 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025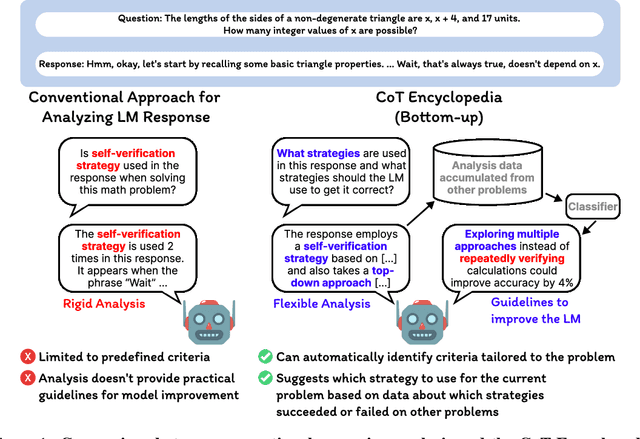
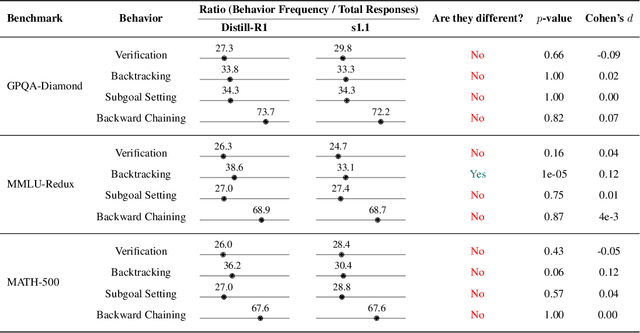
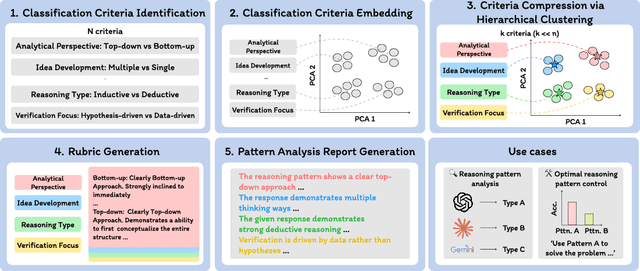

Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.
Process Reward Models That Think
Apr 23, 2025



Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models will be released at https://github.com/mukhal/thinkprm.
MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Apr 13, 2025



Existing evaluation of large language model (LLM) agents on scientific discovery lacks objective baselines and metrics to assess the viability of their proposed methods. To address this issue, we introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions. Our benchmark highlights open research problems that demand novel methodologies, in contrast to recent benchmarks such as OpenAI's MLE-Bench (Chan et al., 2024) and METR's RE-Bench (Wijk et al., 2024), which focus on well-established research tasks that are largely solvable through sufficient engineering effort. Unlike prior work, e.g., AI Scientist (Lu et al., 2024b), which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with newly proposed rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB (Huang et al., 2024a)) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and their actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, which is designed to continually grow with new ML competitions to encourage rigorous and objective evaluations of AI's research capabilities.
Automatically Evaluating the Paper Reviewing Capability of Large Language Models
Feb 24, 2025Peer review is essential for scientific progress, but it faces challenges such as reviewer shortages and growing workloads. Although Large Language Models (LLMs) show potential for providing assistance, research has reported significant limitations in the reviews they generate. While the insights are valuable, conducting the analysis is challenging due to the considerable time and effort required, especially given the rapid pace of LLM developments. To address the challenge, we developed an automatic evaluation pipeline to assess the LLMs' paper review capability by comparing them with expert-generated reviews. By constructing a dataset consisting of 676 OpenReview papers, we examined the agreement between LLMs and experts in their strength and weakness identifications. The results showed that LLMs lack balanced perspectives, significantly overlook novelty assessment when criticizing, and produce poor acceptance decisions. Our automated pipeline enables a scalable evaluation of LLMs' paper review capability over time.
HFI: A unified framework for training-free detection and implicit watermarking of latent diffusion model generated images
Dec 30, 2024Dramatic advances in the quality of the latent diffusion models (LDMs) also led to the malicious use of AI-generated images. While current AI-generated image detection methods assume the availability of real/AI-generated images for training, this is practically limited given the vast expressibility of LDMs. This motivates the training-free detection setup where no related data are available in advance. The existing LDM-generated image detection method assumes that images generated by LDM are easier to reconstruct using an autoencoder than real images. However, we observe that this reconstruction distance is overfitted to background information, leading the current method to underperform in detecting images with simple backgrounds. To address this, we propose a novel method called HFI. Specifically, by viewing the autoencoder of LDM as a downsampling-upsampling kernel, HFI measures the extent of aliasing, a distortion of high-frequency information that appears in the reconstructed image. HFI is training-free, efficient, and consistently outperforms other training-free methods in detecting challenging images generated by various generative models. We also show that HFI can successfully detect the images generated from the specified LDM as a means of implicit watermarking. HFI outperforms the best baseline method while achieving magnitudes of
SPRIG: Improving Large Language Model Performance by System Prompt Optimization
Oct 18, 2024Large Language Models (LLMs) have shown impressive capabilities in many scenarios, but their performance depends, in part, on the choice of prompt. Past research has focused on optimizing prompts specific to a task. However, much less attention has been given to optimizing the general instructions included in a prompt, known as a system prompt. To address this gap, we propose SPRIG, an edit-based genetic algorithm that iteratively constructs prompts from prespecified components to maximize the model's performance in general scenarios. We evaluate the performance of system prompts on a collection of 47 different types of tasks to ensure generalizability. Our study finds that a single optimized system prompt performs on par with task prompts optimized for each individual task. Moreover, combining system and task-level optimizations leads to further improvement, which showcases their complementary nature. Experiments also reveal that the optimized system prompts generalize effectively across model families, parameter sizes, and languages. This study provides insights into the role of system-level instructions in maximizing LLM potential.
Partial-Multivariate Model for Forecasting
Aug 19, 2024



When solving forecasting problems including multiple time-series features, existing approaches often fall into two extreme categories, depending on whether to utilize inter-feature information: univariate and complete-multivariate models. Unlike univariate cases which ignore the information, complete-multivariate models compute relationships among a complete set of features. However, despite the potential advantage of leveraging the additional information, complete-multivariate models sometimes underperform univariate ones. Therefore, our research aims to explore a middle ground between these two by introducing what we term Partial-Multivariate models where a neural network captures only partial relationships, that is, dependencies within subsets of all features. To this end, we propose PMformer, a Transformer-based partial-multivariate model, with its training algorithm. We demonstrate that PMformer outperforms various univariate and complete-multivariate models, providing a theoretical rationale and empirical analysis for its superiority. Additionally, by proposing an inference technique for PMformer, the forecasting accuracy is further enhanced. Finally, we highlight other advantages of PMformer: efficiency and robustness under missing features.
Towards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
Aug 13, 2024



Large Language Models (LLMs) have demonstrated strong reasoning and memorization capabilities via pretraining on massive textual corpora. However, training LLMs on human-written text entails significant risk of privacy and copyright violations, which demands an efficient machine unlearning framework to remove knowledge of sensitive data without retraining the model from scratch. While Gradient Ascent (GA) is widely used for unlearning by reducing the likelihood of generating unwanted information, the unboundedness of increasing the cross-entropy loss causes not only unstable optimization, but also catastrophic forgetting of knowledge that needs to be retained. We also discover its joint application under low-rank adaptation results in significantly suboptimal computational cost vs. generative performance trade-offs. In light of this limitation, we propose two novel techniques for robust and cost-efficient unlearning on LLMs. We first design an Inverted Hinge loss that suppresses unwanted tokens by increasing the probability of the next most likely token, thereby retaining fluency and structure in language generation. We also propose to initialize low-rank adapter weights based on Fisher-weighted low-rank approximation, which induces faster unlearning and better knowledge retention by allowing model updates to be focused on parameters that are important in generating textual data we wish to remove.
EXAONE 3.0 7.8B Instruction Tuned Language Model
Aug 07, 2024



We introduce EXAONE 3.0 instruction-tuned language model, the first open model in the family of Large Language Models (LLMs) developed by LG AI Research. Among different model sizes, we publicly release the 7.8B instruction-tuned model to promote open research and innovations. Through extensive evaluations across a wide range of public and in-house benchmarks, EXAONE 3.0 demonstrates highly competitive real-world performance with instruction-following capability against other state-of-the-art open models of similar size. Our comparative analysis shows that EXAONE 3.0 excels particularly in Korean, while achieving compelling performance across general tasks and complex reasoning. With its strong real-world effectiveness and bilingual proficiency, we hope that EXAONE keeps contributing to advancements in Expert AI. Our EXAONE 3.0 instruction-tuned model is available at https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
Semantic Skill Grounding for Embodied Instruction-Following in Cross-Domain Environments
Aug 02, 2024In embodied instruction-following (EIF), the integration of pretrained language models (LMs) as task planners emerges as a significant branch, where tasks are planned at the skill level by prompting LMs with pretrained skills and user instructions. However, grounding these pretrained skills in different domains remains challenging due to their intricate entanglement with the domain-specific knowledge. To address this challenge, we present a semantic skill grounding (SemGro) framework that leverages the hierarchical nature of semantic skills. SemGro recognizes the broad spectrum of these skills, ranging from short-horizon low-semantic skills that are universally applicable across domains to long-horizon rich-semantic skills that are highly specialized and tailored for particular domains. The framework employs an iterative skill decomposition approach, starting from the higher levels of semantic skill hierarchy and then moving downwards, so as to ground each planned skill to an executable level within the target domain. To do so, we use the reasoning capabilities of LMs for composing and decomposing semantic skills, as well as their multi-modal extension for assessing the skill feasibility in the target domain. Our experiments in the VirtualHome benchmark show the efficacy of SemGro in 300 cross-domain EIF scenarios.