 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Approaches for Out-Of-Distribution Dermoscopic Lesion Detection
Nov 08, 2021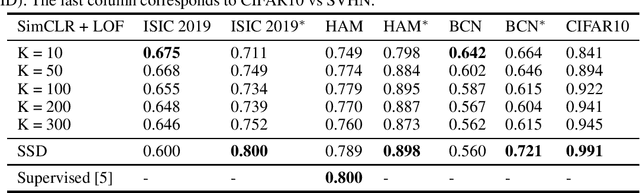

There are limited works showing the efficacy of unsupervised Out-of-Distribution (OOD) methods on complex medical data. Here, we present preliminary findings of our unsupervised OOD detection algorithm, SimCLR-LOF, as well as a recent state of the art approach (SSD), applied on medical images. SimCLR-LOF learns semantically meaningful features using SimCLR and uses LOF for scoring if a test sample is OOD. We evaluated on the multi-source International Skin Imaging Collaboration (ISIC) 2019 dataset, and show results that are competitive with SSD as well as with recent supervised approaches applied on the same data.
Variation is the Norm: Brain State Dynamics Evoked By Emotional Video Clips
Oct 24, 2021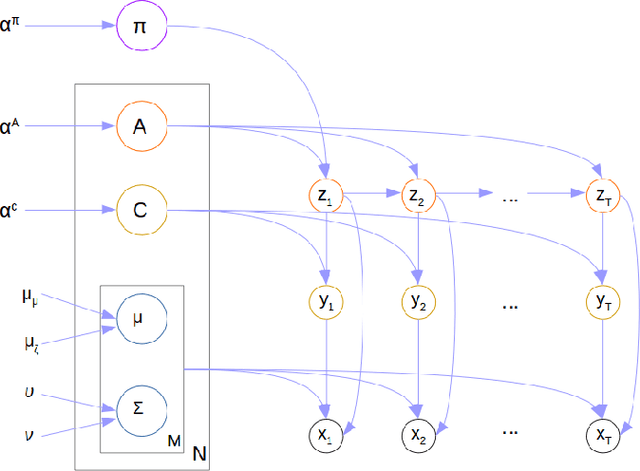
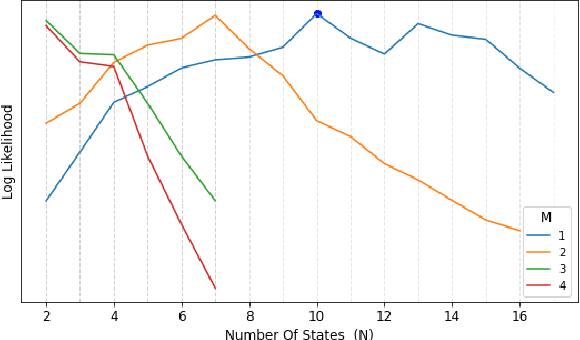
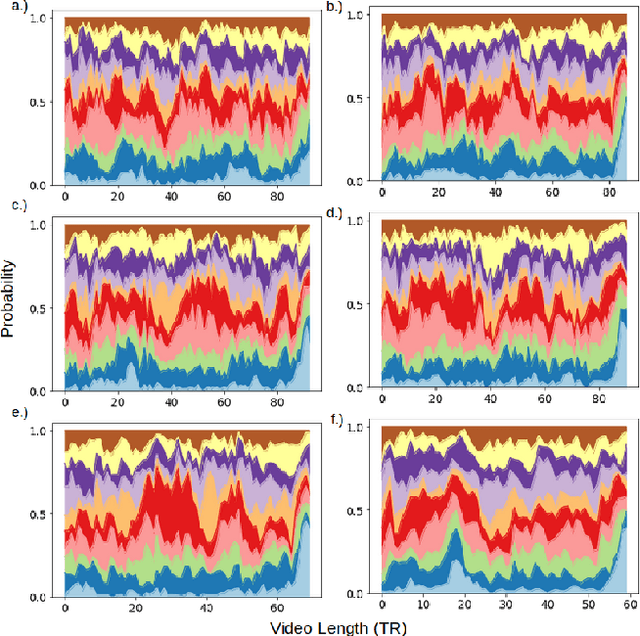
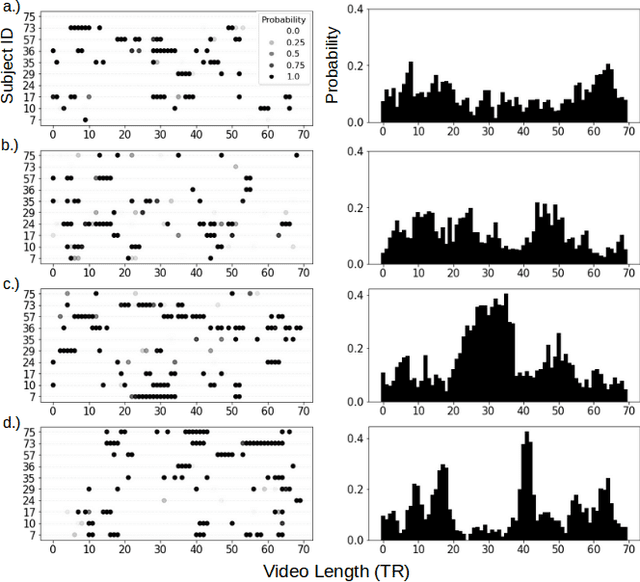
For the last several decades, emotion research has attempted to identify a "biomarker" or consistent pattern of brain activity to characterize a single category of emotion (e.g., fear) that will remain consistent across all instances of that category, regardless of individual and context. In this study, we investigated variation rather than consistency during emotional experiences while people watched video clips chosen to evoke instances of specific emotion categories. Specifically, we developed a sequential probabilistic approach to model the temporal dynamics in a participant's brain activity during video viewing. We characterized brain states during these clips as distinct state occupancy periods between state transitions in blood oxygen level dependent (BOLD) signal patterns. We found substantial variation in the state occupancy probability distributions across individuals watching the same video, supporting the hypothesis that when it comes to the brain correlates of emotional experience, variation may indeed be the norm.
Reducing Line-of-block Artifacts in Cardiac Activation Maps Estimated Using ECG Imaging: A Comparison of Source Models and Estimation Methods
Aug 18, 2021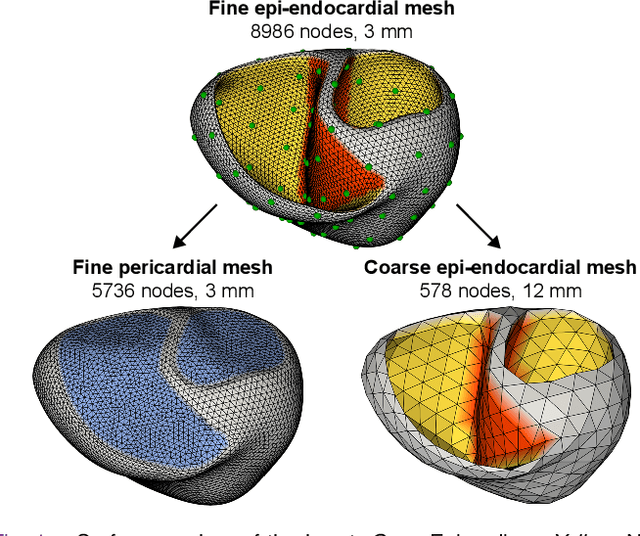
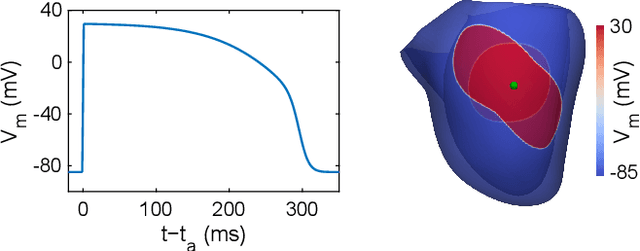
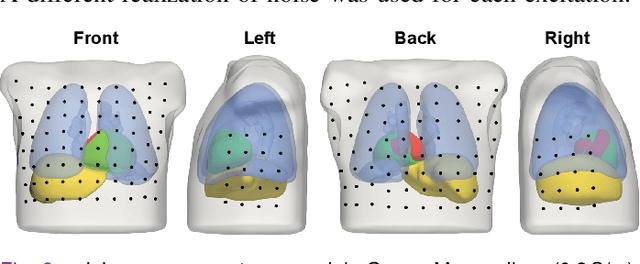
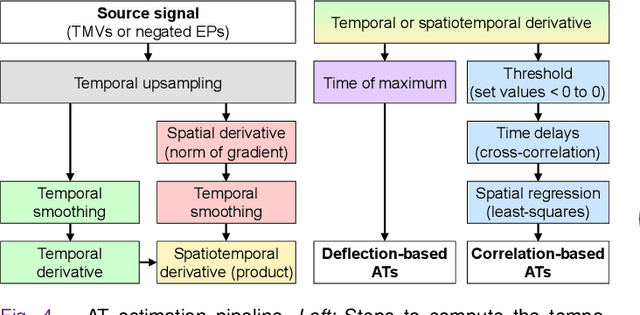
Objective: To investigate cardiac activation maps estimated using electrocardiographic imaging and to find methods reducing line-of-block (LoB) artifacts, while preserving real LoBs. Methods: Body surface potentials were computed for 137 simulated ventricular excitations. Subsequently, the inverse problem was solved to obtain extracellular potentials (EP) and transmembrane voltages (TMV). From these, activation times (AT) were estimated using four methods and compared to the ground truth. This process was evaluated with two cardiac mesh resolutions. Factors contributing to LoB artifacts were identified by analyzing the impact of spatial and temporal smoothing on the morphology of source signals. Results: AT estimation using a spatiotemporal derivative performed better than using a temporal derivative. Compared to deflection-based AT estimation, correlation-based methods were less prone to LoB artifacts but performed worse in identifying real LoBs. Temporal smoothing could eliminate artifacts for TMVs but not for EPs, which could be linked to their temporal morphology. TMVs led to more accurate ATs on the septum than EPs. Mesh resolution had a negligible effect on inverse reconstructions, but small distances were important for cross-correlation-based estimation of AT delays. Conclusion: LoB artifacts are mainly caused by the inherent spatial smoothing effect of the inverse reconstruction. Among the configurations evaluated, only deflection-based AT estimation in combination with TMVs and strong temporal smoothing can prevent LoB artifacts, while preserving real LoBs. Significance: Regions of slow conduction are of considerable clinical interest and LoB artifacts observed in non-invasive ATs can lead to misinterpretations. We addressed this problem by identifying factors causing such artifacts and methods to reduce them.
Segmentation of Cellular Patterns in Confocal Images of Melanocytic Lesions in vivo via a Multiscale Encoder-Decoder Network (MED-Net)
Jan 03, 2020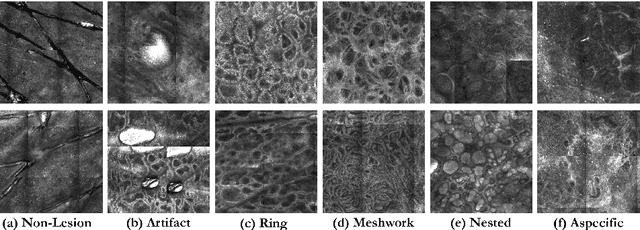
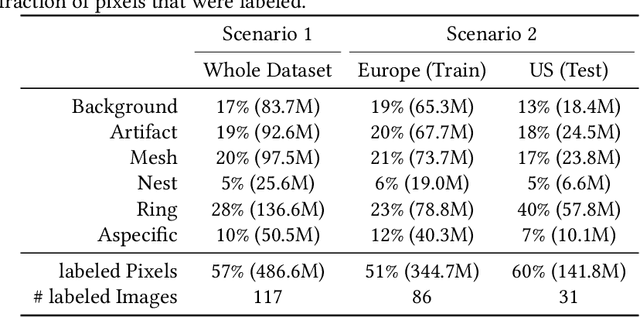
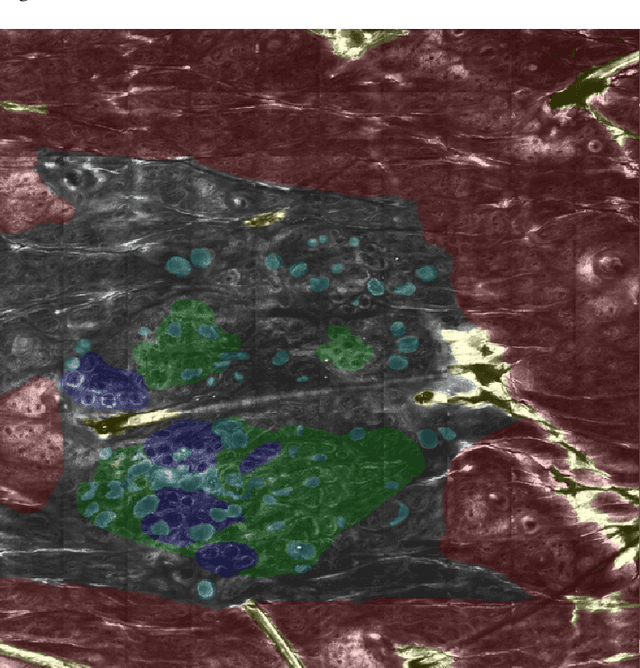
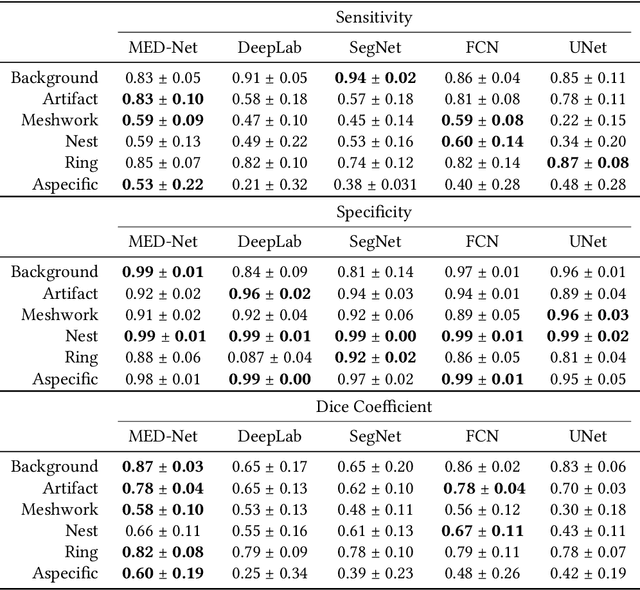
In-vivo optical microscopy is advancing into routine clinical practice for non-invasively guiding diagnosis and treatment of cancer and other diseases, and thus beginning to reduce the need for traditional biopsy. However, reading and analysis of the optical microscopic images are generally still qualitative, relying mainly on visual examination. Here we present an automated semantic segmentation method called "Multiscale Encoder-Decoder Network (MED-Net)" that provides pixel-wise labeling into classes of patterns in a quantitative manner. The novelty in our approach is the modeling of textural patterns at multiple scales. This mimics the procedure for examining pathology images, which routinely starts with low magnification (low resolution, large field of view) followed by closer inspection of suspicious areas with higher magnification (higher resolution, smaller fields of view). We trained and tested our model on non-overlapping partitions of 117 reflectance confocal microscopy (RCM) mosaics of melanocytic lesions, an extensive dataset for this application, collected at four clinics in the US, and two in Italy. With patient-wise cross-validation, we achieved pixel-wise mean sensitivity and specificity of $70\pm11\%$ and $95\pm2\%$, respectively, with $0.71\pm0.09$ Dice coefficient over six classes. In the scenario, we partitioned the data clinic-wise and tested the generalizability of the model over multiple clinics. In this setting, we achieved pixel-wise mean sensitivity and specificity of $74\%$ and $95\%$, respectively, with $0.75$ Dice coefficient. We compared MED-Net against the state-of-the-art semantic segmentation models and achieved better quantitative segmentation performance. Our results also suggest that, due to its nested multiscale architecture, the MED-Net model annotated RCM mosaics more coherently, avoiding unrealistic-fragmented annotations.
Evaluating Combinatorial Generalization in Variational Autoencoders
Nov 11, 2019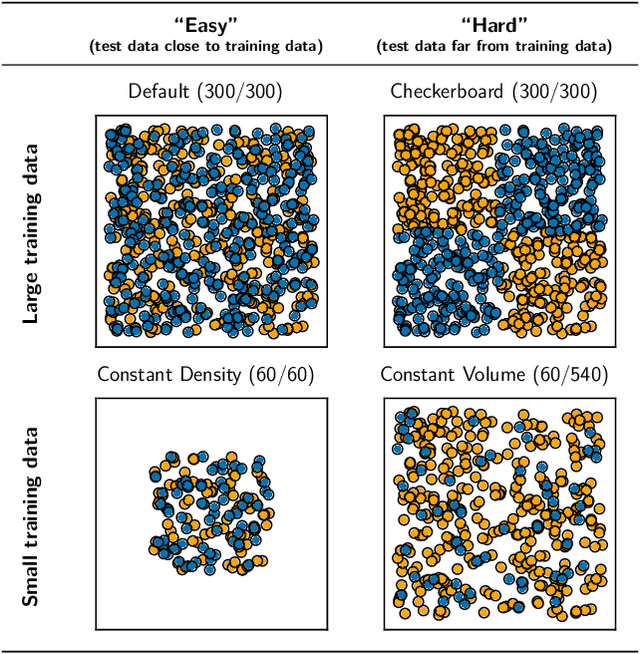
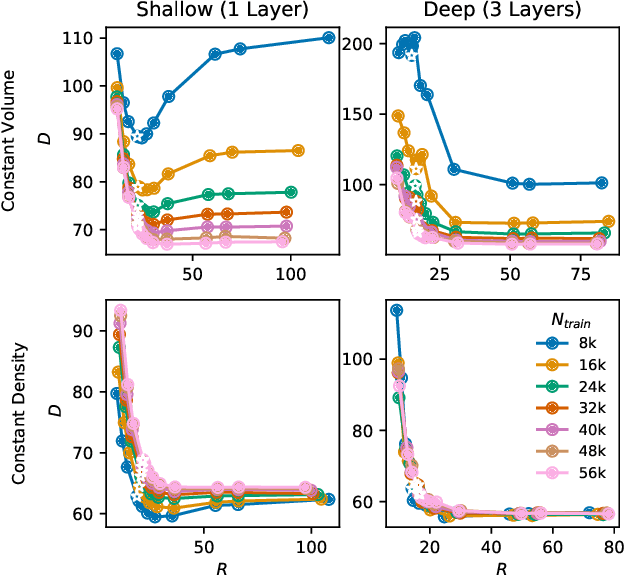

We evaluate the ability of variational autoencoders to generalize to unseen examples in domains with a large combinatorial space of feature values. Our experiments systematically evaluate the effect of network width, depth, regularization, and the typical distance between the training and test examples. Increasing network capacity benefits generalization in easy problems, where test-set examples are similar to training examples. In more difficult problems, increasing capacity deteriorates generalization when optimizing the standard VAE objective, but once again improves generalization when we decrease the KL regularization. Our results establish that interplay between model capacity and KL regularization is not clear cut; we need to take the typical distance between train and test examples into account when evaluating generalization.
Can VAEs Generate Novel Examples?
Dec 22, 2018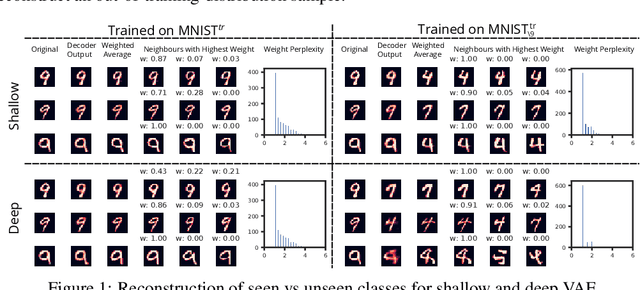
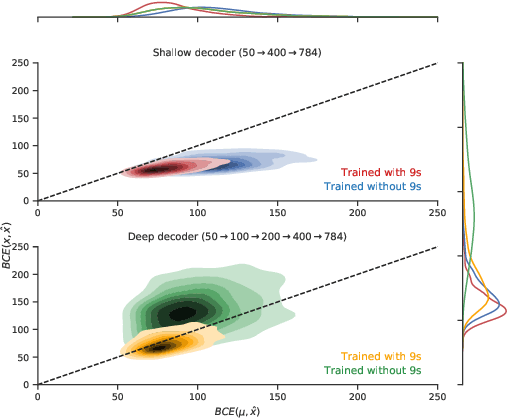

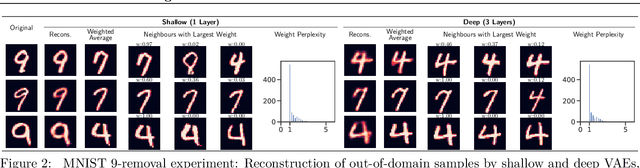
An implicit goal in works on deep generative models is that such models should be able to generate novel examples that were not previously seen in the training data. In this paper, we investigate to what extent this property holds for widely employed variational autoencoder (VAE) architectures. VAEs maximize a lower bound on the log marginal likelihood, which implies that they will in principle overfit the training data when provided with a sufficiently expressive decoder. In the limit of an infinite capacity decoder, the optimal generative model is a uniform mixture over the training data. More generally, an optimal decoder should output a weighted average over the examples in the training data, where the magnitude of the weights is determined by the proximity in the latent space. This leads to the hypothesis that, for a sufficiently high capacity encoder and decoder, the VAE decoder will perform nearest-neighbor matching according to the coordinates in the latent space. To test this hypothesis, we investigate generalization on the MNIST dataset. We consider both generalization to new examples of previously seen classes, and generalization to the classes that were withheld from the training set. In both cases, we find that reconstructions are closely approximated by nearest neighbors for higher-dimensional parameterizations. When generalizing to unseen classes however, lower-dimensional parameterizations offer a clear advantage.
A Multiresolution Convolutional Neural Network with Partial Label Training for Annotating Reflectance Confocal Microscopy Images of Skin
Aug 23, 2018
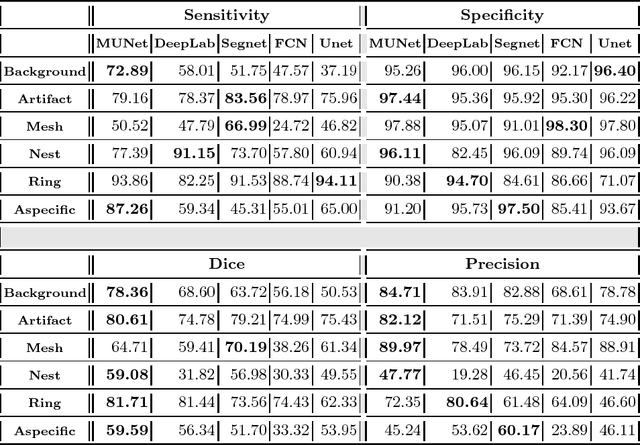
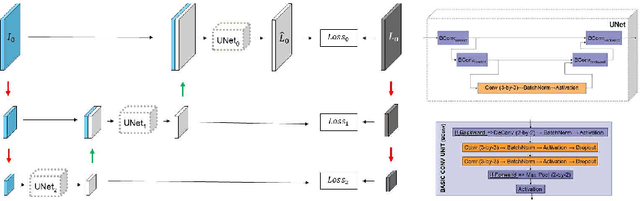

We describe a new multiresolution "nested encoder-decoder" convolutional network architecture and use it to annotate morphological patterns in reflectance confocal microscopy (RCM) images of human skin for aiding cancer diagnosis. Skin cancers are the most common types of cancers, melanoma being the deadliest among them. RCM is an effective, non-invasive pre-screening tool for skin cancer diagnosis, with the required cellular resolution. However, images are complex, low-contrast, and highly variable, so that clinicians require months to years of expert-level training to be able to make accurate assessments. In this paper, we address classifying 4 key clinically important structural/textural patterns in RCM images. The occurrence and morphology of these patterns are used by clinicians for diagnosis of melanomas. The large size of RCM images, the large variance of pattern size, the large-scale range over which patterns appear, the class imbalance in collected images, and the lack of fully-labeled images all make this a challenging problem to address, even with automated machine learning tools. We designed a novel nested U-net architecture to cope with these challenges, and a selective loss function to handle partial labeling. Trained and tested on 56 melanoma-suspicious, partially labeled, 12k x 12k pixel images, our network automatically annotated diagnostic patterns with high sensitivity and specificity, providing consistent labels for unlabeled sections of the test images. Providing such annotation will aid clinicians in achieving diagnostic accuracy, and perhaps more important, dramatically facilitate clinical training, thus enabling much more rapid adoption of RCM into widespread clinical use process. In addition, our adaptation of U-net architecture provides an intrinsically multiresolution deep network that may be useful in other challenging biomedical image analysis applications.
Structured Disentangled Representations
May 29, 2018



Deep latent-variable models learn representations of high-dimensional data in an unsupervised manner. A number of recent efforts have focused on learning representations that disentangle statistically independent axes of variation by introducing modifications to the standard objective function. These approaches generally assume a simple diagonal Gaussian prior and as a result are not able to reliably disentangle discrete factors of variation. We propose a two-level hierarchical objective to control relative degree of statistical independence between blocks of variables and individual variables within blocks. We derive this objective as a generalization of the evidence lower bound, which allows us to explicitly represent the trade-offs between mutual information between data and representation, KL divergence between representation and prior, and coverage of the support of the empirical data distribution. Experiments on a variety of datasets demonstrate that our objective can not only disentangle discrete variables, but that doing so also improves disentanglement of other variables and, importantly, generalization even to unseen combinations of factors.
Delineation of Skin Strata in Reflectance Confocal Microscopy Images using Recurrent Convolutional Networks with Toeplitz Attention
Dec 01, 2017
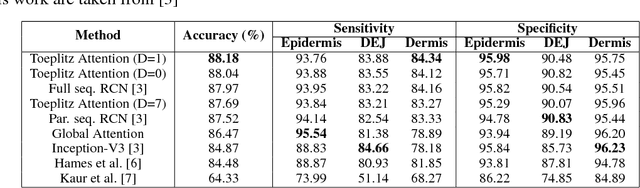
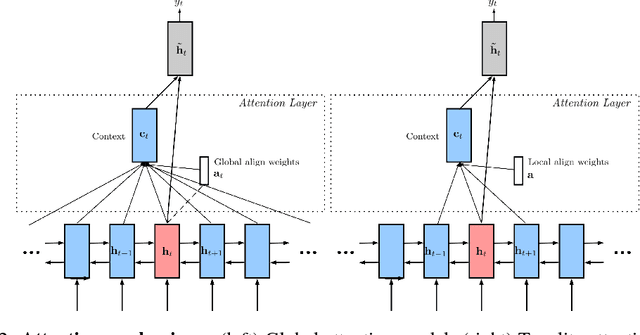
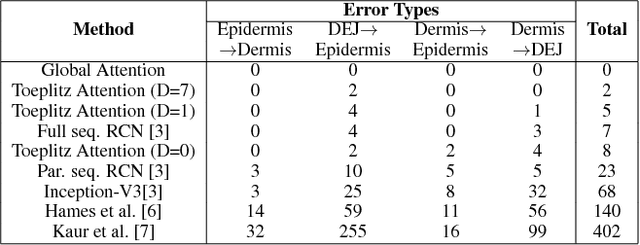
Reflectance confocal microscopy (RCM) is an effective, non-invasive pre-screening tool for skin cancer diagnosis, but it requires extensive training and experience to assess accurately. There are few quantitative tools available to standardize image acquisition and analysis, and the ones that are available are not interpretable. In this study, we use a recurrent neural network with attention on convolutional network features. We apply it to delineate skin strata in vertically-oriented stacks of transverse RCM image slices in an interpretable manner. We introduce a new attention mechanism called Toeplitz attention, which constrains the attention map to have a Toeplitz structure. Testing our model on an expert labeled dataset of 504 RCM stacks, we achieve 88.17% image-wise classification accuracy, which is the current state-of-art.