 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSPA: Human Motion Generation Driven by Spatial Audio
Jul 16, 2025Enabling virtual humans to dynamically and realistically respond to diverse auditory stimuli remains a key challenge in character animation, demanding the integration of perceptual modeling and motion synthesis. Despite its significance, this task remains largely unexplored. Most previous works have primarily focused on mapping modalities like speech, audio, and music to generate human motion. As of yet, these models typically overlook the impact of spatial features encoded in spatial audio signals on human motion. To bridge this gap and enable high-quality modeling of human movements in response to spatial audio, we introduce the first comprehensive Spatial Audio-Driven Human Motion (SAM) dataset, which contains diverse and high-quality spatial audio and motion data. For benchmarking, we develop a simple yet effective diffusion-based generative framework for human MOtion generation driven by SPatial Audio, termed MOSPA, which faithfully captures the relationship between body motion and spatial audio through an effective fusion mechanism. Once trained, MOSPA could generate diverse realistic human motions conditioned on varying spatial audio inputs. We perform a thorough investigation of the proposed dataset and conduct extensive experiments for benchmarking, where our method achieves state-of-the-art performance on this task. Our model and dataset will be open-sourced upon acceptance. Please refer to our supplementary video for more details.
Zero-Shot Human-Object Interaction Synthesis with Multimodal Priors
Mar 25, 2025Human-object interaction (HOI) synthesis is important for various applications, ranging from virtual reality to robotics. However, acquiring 3D HOI data is challenging due to its complexity and high cost, limiting existing methods to the narrow diversity of object types and interaction patterns in training datasets. This paper proposes a novel zero-shot HOI synthesis framework without relying on end-to-end training on currently limited 3D HOI datasets. The core idea of our method lies in leveraging extensive HOI knowledge from pre-trained Multimodal Models. Given a text description, our system first obtains temporally consistent 2D HOI image sequences using image or video generation models, which are then uplifted to 3D HOI milestones of human and object poses. We employ pre-trained human pose estimation models to extract human poses and introduce a generalizable category-level 6-DoF estimation method to obtain the object poses from 2D HOI images. Our estimation method is adaptive to various object templates obtained from text-to-3D models or online retrieval. A physics-based tracking of the 3D HOI kinematic milestone is further applied to refine both body motions and object poses, yielding more physically plausible HOI generation results. The experimental results demonstrate that our method is capable of generating open-vocabulary HOIs with physical realism and semantic diversity.
It Takes Two: Real-time Co-Speech Two-person's Interaction Generation via Reactive Auto-regressive Diffusion Model
Dec 03, 2024



Conversational scenarios are very common in real-world settings, yet existing co-speech motion synthesis approaches often fall short in these contexts, where one person's audio and gestures will influence the other's responses. Additionally, most existing methods rely on offline sequence-to-sequence frameworks, which are unsuitable for online applications. In this work, we introduce an audio-driven, auto-regressive system designed to synthesize dynamic movements for two characters during a conversation. At the core of our approach is a diffusion-based full-body motion synthesis model, which is conditioned on the past states of both characters, speech audio, and a task-oriented motion trajectory input, allowing for flexible spatial control. To enhance the model's ability to learn diverse interactions, we have enriched existing two-person conversational motion datasets with more dynamic and interactive motions. We evaluate our system through multiple experiments to show it outperforms across a variety of tasks, including single and two-person co-speech motion generation, as well as interactive motion generation. To the best of our knowledge, this is the first system capable of generating interactive full-body motions for two characters from speech in an online manner.
InterAct: Capture and Modelling of Realistic, Expressive and Interactive Activities between Two Persons in Daily Scenarios
May 19, 2024



We address the problem of accurate capture and expressive modelling of interactive behaviors happening between two persons in daily scenarios. Different from previous works which either only consider one person or focus on conversational gestures, we propose to simultaneously model the activities of two persons, and target objective-driven, dynamic, and coherent interactions which often span long duration. To this end, we capture a new dataset dubbed InterAct, which is composed of 241 motion sequences where two persons perform a realistic scenario over the whole sequence. The audios, body motions, and facial expressions of both persons are all captured in our dataset. We also demonstrate the first diffusion model based approach that directly estimates the interactive motions between two persons from their audios alone. All the data and code will be available for research purposes upon acceptance of the paper.
Taming Diffusion Probabilistic Models for Character Control
Apr 23, 2024



We present a novel character control framework that effectively utilizes motion diffusion probabilistic models to generate high-quality and diverse character animations, responding in real-time to a variety of dynamic user-supplied control signals. At the heart of our method lies a transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM), which takes as input the character's historical motion and can generate a range of diverse potential future motions conditioned on high-level, coarse user control. To meet the demands for diversity, controllability, and computational efficiency required by a real-time controller, we incorporate several key algorithmic designs. These include separate condition tokenization, classifier-free guidance on past motion, and heuristic future trajectory extension, all designed to address the challenges associated with taming motion diffusion probabilistic models for character control. As a result, our work represents the first model that enables real-time generation of high-quality, diverse character animations based on user interactive control, supporting animating the character in multiple styles with a single unified model. We evaluate our method on a diverse set of locomotion skills, demonstrating the merits of our method over existing character controllers. Project page and source codes: https://aiganimation.github.io/CAMDM/
MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency
Jun 22, 2020
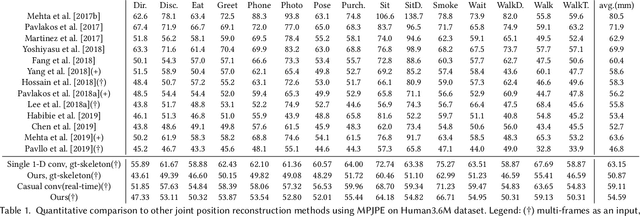

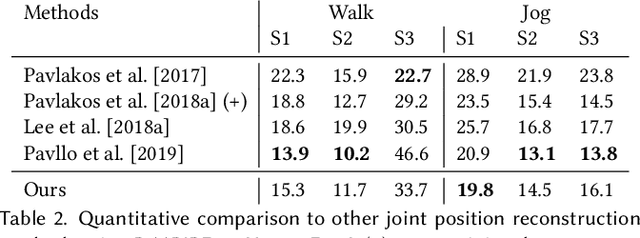
We introduce MotioNet, a deep neural network that directly reconstructs the motion of a 3D human skeleton from monocular video.While previous methods rely on either rigging or inverse kinematics (IK) to associate a consistent skeleton with temporally coherent joint rotations, our method is the first data-driven approach that directly outputs a kinematic skeleton, which is a complete, commonly used, motion representation. At the crux of our approach lies a deep neural network with embedded kinematic priors, which decomposes sequences of 2D joint positions into two separate attributes: a single, symmetric, skeleton, encoded by bone lengths, and a sequence of 3D joint rotations associated with global root positions and foot contact labels. These attributes are fed into an integrated forward kinematics (FK) layer that outputs 3D positions, which are compared to a ground truth. In addition, an adversarial loss is applied to the velocities of the recovered rotations, to ensure that they lie on the manifold of natural joint rotations. The key advantage of our approach is that it learns to infer natural joint rotations directly from the training data, rather than assuming an underlying model, or inferring them from joint positions using a data-agnostic IK solver. We show that enforcing a single consistent skeleton along with temporally coherent joint rotations constrains the solution space, leading to a more robust handling of self-occlusions and depth ambiguities.
Deep Video-Based Performance Cloning
Aug 21, 2018
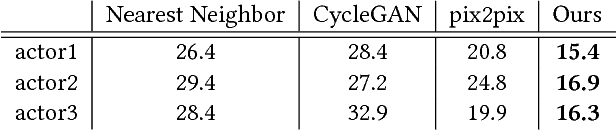
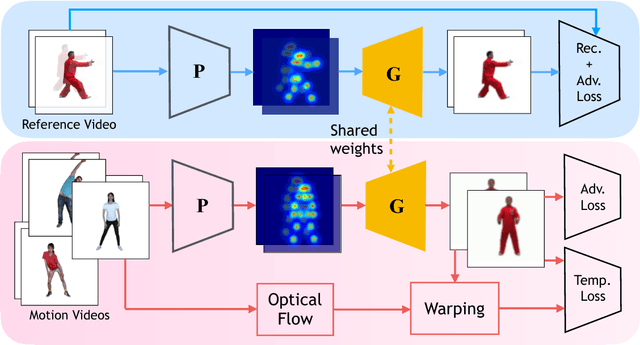

We present a new video-based performance cloning technique. After training a deep generative network using a reference video capturing the appearance and dynamics of a target actor, we are able to generate videos where this actor reenacts other performances. All of the training data and the driving performances are provided as ordinary video segments, without motion capture or depth information. Our generative model is realized as a deep neural network with two branches, both of which train the same space-time conditional generator, using shared weights. One branch, responsible for learning to generate the appearance of the target actor in various poses, uses \emph{paired} training data, self-generated from the reference video. The second branch uses unpaired data to improve generation of temporally coherent video renditions of unseen pose sequences. We demonstrate a variety of promising results, where our method is able to generate temporally coherent videos, for challenging scenarios where the reference and driving videos consist of very different dance performances. Supplementary video: https://youtu.be/JpwsEeqNhhA.
Neural Best-Buddies: Sparse Cross-Domain Correspondence
Aug 21, 2018
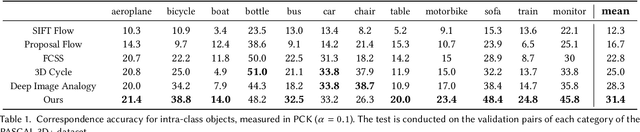
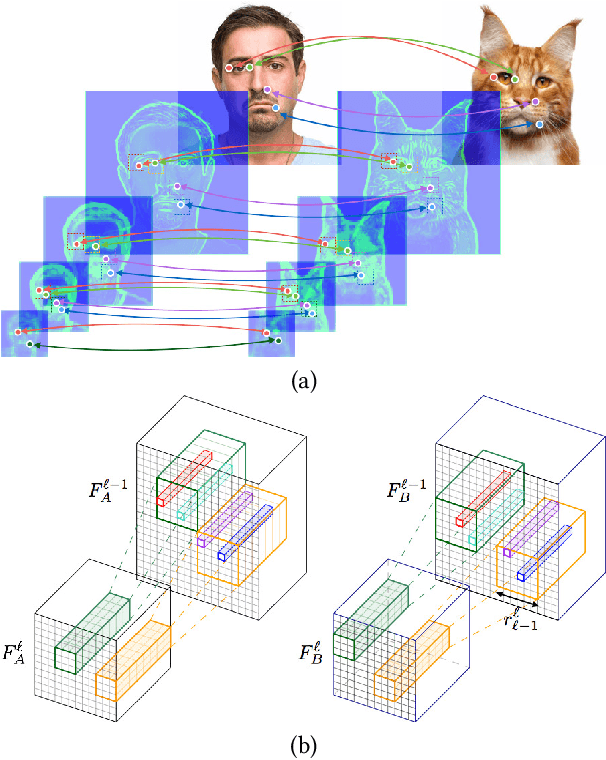
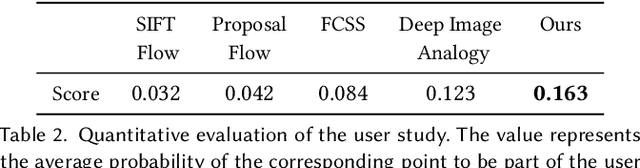
Correspondence between images is a fundamental problem in computer vision, with a variety of graphics applications. This paper presents a novel method for sparse cross-domain correspondence. Our method is designed for pairs of images where the main objects of interest may belong to different semantic categories and differ drastically in shape and appearance, yet still contain semantically related or geometrically similar parts. Our approach operates on hierarchies of deep features, extracted from the input images by a pre-trained CNN. Specifically, starting from the coarsest layer in both hierarchies, we search for Neural Best Buddies (NBB): pairs of neurons that are mutual nearest neighbors. The key idea is then to percolate NBBs through the hierarchy, while narrowing down the search regions at each level and retaining only NBBs with significant activations. Furthermore, in order to overcome differences in appearance, each pair of search regions is transformed into a common appearance. We evaluate our method via a user study, in addition to comparisons with alternative correspondence approaches. The usefulness of our method is demonstrated using a variety of graphics applications, including cross-domain image alignment, creation of hybrid images, automatic image morphing, and more.