 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStain-Robust Mitotic Figure Detection for MIDOG 2022 Challenge
Aug 26, 2022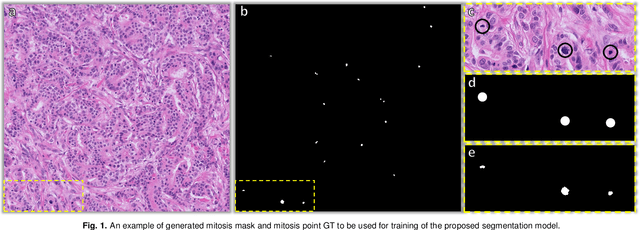

The detection of mitotic figures from different scanners/sites remains an important topic of research, owing to its potential in assisting clinicians with tumour grading. The MItosis DOmain Generalization (MIDOG) 2022 challenge aims to test the robustness of detection models on unseen data from multiple scanners and tissue types for this task. We present a short summary of the approach employed by the TIA Centre team to address this challenge. Our approach is based on a hybrid detection model, where mitotic candidates are segmented, before being refined by a deep learning classifier. Cross-validation on the training images achieved the F1-score of 0.816 and 0.784 on the preliminary test set, demonstrating the generalizability of our model to unseen data from new scanners.
IMPaSh: A Novel Domain-shift Resistant Representation for Colorectal Cancer Tissue Classification
Aug 23, 2022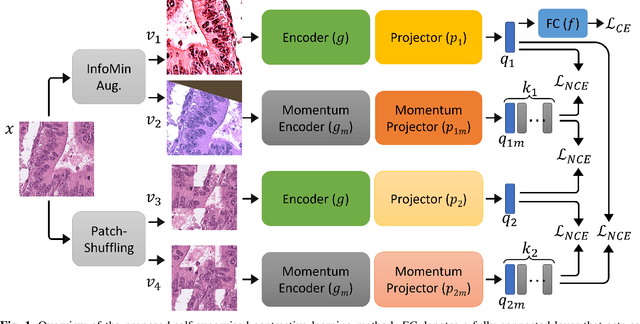
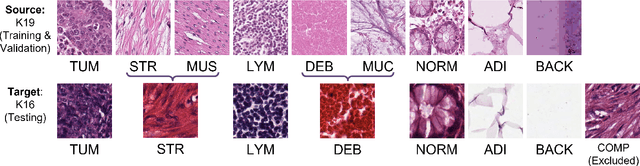
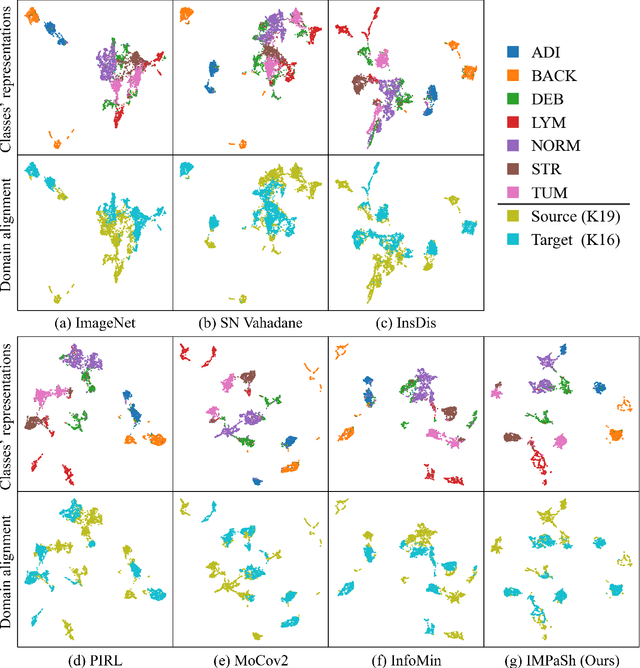
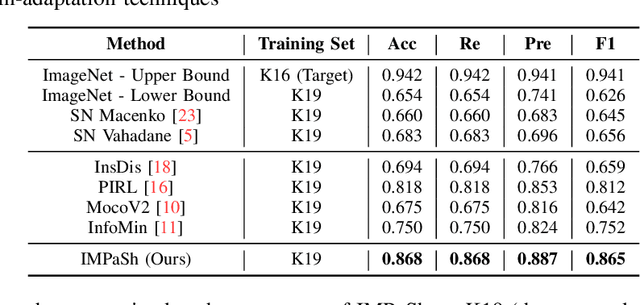
The appearance of histopathology images depends on tissue type, staining and digitization procedure. These vary from source to source and are the potential causes for domain-shift problems. Owing to this problem, despite the great success of deep learning models in computational pathology, a model trained on a specific domain may still perform sub-optimally when we apply them to another domain. To overcome this, we propose a new augmentation called PatchShuffling and a novel self-supervised contrastive learning framework named IMPaSh for pre-training deep learning models. Using these, we obtained a ResNet50 encoder that can extract image representation resistant to domain-shift. We compared our derived representation against those acquired based on other domain-generalization techniques by using them for the cross-domain classification of colorectal tissue images. We show that the proposed method outperforms other traditional histology domain-adaptation and state-of-the-art self-supervised learning methods. Code is available at: https://github.com/trinhvg/IMPash .
TIAger: Tumor-Infiltrating Lymphocyte Scoring in Breast Cancer for the TiGER Challenge
Jun 23, 2022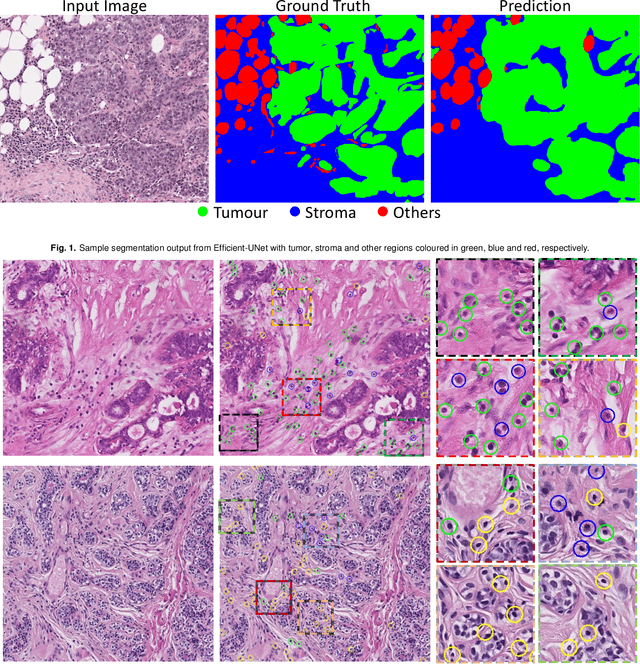
The quantification of tumor-infiltrating lymphocytes (TILs) has been shown to be an independent predictor for prognosis of breast cancer patients. Typically, pathologists give an estimate of the proportion of the stromal region that contains TILs to obtain a TILs score. The Tumor InfiltratinG lymphocytes in breast cancER (TiGER) challenge, aims to assess the prognostic significance of computer-generated TILs scores for predicting survival as part of a Cox proportional hazards model. For this challenge, as the TIAger team, we have developed an algorithm to first segment tumor vs. stroma, before localising the tumor bulk region for TILs detection. Finally, we use these outputs to generate a TILs score for each case. On preliminary testing, our approach achieved a tumor-stroma weighted Dice score of 0.791 and a FROC score of 0.572 for lymphocytic detection. For predicting survival, our model achieved a C-index of 0.719. These results achieved first place across the preliminary testing leaderboards of the TiGER challenge.
Mitosis domain generalization in histopathology images -- The MIDOG challenge
Apr 06, 2022
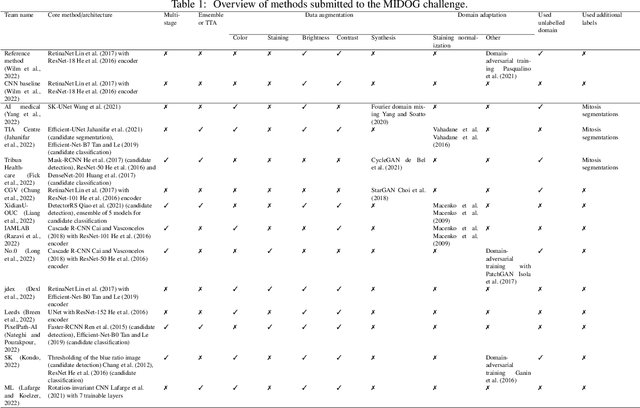

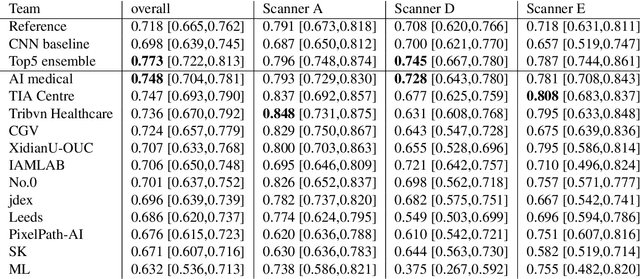
The density of mitotic figures within tumor tissue is known to be highly correlated with tumor proliferation and thus is an important marker in tumor grading. Recognition of mitotic figures by pathologists is known to be subject to a strong inter-rater bias, which limits the prognostic value. State-of-the-art deep learning methods can support the expert in this assessment but are known to strongly deteriorate when applied in a different clinical environment than was used for training. One decisive component in the underlying domain shift has been identified as the variability caused by using different whole slide scanners. The goal of the MICCAI MIDOG 2021 challenge has been to propose and evaluate methods that counter this domain shift and derive scanner-agnostic mitosis detection algorithms. The challenge used a training set of 200 cases, split across four scanning systems. As a test set, an additional 100 cases split across four scanning systems, including two previously unseen scanners, were given. The best approaches performed on an expert level, with the winning algorithm yielding an F_1 score of 0.748 (CI95: 0.704-0.781). In this paper, we evaluate and compare the approaches that were submitted to the challenge and identify methodological factors contributing to better performance.
One Model is All You Need: Multi-Task Learning Enables Simultaneous Histology Image Segmentation and Classification
Feb 28, 2022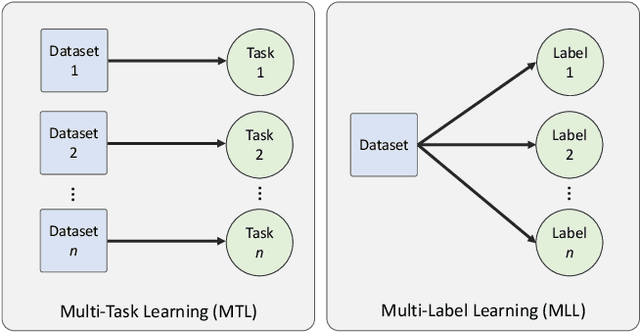
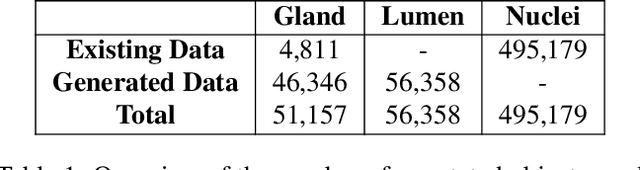
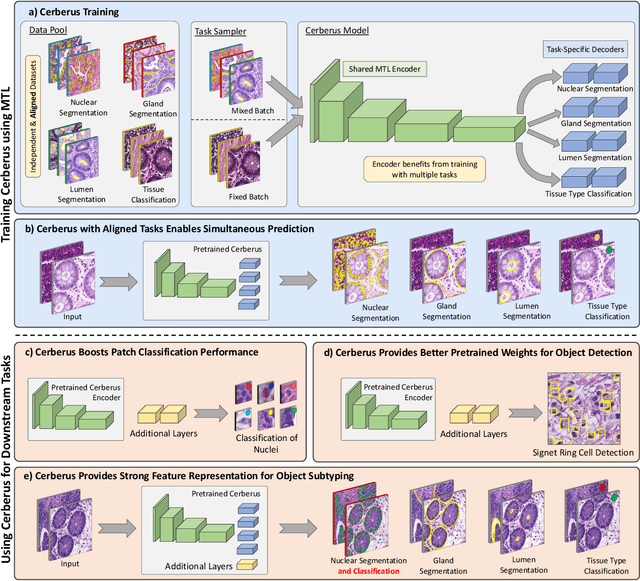

The recent surge in performance for image analysis of digitised pathology slides can largely be attributed to the advance of deep learning. Deep models can be used to initially localise various structures in the tissue and hence facilitate the extraction of interpretable features for biomarker discovery. However, these models are typically trained for a single task and therefore scale poorly as we wish to adapt the model for an increasing number of different tasks. Also, supervised deep learning models are very data hungry and therefore rely on large amounts of training data to perform well. In this paper we present a multi-task learning approach for segmentation and classification of nuclei, glands, lumen and different tissue regions that leverages data from multiple independent data sources. While ensuring that our tasks are aligned by the same tissue type and resolution, we enable simultaneous prediction with a single network. As a result of feature sharing, we also show that the learned representation can be used to improve downstream tasks, including nuclear classification and signet ring cell detection. As part of this work, we use a large dataset consisting of over 600K objects for segmentation and 440K patches for classification and make the data publicly available. We use our approach to process the colorectal subset of TCGA, consisting of 599 whole-slide images, to localise 377 million, 900K and 2.1 million nuclei, glands and lumen respectively. We make this resource available to remove a major barrier in the development of explainable models for computational pathology.
CoNIC: Colon Nuclei Identification and Counting Challenge 2022
Nov 29, 2021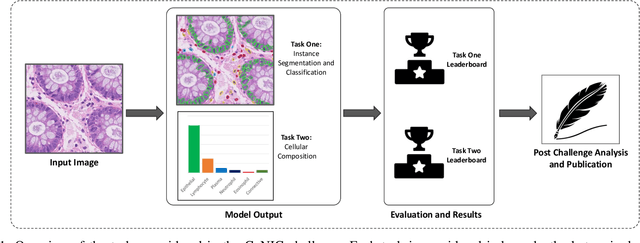
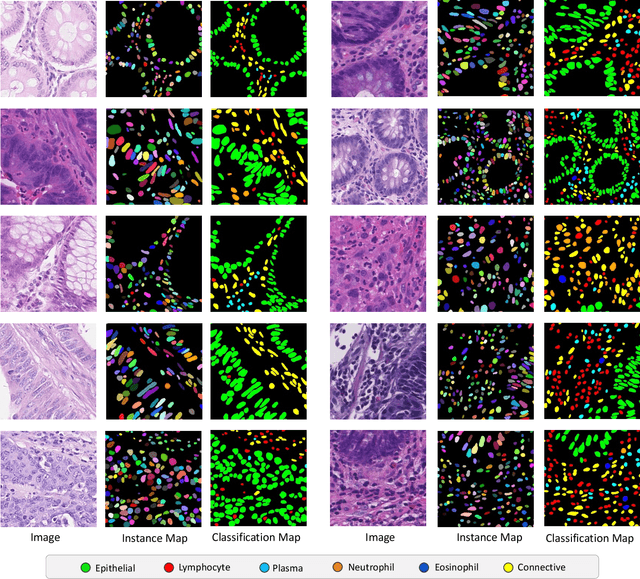
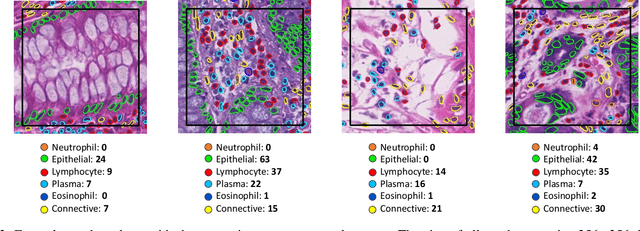
Nuclear segmentation, classification and quantification within Haematoxylin & Eosin stained histology images enables the extraction of interpretable cell-based features that can be used in downstream explainable models in computational pathology (CPath). However, automatic recognition of different nuclei is faced with a major challenge in that there are several different types of nuclei, some of them exhibiting large intra-class variability. To help drive forward research and innovation for automatic nuclei recognition in CPath, we organise the Colon Nuclei Identification and Counting (CoNIC) Challenge. The challenge encourages researchers to develop algorithms that perform segmentation, classification and counting of nuclei within the current largest known publicly available nuclei-level dataset in CPath, containing around half a million labelled nuclei. Therefore, the CoNIC challenge utilises over 10 times the number of nuclei as the previous largest challenge dataset for nuclei recognition. It is important for algorithms to be robust to input variation if we wish to deploy them in a clinical setting. Therefore, as part of this challenge we will also test the sensitivity of each submitted algorithm to certain input variations.
Stain-Robust Mitotic Figure Detection for the Mitosis Domain Generalization Challenge
Sep 29, 2021
The detection of mitotic figures from different scanners/sites remains an important topic of research, owing to its potential in assisting clinicians with tumour grading. The MItosis DOmain Generalization (MIDOG) challenge aims to test the robustness of detection models on unseen data from multiple scanners for this task. We present a short summary of the approach employed by the TIA Centre team to address this challenge. Our approach is based on a hybrid detection model, where mitotic candidates are segmented on stain normalised images, before being refined by a deep learning classifier. Cross-validation on the training images achieved the F1-score of 0.786 and 0.765 on the preliminary test set, demonstrating the generalizability of our model to unseen data from new scanners.
Simultaneous Nuclear Instance and Layer Segmentation in Oral Epithelial Dysplasia
Sep 01, 2021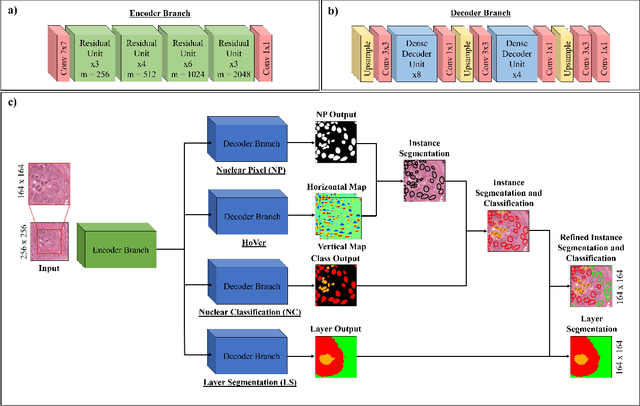
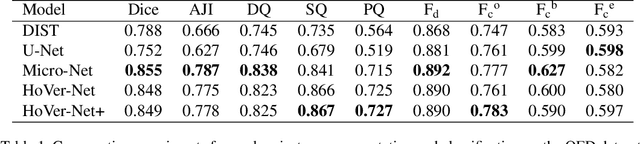
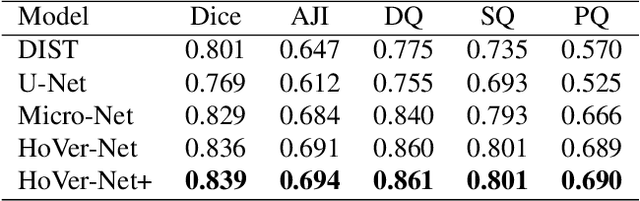
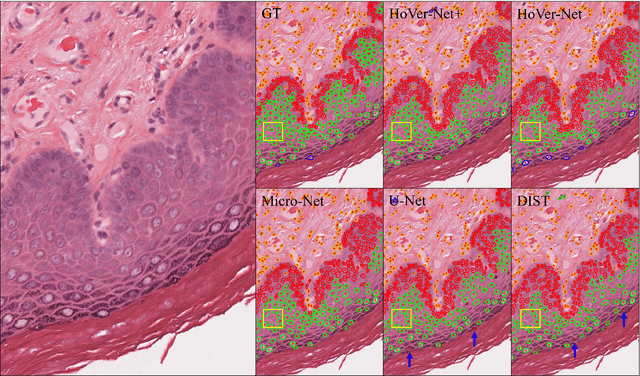
Oral epithelial dysplasia (OED) is a pre-malignant histopathological diagnosis given to lesions of the oral cavity. Predicting OED grade or whether a case will transition to malignancy is critical for early detection and appropriate treatment. OED typically begins in the lower third of the epithelium before progressing upwards with grade severity, thus we have suggested that segmenting intra-epithelial layers, in addition to individual nuclei, may enable researchers to evaluate important layer-specific morphological features for grade/malignancy prediction. We present HoVer-Net+, a deep learning framework to simultaneously segment (and classify) nuclei and (intra-)epithelial layers in H&E stained slides from OED cases. The proposed architecture consists of an encoder branch and four decoder branches for simultaneous instance segmentation of nuclei and semantic segmentation of the epithelial layers. We show that the proposed model achieves the state-of-the-art (SOTA) performance in both tasks, with no additional costs when compared to previous SOTA methods for each task. To the best of our knowledge, ours is the first method for simultaneous nuclear instance segmentation and semantic tissue segmentation, with potential for use in computational pathology for other similar simultaneous tasks and for future studies into malignancy prediction.
Robust Interactive Semantic Segmentation of Pathology Images with Minimal User Input
Aug 30, 2021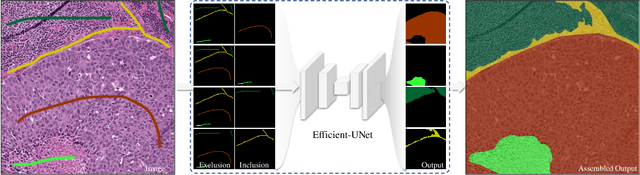

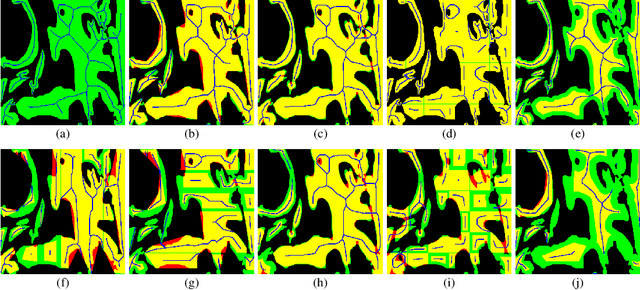
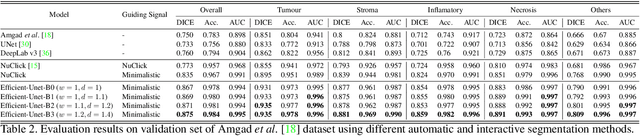
From the simple measurement of tissue attributes in pathology workflow to designing an explainable diagnostic/prognostic AI tool, access to accurate semantic segmentation of tissue regions in histology images is a prerequisite. However, delineating different tissue regions manually is a laborious, time-consuming and costly task that requires expert knowledge. On the other hand, the state-of-the-art automatic deep learning models for semantic segmentation require lots of annotated training data and there are only a limited number of tissue region annotated images publicly available. To obviate this issue in computational pathology projects and collect large-scale region annotations efficiently, we propose an efficient interactive segmentation network that requires minimum input from the user to accurately annotate different tissue types in the histology image. The user is only required to draw a simple squiggle inside each region of interest so it will be used as the guiding signal for the model. To deal with the complex appearance and amorph geometry of different tissue regions we introduce several automatic and minimalistic guiding signal generation techniques that help the model to become robust against the variation in the user input. By experimenting on a dataset of breast cancer images, we show that not only does our proposed method speed up the interactive annotation process, it can also outperform the existing automatic and interactive region segmentation models.
Lizard: A Large-Scale Dataset for Colonic Nuclear Instance Segmentation and Classification
Aug 25, 2021
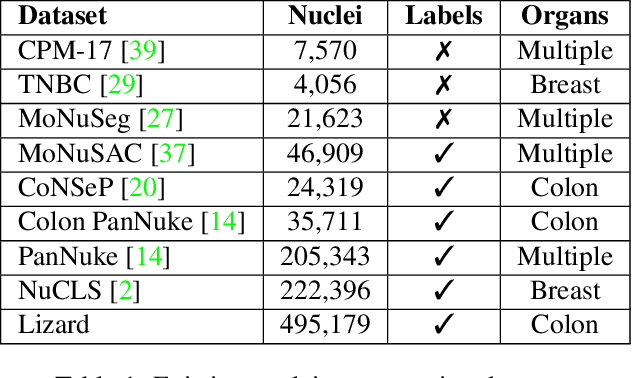
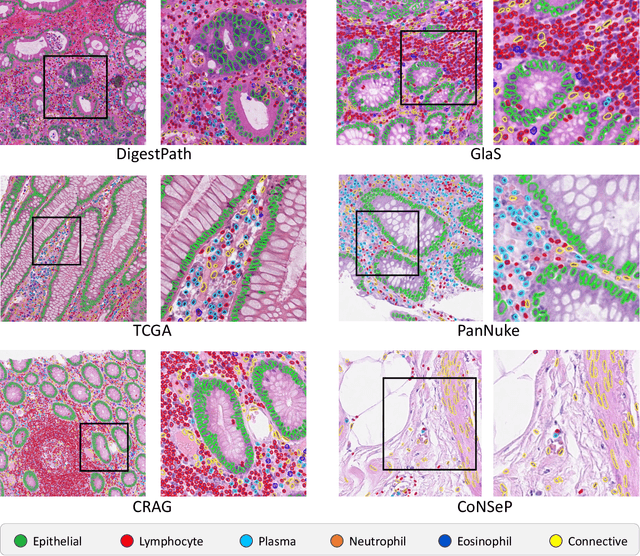
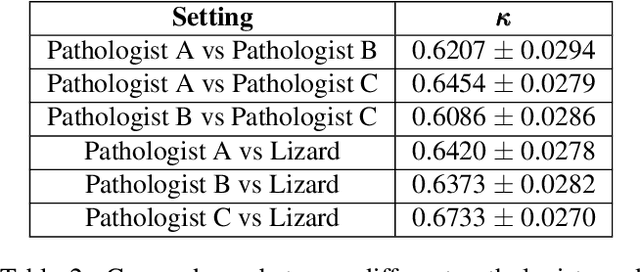
The development of deep segmentation models for computational pathology (CPath) can help foster the investigation of interpretable morphological biomarkers. Yet, there is a major bottleneck in the success of such approaches because supervised deep learning models require an abundance of accurately labelled data. This issue is exacerbated in the field of CPath because the generation of detailed annotations usually demands the input of a pathologist to be able to distinguish between different tissue constructs and nuclei. Manually labelling nuclei may not be a feasible approach for collecting large-scale annotated datasets, especially when a single image region can contain thousands of different cells. However, solely relying on automatic generation of annotations will limit the accuracy and reliability of ground truth. Therefore, to help overcome the above challenges, we propose a multi-stage annotation pipeline to enable the collection of large-scale datasets for histology image analysis, with pathologist-in-the-loop refinement steps. Using this pipeline, we generate the largest known nuclear instance segmentation and classification dataset, containing nearly half a million labelled nuclei in H&E stained colon tissue. We have released the dataset and encourage the research community to utilise it to drive forward the development of downstream cell-based models in CPath.