and empirically show that the resulting minimally faithful inverses lead to better inference amortization than existing heuristic approaches.
Structured Disentangled Representations
May 29, 2018



Deep latent-variable models learn representations of high-dimensional data in an unsupervised manner. A number of recent efforts have focused on learning representations that disentangle statistically independent axes of variation by introducing modifications to the standard objective function. These approaches generally assume a simple diagonal Gaussian prior and as a result are not able to reliably disentangle discrete factors of variation. We propose a two-level hierarchical objective to control relative degree of statistical independence between blocks of variables and individual variables within blocks. We derive this objective as a generalization of the evidence lower bound, which allows us to explicitly represent the trade-offs between mutual information between data and representation, KL divergence between representation and prior, and coverage of the support of the empirical data distribution. Experiments on a variety of datasets demonstrate that our objective can not only disentangle discrete variables, but that doing so also improves disentanglement of other variables and, importantly, generalization even to unseen combinations of factors.
Revisiting Reweighted Wake-Sleep
May 26, 2018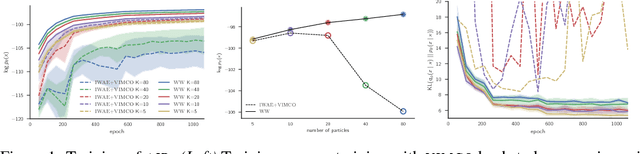
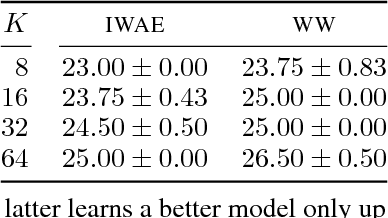
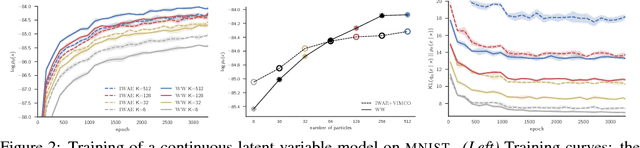
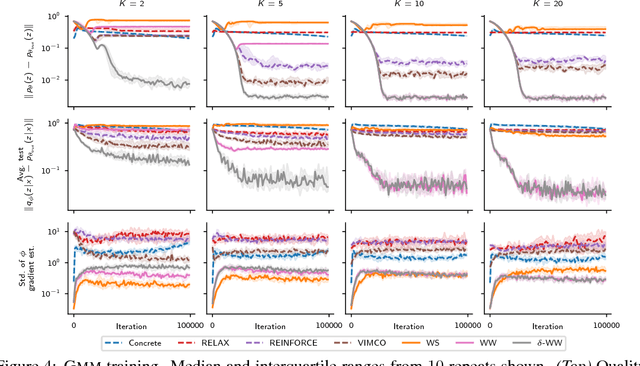
Discrete latent-variable models, while applicable in a variety of settings, can often be difficult to learn. Sampling discrete latent variables can result in high-variance gradient estimators for two primary reasons: 1. branching on the samples within the model, and 2. the lack of a pathwise derivative for the samples. While current state-of-the-art methods employ control-variate schemes for the former and continuous-relaxation methods for the latter, their utility is limited by the complexities of implementing and training effective control-variate schemes and the necessity of evaluating (potentially exponentially) many branch paths in the model. Here, we revisit the reweighted wake-sleep (RWS) (Bornschein and Bengio, 2015) algorithm, and through extensive evaluations, show that it circumvents both these issues, outperforming current state-of-the-art methods in learning discrete latent-variable models. Moreover, we observe that, unlike the importance weighted autoencoder, RWS learns better models and inference networks with increasing numbers of particles, and that its benefits extend to continuous latent-variable models as well. Our results suggest that RWS is a competitive, often preferable, alternative for learning deep generative models.
DGPose: Disentangled Semi-supervised Deep Generative Models for Human Body Analysis
Apr 17, 2018
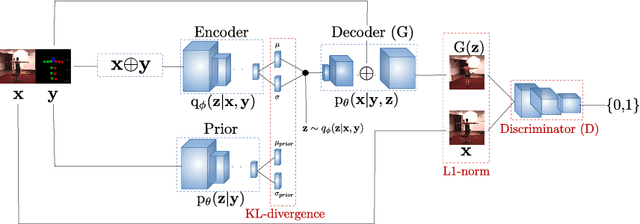
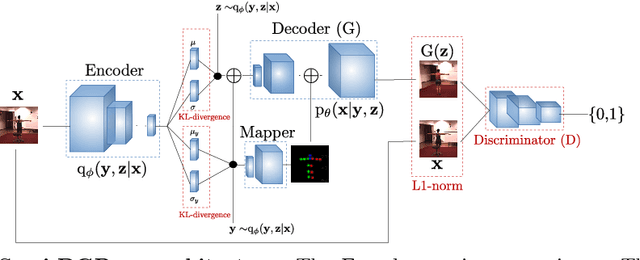
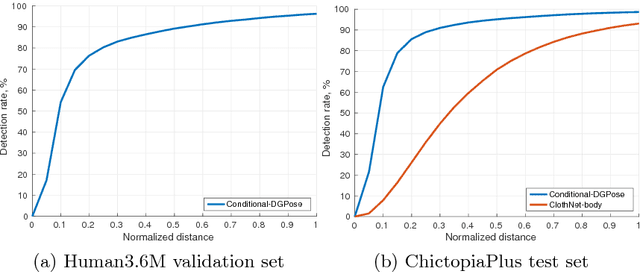
Deep generative modelling for robust human body analysis is an emerging problem with many interesting applications, since it enables analysis-by-synthesis and unsupervised learning. However, the latent space learned by such models is typically not human-interpretable, resulting in less flexible models. In this work, we adopt a structured semi-supervised variational auto-encoder approach and present a deep generative model for human body analysis where the pose and appearance are disentangled in the latent space, allowing for pose estimation. Such a disentanglement allows independent manipulation of pose and appearance and hence enables applications such as pose-transfer without being explicitly trained for such a task. In addition, the ability to train in a semi-supervised setting relaxes the need for labelled data. We demonstrate the merits of our generative model on the Human3.6M and ChictopiaPlus datasets.
FlipDial: A Generative Model for Two-Way Visual Dialogue
Apr 03, 2018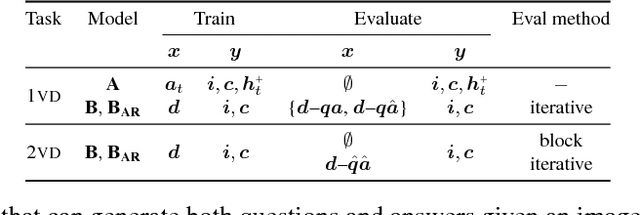
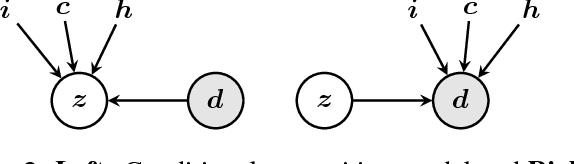
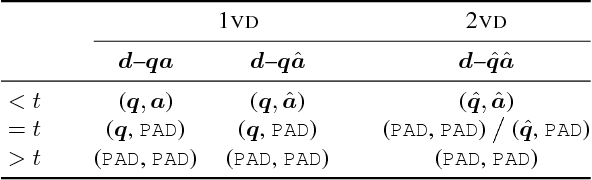
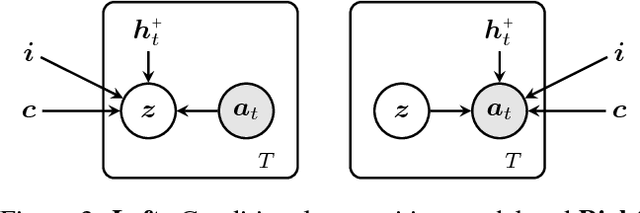
We present FlipDial, a generative model for visual dialogue that simultaneously plays the role of both participants in a visually-grounded dialogue. Given context in the form of an image and an associated caption summarising the contents of the image, FlipDial learns both to answer questions and put forward questions, capable of generating entire sequences of dialogue (question-answer pairs) which are diverse and relevant to the image. To do this, FlipDial relies on a simple but surprisingly powerful idea: it uses convolutional neural networks (CNNs) to encode entire dialogues directly, implicitly capturing dialogue context, and conditional VAEs to learn the generative model. FlipDial outperforms the state-of-the-art model in the sequential answering task (one-way visual dialogue) on the VisDial dataset by 5 points in Mean Rank using the generated answers. We are the first to extend this paradigm to full two-way visual dialogue, where our model is capable of generating both questions and answers in sequence based on a visual input, for which we propose a set of novel evaluation measures and metrics.
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017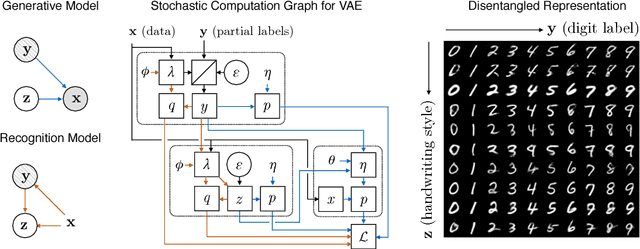

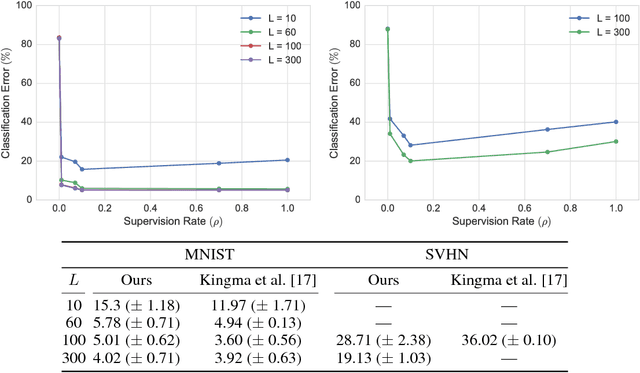
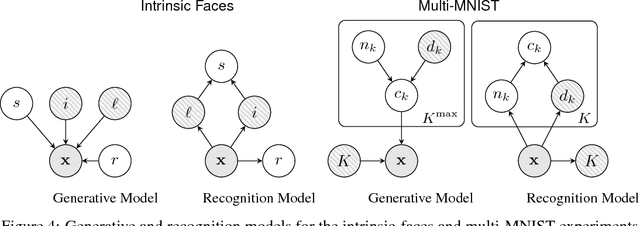
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.
Playing Doom with SLAM-Augmented Deep Reinforcement Learning
Dec 01, 2016

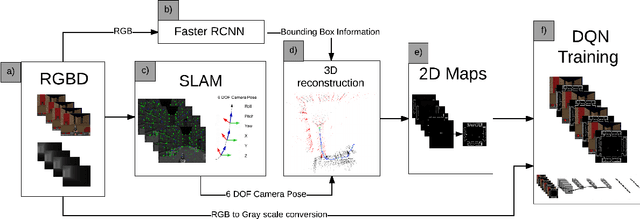
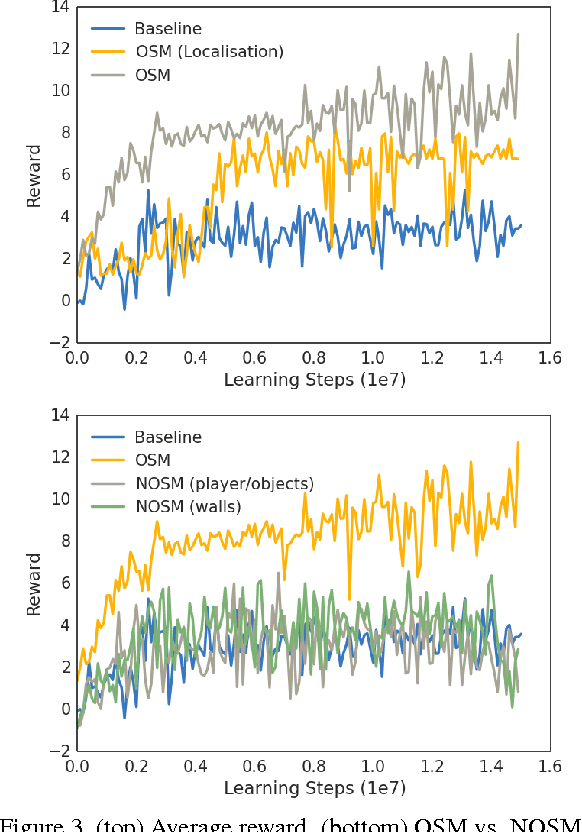
A number of recent approaches to policy learning in 2D game domains have been successful going directly from raw input images to actions. However when employed in complex 3D environments, they typically suffer from challenges related to partial observability, combinatorial exploration spaces, path planning, and a scarcity of rewarding scenarios. Inspired from prior work in human cognition that indicates how humans employ a variety of semantic concepts and abstractions (object categories, localisation, etc.) to reason about the world, we build an agent-model that incorporates such abstractions into its policy-learning framework. We augment the raw image input to a Deep Q-Learning Network (DQN), by adding details of objects and structural elements encountered, along with the agent's localisation. The different components are automatically extracted and composed into a topological representation using on-the-fly object detection and 3D-scene reconstruction.We evaluate the efficacy of our approach in Doom, a 3D first-person combat game that exhibits a number of challenges discussed, and show that our augmented framework consistently learns better, more effective policies.
Inducing Interpretable Representations with Variational Autoencoders
Nov 22, 2016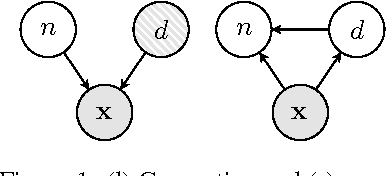
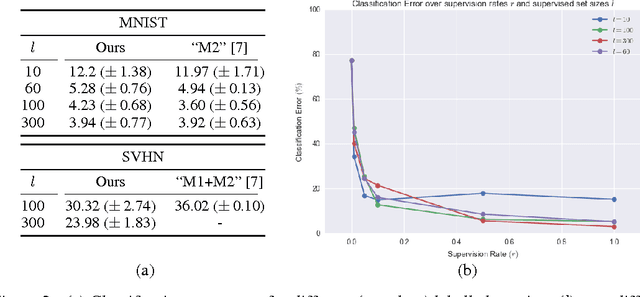

We develop a framework for incorporating structured graphical models in the \emph{encoders} of variational autoencoders (VAEs) that allows us to induce interpretable representations through approximate variational inference. This allows us to both perform reasoning (e.g. classification) under the structural constraints of a given graphical model, and use deep generative models to deal with messy, high-dimensional domains where it is often difficult to model all the variation. Learning in this framework is carried out end-to-end with a variational objective, applying to both unsupervised and semi-supervised schemes.
Coarse-to-Fine Sequential Monte Carlo for Probabilistic Programs
Sep 09, 2015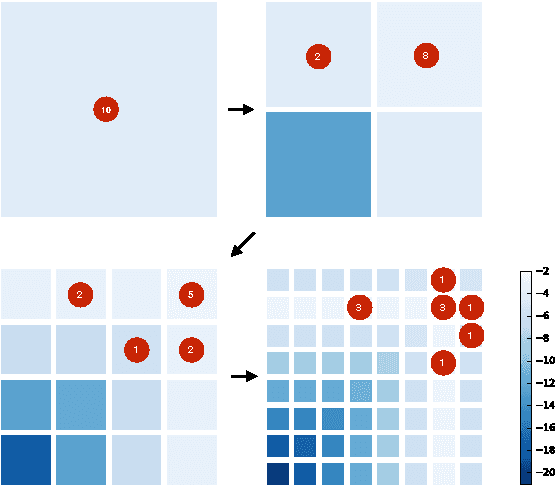


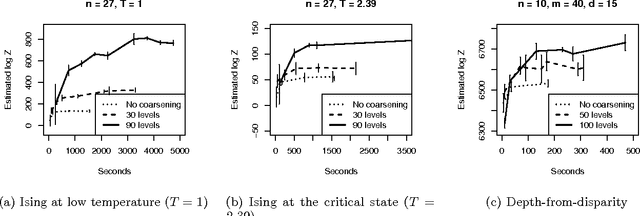
Many practical techniques for probabilistic inference require a sequence of distributions that interpolate between a tractable distribution and an intractable distribution of interest. Usually, the sequences used are simple, e.g., based on geometric averages between distributions. When models are expressed as probabilistic programs, the models themselves are highly structured objects that can be used to derive annealing sequences that are more sensitive to domain structure. We propose an algorithm for transforming probabilistic programs to coarse-to-fine programs which have the same marginal distribution as the original programs, but generate the data at increasing levels of detail, from coarse to fine. We apply this algorithm to an Ising model, its depth-from-disparity variation, and a factorial hidden Markov model. We show preliminary evidence that the use of coarse-to-fine models can make existing generic inference algorithms more efficient.
Seeing What You're Told: Sentence-Guided Activity Recognition In Video
May 28, 2014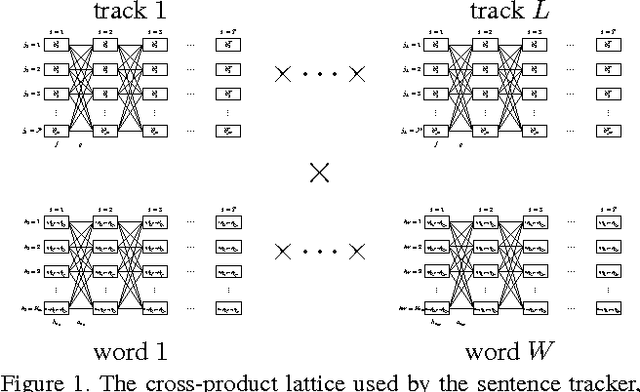



We present a system that demonstrates how the compositional structure of events, in concert with the compositional structure of language, can interplay with the underlying focusing mechanisms in video action recognition, thereby providing a medium, not only for top-down and bottom-up integration, but also for multi-modal integration between vision and language. We show how the roles played by participants (nouns), their characteristics (adjectives), the actions performed (verbs), the manner of such actions (adverbs), and changing spatial relations between participants (prepositions) in the form of whole sentential descriptions mediated by a grammar, guides the activity-recognition process. Further, the utility and expressiveness of our framework is demonstrated by performing three separate tasks in the domain of multi-activity videos: sentence-guided focus of attention, generation of sentential descriptions of video, and query-based video search, simply by leveraging the framework in different manners.