 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOT-E: Test-Time Entropy Shaping with Visual Spotlights for Frozen VLMs
Jun 18, 2026Vision-language models (VLMs) often underperform on evidence intensive tasks because decisive visual evidence are small, localized, and easy to overlook, leading to failures in evidence readout even when high-level reasoning is intact. Prior inference-time visual interventions can improve grounding without retraining, but they are largely open-loop and lack a mechanism to verify whether highlighted evidence is actually used. We study answer-span prediction entropy as a model-internal feedback signal and show that naive entropy minimization is ambiguous, since low entropy may arise from evidence-grounded confidence or shortcut collapse. To resolve this ambiguity, we introduce low-entropy anchors and an entropy-shaping objective that reduces answer uncertainty while preserving baseline high-confidence tokens. We instantiate this principle in SPOT-E, a plug-and-play test-time method that produces question-conditioned spotlights, optimized per instance via light-weight tuning based on Group Relative Policy Optimization (GRPO). Across all benchmarks and different VLM families, SPOT-E yields consistent gains and improved robustness under visual corruptions. Code is publicly available at: \url{https://github.com/YinBo0927/SPOT-E}
SkillGraph: Self-Evolving Multi-Agent Collaboration with Multimodal Graph Topology
Apr 19, 2026Scaling vision-language models into Visual Multiagent Systems (VMAS) is hindered by two coupled issues. First, communication topologies are fixed before inference, leaving them blind to visual content and query context; second, agent reasoning abilities remain static during deployment. These issues reinforce each other: a rigid topology fails to leverage richer agent expertise, while static agents lack incentives to specialize for a given query. We address this with SkillGraph, a joint framework that evolves both agent expertise and communication topology. Within this framework, a Multimodal Graph Transformer (MMGT) encodes visual tokens, instruction semantics and active skill embeddings to predict a query-conditioned collaboration graph, replacing hand-crafted routing with dynamic, content-aware information flow. Complementing this, a Skill Designer distills and refines reasoning heuristics from failure cases, constructing a self-evolving multimodal Skill Bank. Crucially, updated skill embeddings are fed back into the MMGT, enabling the topology to adapt alongside capability growth. Experiments show that SkillGraph achieves consistent improvements across four benchmarks, five common MAS structures and four base models. Code is available at https://github.com/niez233/skillgraph.
Align and Surpass Human Camouflaged Perception: Visual Refocus Reinforcement Fine-Tuning
May 26, 2025



Current multi-modal models exhibit a notable misalignment with the human visual system when identifying objects that are visually assimilated into the background. Our observations reveal that these multi-modal models cannot distinguish concealed objects, demonstrating an inability to emulate human cognitive processes which effectively utilize foreground-background similarity principles for visual analysis. To analyze this hidden human-model visual thinking discrepancy, we build a visual system that mimicks human visual camouflaged perception to progressively and iteratively `refocus' visual concealed content. The refocus is a progressive guidance mechanism enabling models to logically localize objects in visual images through stepwise reasoning. The localization process of concealed objects requires hierarchical attention shifting with dynamic adjustment and refinement of prior cognitive knowledge. In this paper, we propose a visual refocus reinforcement framework via the policy optimization algorithm to encourage multi-modal models to think and refocus more before answering, and achieve excellent reasoning abilities to align and even surpass human camouflaged perception systems. Our extensive experiments on camouflaged perception successfully demonstrate the emergence of refocus visual phenomena, characterized by multiple reasoning tokens and dynamic adjustment of the detection box. Besides, experimental results on both camouflaged object classification and detection tasks exhibit significantly superior performance compared to Supervised Fine-Tuning (SFT) baselines.
deepregression: a Flexible Neural Network Framework for Semi-Structured Deep Distributional Regression
Apr 06, 2021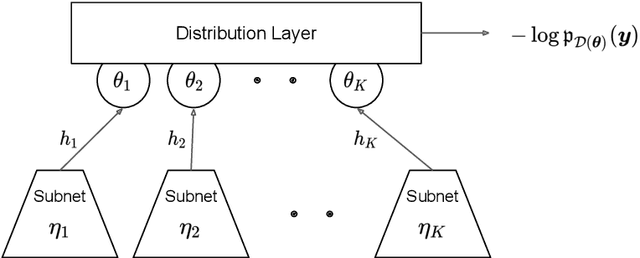
This paper describes the implementation of semi-structured deep distributional regression, a flexible framework to learn distributions based on a combination of additive regression models and deep neural networks. deepregression is implemented in both R and Python, using the deep learning libraries TensorFlow and PyTorch, respectively. The implementation consists of (1) a modular neural network building system for the combination of various statistical and deep learning approaches, (2) an orthogonalization cell to allow for an interpretable combination of different subnetworks as well as (3) pre-processing steps necessary to initialize such models. The software package allows to define models in a user-friendly manner using distribution definitions via a formula environment that is inspired by classical statistical model frameworks such as mgcv. The packages' modular design and functionality provides a unique resource for rapid and reproducible prototyping of complex statistical and deep learning models while simultaneously retaining the indispensable interpretability of classical statistical models.