 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regret Minimization Framework on Preference Learning in Large Language Models
Jun 08, 2026Reinforcement learning with verifiable rewards (RLVR) has enabled progress on reasoning-intensive tasks by relying on task-specific verifiers that provide automated correctness signals. However, many realistic language tasks are difficult to equip with reliable verifiers, motivating a growing reliance on reinforcement learning from human feedback (RLHF). In this setting, we argue that a closer examination of how human feedback should be interpreted is essential. We introduce Regret-based Preference Optimization $(\textbf{RePO})$, which reframes RLHF through $\textit{regret minimization}$ rather than reward maximization. Human preferences are often shaped by $\textit{prospective}$ anticipation of outcomes and $\textit{counterfactual}$ comparisons to alternative behaviors, rather than by immediate, outcome-independent utility. $\textbf{RePO}$ captures this structure by modeling preferences as behavior-conditioned assessments of relative suboptimality. Experiments on mathematical reasoning benchmarks and human preference datasets demonstrate consistent performance gains, indicating that $\textbf{RePO}$ is an effective and human-aligned approach for training large language models.
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
May 26, 2025As Large Language Models (LLMs) continue to advance and find applications across a growing number of fields, ensuring the safety of LLMs has become increasingly critical. To address safety concerns, recent studies have proposed integrating safety constraints into Reinforcement Learning from Human Feedback (RLHF). However, these approaches tend to be complex, as they encompass complicated procedures in RLHF along with additional steps required by the safety constraints. Inspired by Direct Preference Optimization (DPO), we introduce a new algorithm called SafeDPO, which is designed to directly optimize the safety alignment objective in a single stage of policy learning, without requiring relaxation. SafeDPO introduces only one additional hyperparameter to further enhance safety and requires only minor modifications to standard DPO. As a result, it eliminates the need to fit separate reward and cost models or to sample from the language model during fine-tuning, while still enhancing the safety of LLMs. Finally, we demonstrate that SafeDPO achieves competitive performance compared to state-of-the-art safety alignment algorithms, both in terms of aligning with human preferences and improving safety.
Semantic Skill Grounding for Embodied Instruction-Following in Cross-Domain Environments
Aug 02, 2024In embodied instruction-following (EIF), the integration of pretrained language models (LMs) as task planners emerges as a significant branch, where tasks are planned at the skill level by prompting LMs with pretrained skills and user instructions. However, grounding these pretrained skills in different domains remains challenging due to their intricate entanglement with the domain-specific knowledge. To address this challenge, we present a semantic skill grounding (SemGro) framework that leverages the hierarchical nature of semantic skills. SemGro recognizes the broad spectrum of these skills, ranging from short-horizon low-semantic skills that are universally applicable across domains to long-horizon rich-semantic skills that are highly specialized and tailored for particular domains. The framework employs an iterative skill decomposition approach, starting from the higher levels of semantic skill hierarchy and then moving downwards, so as to ground each planned skill to an executable level within the target domain. To do so, we use the reasoning capabilities of LMs for composing and decomposing semantic skills, as well as their multi-modal extension for assessing the skill feasibility in the target domain. Our experiments in the VirtualHome benchmark show the efficacy of SemGro in 300 cross-domain EIF scenarios.
Reinforcement Learning from Reflective Feedback (RLRF): Aligning and Improving LLMs via Fine-Grained Self-Reflection
Mar 21, 2024



Despite the promise of RLHF in aligning LLMs with human preferences, it often leads to superficial alignment, prioritizing stylistic changes over improving downstream performance of LLMs. Underspecified preferences could obscure directions to align the models. Lacking exploration restricts identification of desirable outputs to improve the models. To overcome these challenges, we propose a novel framework: Reinforcement Learning from Reflective Feedback (RLRF), which leverages fine-grained feedback based on detailed criteria to improve the core capabilities of LLMs. RLRF employs a self-reflection mechanism to systematically explore and refine LLM responses, then fine-tuning the models via a RL algorithm along with promising responses. Our experiments across Just-Eval, Factuality, and Mathematical Reasoning demonstrate the efficacy and transformative potential of RLRF beyond superficial surface-level adjustment.
LobsDICE: Offline Imitation Learning from Observation via Stationary Distribution Correction Estimation
Feb 28, 2022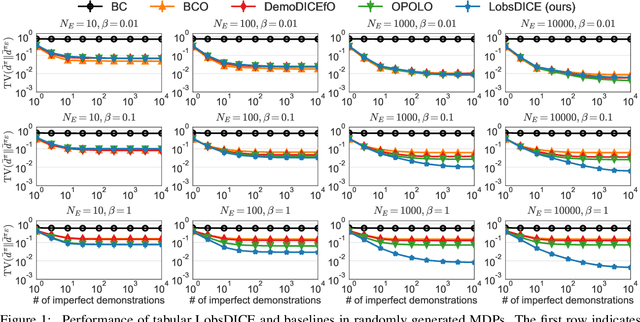
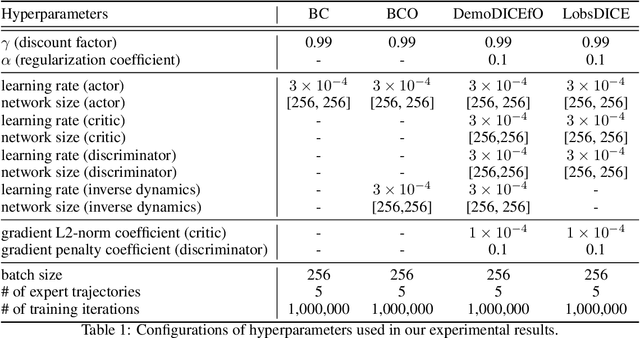
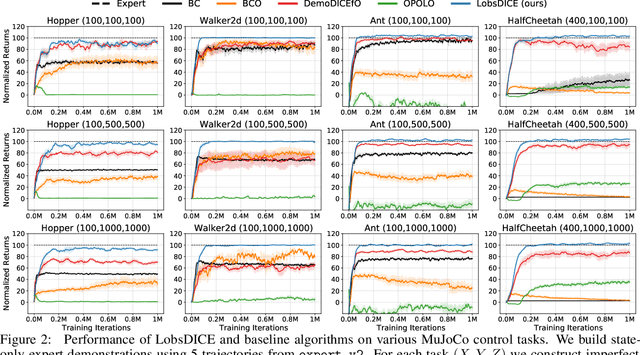
We consider the problem of imitation from observation (IfO), in which the agent aims to mimic the expert's behavior from the state-only demonstrations by experts. We additionally assume that the agent cannot interact with the environment but has access to the action-labeled transition data collected by some agent with unknown quality. This offline setting for IfO is appealing in many real-world scenarios where the ground-truth expert actions are inaccessible and the arbitrary environment interactions are costly or risky. In this paper, we present LobsDICE, an offline IfO algorithm that learns to imitate the expert policy via optimization in the space of stationary distributions. Our algorithm solves a single convex minimization problem, which minimizes the divergence between the two state-transition distributions induced by the expert and the agent policy. On an extensive set of offline IfO tasks, LobsDICE shows promising results, outperforming strong baseline algorithms.