 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchAudio: Building Blocks for Audio and Speech Processing
Oct 28, 2021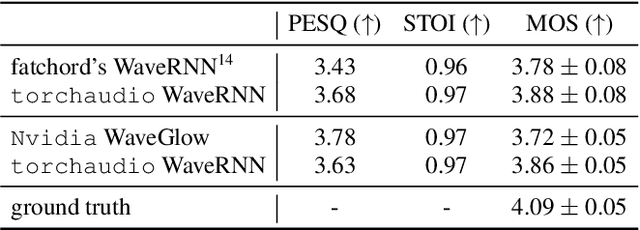
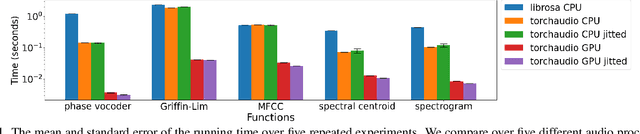


This document describes version 0.10 of torchaudio: building blocks for machine learning applications in the audio and speech processing domain. The objective of torchaudio is to accelerate the development and deployment of machine learning applications for researchers and engineers by providing off-the-shelf building blocks. The building blocks are designed to be GPU-compatible, automatically differentiable, and production-ready. torchaudio can be easily installed from Python Package Index repository and the source code is publicly available under a BSD-2-Clause License (as of September 2021) at https://github.com/pytorch/audio. In this document, we provide an overview of the design principles, functionalities, and benchmarks of torchaudio. We also benchmark our implementation of several audio and speech operations and models. We verify through the benchmarks that our implementations of various operations and models are valid and perform similarly to other publicly available implementations.