 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHKVM-RAG: Key-Value-Separated Hypergraph Evidence Organization for Multi-Hop RAG
Jun 05, 2026Multi-hop RAG poses a data-engineering problem beyond passage matching: under fixed retrieval budgets, a system must organize retrieved text into evidence units that expose answer chains. Dense retrievers score passages independently, while graph-based memories make associations explicit but often rely on pairwise or entity-centered keys that fragment multi-hop evidence. We present HKVM-RAG, a key-value-separated evidence-organization layer. It assembles answer-path hyperedges from cached passage-level LLM evidence tuples and uses them as retrieval keys, while retaining passage text as answer values. To isolate key-space design, our fixed-substrate protocol holds the tuple cache, candidate passages, reader, and evaluation budget constant across pairwise graph and hypergraph variants. Weighted hypergraph key-value retrieval improves over KG-PPR by +3.426 F1 on 2WikiMultiHopQA and +3.592 F1 on MuSiQue; HotpotQA shows that higher structured support coverage need not yield standalone answer-F1 gains. We therefore study WHG-KV as an evidence-control signal rather than a dense-retrieval replacement. Oracle and train-to-dev analyses identify support selection as repairable, and a dense-aware controller combines frozen ColBERTv2 and HKVM rank/score features using out-of-fold HKVM predictions. It reaches 88.846, 65.073, and 85.810 F1 on the three benchmarks, improving over ColBERTv2 by +11.084, +6.763, and +5.966 F1. Source-level ablations show that matched non-WHG structured signals do not match the WHG-KV gains. These results provide bounded evidence that key-value-separated hypergraph organization can serve as a reusable evidence-control mechanism for multi-hop RAG.
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval
Apr 22, 2026The Composed Image Retrieval (CIR) task provides a flexible retrieval paradigm via a reference image and modification text, but it heavily relies on expensive and error-prone triplet annotations. This paper systematically investigates the Noisy Triplet Correspondence (NTC) problem introduced by annotations. We find that NTC noise, particularly ``hard noise'' (i.e., the reference and target images are highly similar but the modification text is incorrect), poses a unique challenge to existing Noise Correspondence Learning (NCL) methods because it breaks the traditional ``small loss hypothesis''. We identify and elucidate three key, yet overlooked, challenges in the NTC task, namely (C1) Modality Suppression, (C2) Negative Anchor Deficiency, and (C3) Unlearning Backlash. To address these challenges, we propose a Cone-based robuSt noisE-unlearning comPositional network (ConeSep). Specifically, we first propose Geometric Fidelity Quantization, theoretically establishing and practically estimating a noise boundary to precisely locate noisy correspondence. Next, we introduce Negative Boundary Learning, which learns a ``diagonal negative combination'' for each query as its explicit semantic opposite-anchor in the embedding space. Finally, we design Boundary-based Targeted Unlearning, which models the noisy correction process as an optimal transport problem, elegantly avoiding Unlearning Backlash. Extensive experiments on benchmark datasets (FashionIQ and CIRR) demonstrate that ConeSep significantly outperforms current state-of-the-art methods, which fully demonstrates the effectiveness and robustness of our method.
HINT: Composed Image Retrieval with Dual-path Compositional Contextualized Network
Mar 27, 2026Composed Image Retrieval (CIR) is a challenging image retrieval paradigm. It aims to retrieve target images from large-scale image databases that are consistent with the modification semantics, based on a multimodal query composed of a reference image and modification text. Although existing methods have made significant progress in cross-modal alignment and feature fusion, a key flaw remains: the neglect of contextual information in discriminating matching samples. However, addressing this limitation is not an easy task due to two challenges: 1) implicit dependencies and 2) the lack of a differential amplification mechanism. To address these challenges, we propose a dual-patH composItional coNtextualized neTwork (HINT), which can perform contextualized encoding and amplify the similarity differences between matching and non-matching samples, thus improving the upper performance of CIR models in complex scenarios. Our HINT model achieves optimal performance on all metrics across two CIR benchmark datasets, demonstrating the superiority of our HINT model. Codes are available at https://github.com/zh-mingyu/HINT.
The Great March 100: 100 Detail-oriented Tasks for Evaluating Embodied AI Agents
Jan 16, 2026Recently, with the rapid development of robot learning and imitation learning, numerous datasets and methods have emerged. However, these datasets and their task designs often lack systematic consideration and principles. This raises important questions: Do the current datasets and task designs truly advance the capabilities of robotic agents? Do evaluations on a few common tasks accurately reflect the differentiated performance of various methods proposed by different teams and evaluated on different tasks? To address these issues, we introduce the Great March 100 (\textbf{GM-100}) as the first step towards a robot learning Olympics. GM-100 consists of 100 carefully designed tasks that cover a wide range of interactions and long-tail behaviors, aiming to provide a diverse and challenging set of tasks to comprehensively evaluate the capabilities of robotic agents and promote diversity and complexity in robot dataset task designs. These tasks are developed through systematic analysis and expansion of existing task designs, combined with insights from human-object interaction primitives and object affordances. We collect a large amount of trajectory data on different robotic platforms and evaluate several baseline models. Experimental results demonstrate that the GM-100 tasks are 1) feasible to execute and 2) sufficiently challenging to effectively differentiate the performance of current VLA models. Our data and code are available at https://rhos.ai/research/gm-100.
IPR-1: Interactive Physical Reasoner
Nov 19, 2025Humans learn by observing, interacting with environments, and internalizing physics and causality. Here, we aim to ask whether an agent can similarly acquire human-like reasoning from interaction and keep improving with more experience. We study this in a Game-to-Unseen (G2U) setting, curating 1,000+ heterogeneous games with diverse physical and causal mechanisms, and evaluate at three human-like levels: Survival, Curiosity, Utility, from primitive intuition to goal-driven reasoning. Our analysis reveals complementary failures: VLM/VLA agents reason but lack look-ahead in interactive settings, while world models imagine but imitate visual patterns rather than analyze physics and causality. We therefore propose IPR (Interactive Physical Reasoner), using world-model rollouts to score and reinforce a VLM's policy, and introduce PhysCode, a physics-centric action code aligning semantic intent with dynamics to provide a shared action space for prediction and reasoning. Pretrained on 1,000+ games, our IPR performs robustly on three levels, matches GPT-5 overall, and surpasses it on Curiosity. We find that performance improves with more training games and interaction steps, and that the model also zero-shot transfers to unseen games. These results support physics-centric interaction as a path to steadily improving physical reasoning.
Take A Step Back: Rethinking the Two Stages in Visual Reasoning
Jul 29, 2024



Visual reasoning, as a prominent research area, plays a crucial role in AI by facilitating concept formation and interaction with the world. However, current works are usually carried out separately on small datasets thus lacking generalization ability. Through rigorous evaluation of diverse benchmarks, we demonstrate the shortcomings of existing ad-hoc methods in achieving cross-domain reasoning and their tendency to data bias fitting. In this paper, we revisit visual reasoning with a two-stage perspective: (1) symbolization and (2) logical reasoning given symbols or their representations. We find that the reasoning stage is better at generalization than symbolization. Thus, it is more efficient to implement symbolization via separated encoders for different data domains while using a shared reasoner. Given our findings, we establish design principles for visual reasoning frameworks following the separated symbolization and shared reasoning. The proposed two-stage framework achieves impressive generalization ability on various visual reasoning tasks, including puzzles, physical prediction, and visual question answering (VQA), encompassing both 2D and 3D modalities. We believe our insights will pave the way for generalizable visual reasoning.
STAR-GNN: Spatial-Temporal Video Representation for Content-based Retrieval
Aug 15, 2022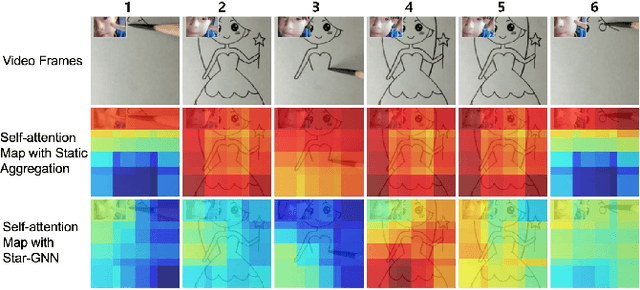
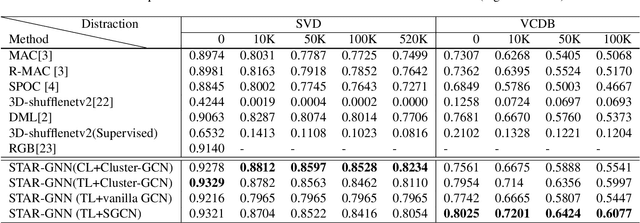
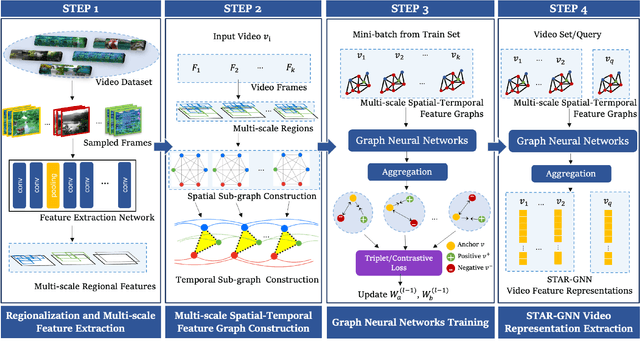
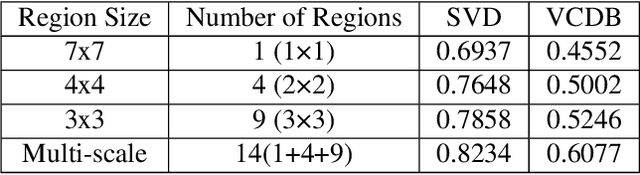
We propose a video feature representation learning framework called STAR-GNN, which applies a pluggable graph neural network component on a multi-scale lattice feature graph. The essence of STAR-GNN is to exploit both the temporal dynamics and spatial contents as well as visual connections between regions at different scales in the frames. It models a video with a lattice feature graph in which the nodes represent regions of different granularity, with weighted edges that represent the spatial and temporal links. The contextual nodes are aggregated simultaneously by graph neural networks with parameters trained with retrieval triplet loss. In the experiments, we show that STAR-GNN effectively implements a dynamic attention mechanism on video frame sequences, resulting in the emphasis for dynamic and semantically rich content in the video, and is robust to noise and redundancies. Empirical results show that STAR-GNN achieves state-of-the-art performance for Content-Based Video Retrieval.
InvisibiliTee: Angle-agnostic Cloaking from Person-Tracking Systems with a Tee
Aug 15, 2022
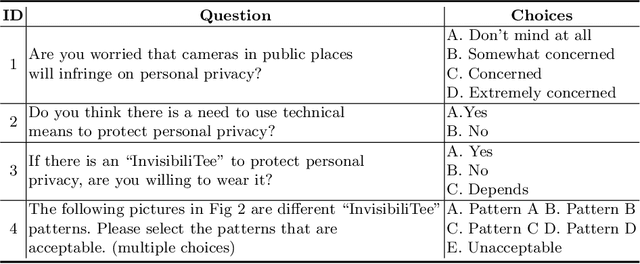


After a survey for person-tracking system-induced privacy concerns, we propose a black-box adversarial attack method on state-of-the-art human detection models called InvisibiliTee. The method learns printable adversarial patterns for T-shirts that cloak wearers in the physical world in front of person-tracking systems. We design an angle-agnostic learning scheme which utilizes segmentation of the fashion dataset and a geometric warping process so the adversarial patterns generated are effective in fooling person detectors from all camera angles and for unseen black-box detection models. Empirical results in both digital and physical environments show that with the InvisibiliTee on, person-tracking systems' ability to detect the wearer drops significantly.
Modality-Balanced Embedding for Video Retrieval
Apr 18, 2022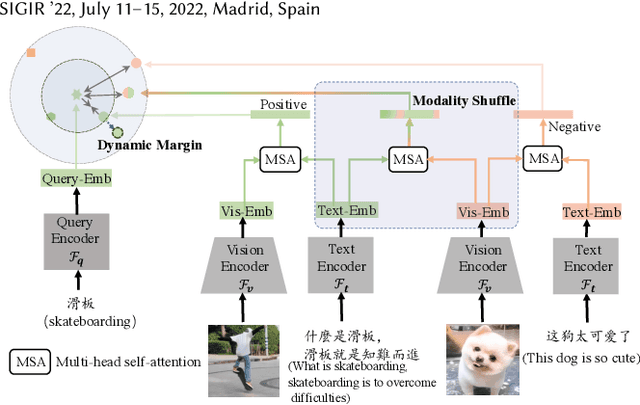
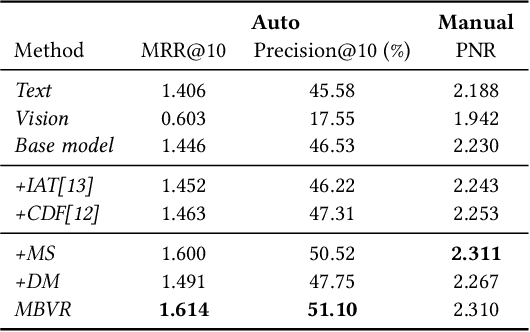
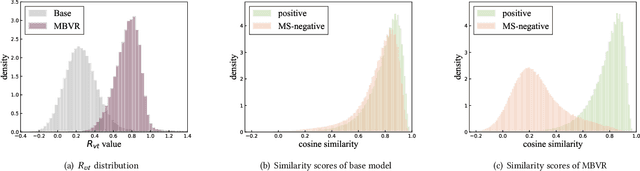
Video search has become the main routine for users to discover videos relevant to a text query on large short-video sharing platforms. During training a query-video bi-encoder model using online search logs, we identify a modality bias phenomenon that the video encoder almost entirely relies on text matching, neglecting other modalities of the videos such as vision, audio. This modality imbalanceresults from a) modality gap: the relevance between a query and a video text is much easier to learn as the query is also a piece of text, with the same modality as the video text; b) data bias: most training samples can be solved solely by text matching. Here we share our practices to improve the first retrieval stage including our solution for the modality imbalance issue. We propose MBVR (short for Modality Balanced Video Retrieval) with two key components: manually generated modality-shuffled (MS) samples and a dynamic margin (DM) based on visual relevance. They can encourage the video encoder to pay balanced attentions to each modality. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving modality bias problem. We have also deployed our MBVR in a large video platform and observed statistically significant boost over a highly optimized baseline in an A/B test and manual GSB evaluations.
* Accepted by SIGIR-2022, short paper
Unsupervised Adversarial Attacks on Deep Feature-based Retrieval with GAN
Jul 12, 2019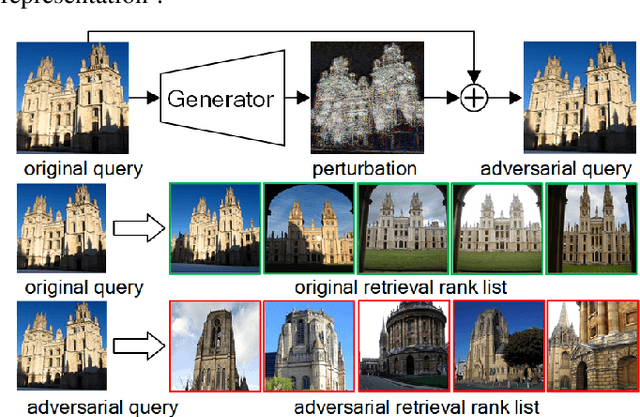
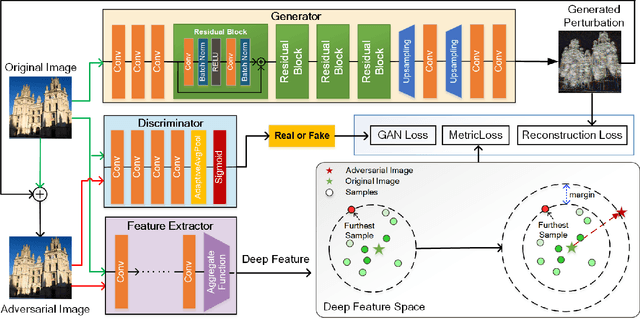
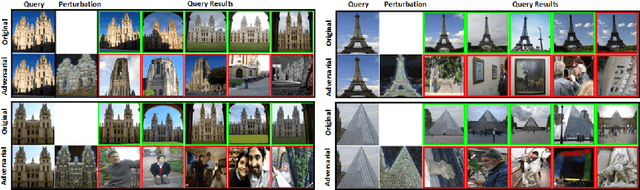

Studies show that Deep Neural Network (DNN)-based image classification models are vulnerable to maliciously constructed adversarial examples. However, little effort has been made to investigate how DNN-based image retrieval models are affected by such attacks. In this paper, we introduce Unsupervised Adversarial Attacks with Generative Adversarial Networks (UAA-GAN) to attack deep feature-based image retrieval systems. UAA-GAN is an unsupervised learning model that requires only a small amount of unlabeled data for training. Once trained, it produces query-specific perturbations for query images to form adversarial queries. The core idea is to ensure that the attached perturbation is barely perceptible to human yet effective in pushing the query away from its original position in the deep feature space. UAA-GAN works with various application scenarios that are based on deep features, including image retrieval, person Re-ID and face search. Empirical results show that UAA-GAN cripples retrieval performance without significant visual changes in the query images. UAA-GAN generated adversarial examples are less distinguishable because they tend to incorporate subtle perturbations in textured or salient areas of the images, such as key body parts of human, dominant structural patterns/textures or edges, rather than in visually insignificant areas (e.g., background and sky). Such tendency indicates that the model indeed learned how to toy with both image retrieval systems and human eyes.