 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Yu Liu
Superpixel Sampling Networks
Jul 26, 2018
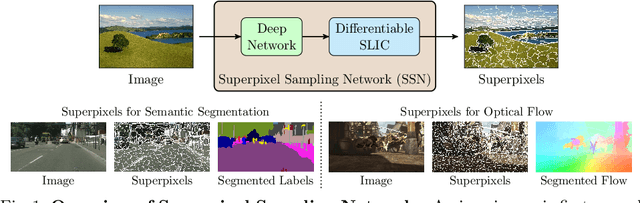
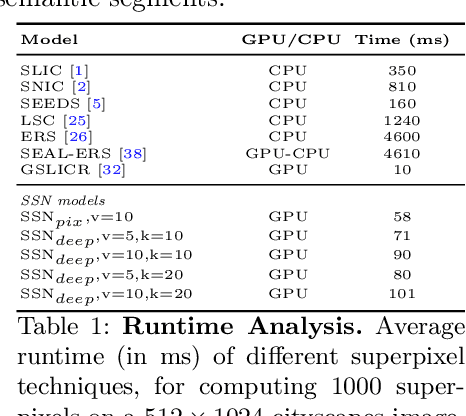

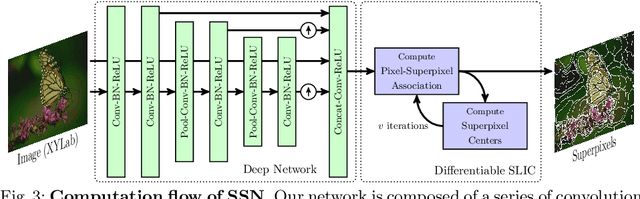
Superpixels provide an efficient low/mid-level representation of image data, which greatly reduces the number of image primitives for subsequent vision tasks. Existing superpixel algorithms are not differentiable, making them difficult to integrate into otherwise end-to-end trainable deep neural networks. We develop a new differentiable model for superpixel sampling that leverages deep networks for learning superpixel segmentation. The resulting "Superpixel Sampling Network" (SSN) is end-to-end trainable, which allows learning task-specific superpixels with flexible loss functions and has fast runtime. Extensive experimental analysis indicates that SSNs not only outperform existing superpixel algorithms on traditional segmentation benchmarks, but can also learn superpixels for other tasks. In addition, SSNs can be easily integrated into downstream deep networks resulting in performance improvements.
Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation
Jul 24, 2018
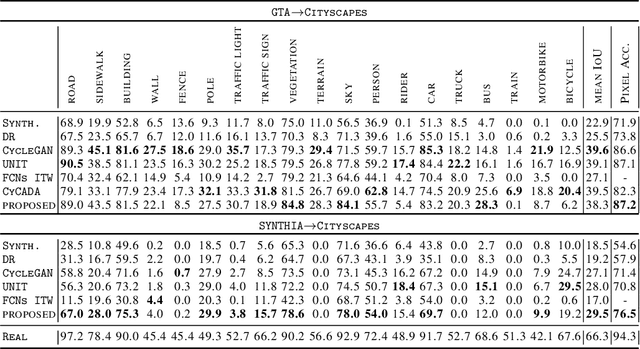

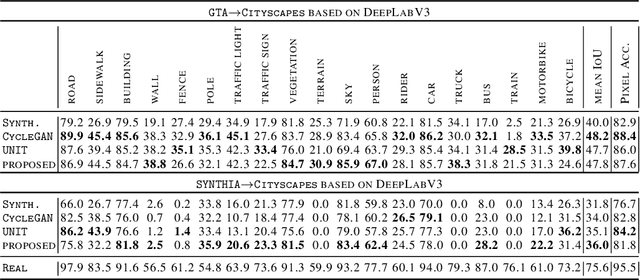
Deep neural networks have largely failed to effectively utilize synthetic data when applied to real images due to the covariate shift problem. In this paper, we show that by applying a straightforward modification to an existing photorealistic style transfer algorithm, we achieve state-of-the-art synthetic-to-real domain adaptation results. We conduct extensive experimental validations on four synthetic-to-real tasks for semantic segmentation and object detection, and show that our approach exceeds the performance of any current state-of-the-art GAN-based image translation approach as measured by segmentation and object detection metrics. Furthermore we offer a distance based analysis of our method which shows a dramatic reduction in Frechet Inception distance between the source and target domains, offering a quantitative metric that demonstrates the effectiveness of our algorithm in bridging the synthetic-to-real gap.
Unsupervised Image-to-Image Translation Networks
Jul 23, 2018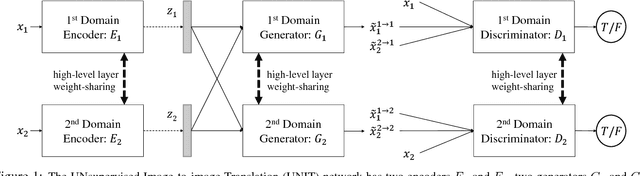


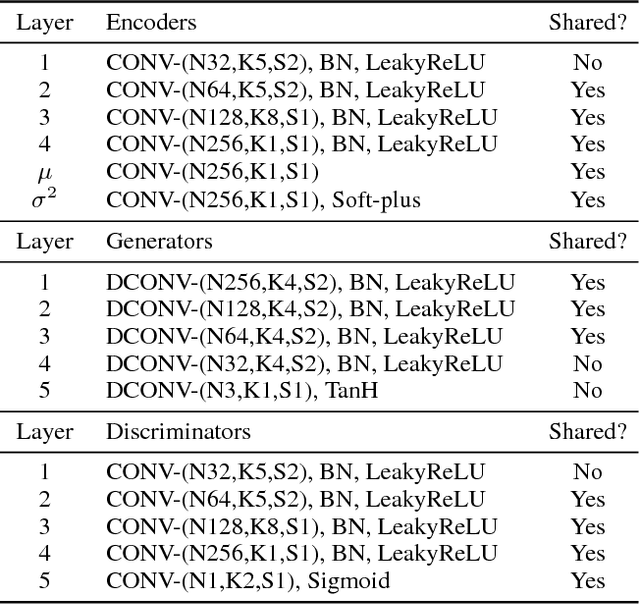
Unsupervised image-to-image translation aims at learning a joint distribution of images in different domains by using images from the marginal distributions in individual domains. Since there exists an infinite set of joint distributions that can arrive the given marginal distributions, one could infer nothing about the joint distribution from the marginal distributions without additional assumptions. To address the problem, we make a shared-latent space assumption and propose an unsupervised image-to-image translation framework based on Coupled GANs. We compare the proposed framework with competing approaches and present high quality image translation results on various challenging unsupervised image translation tasks, including street scene image translation, animal image translation, and face image translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on benchmark datasets. Code and additional results are available in https://github.com/mingyuliutw/unit .
PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume
Jun 25, 2018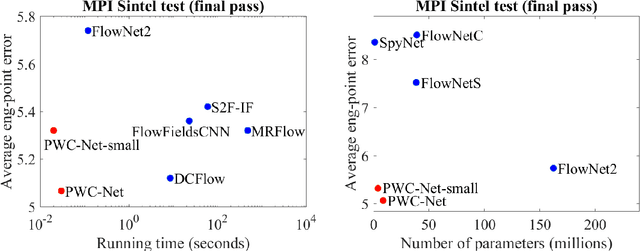
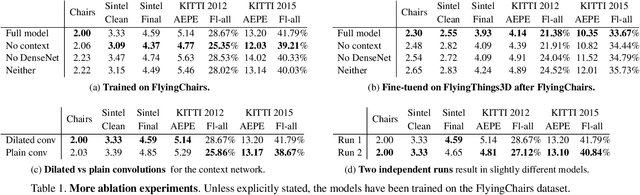


We present a compact but effective CNN model for optical flow, called PWC-Net. PWC-Net has been designed according to simple and well-established principles: pyramidal processing, warping, and the use of a cost volume. Cast in a learnable feature pyramid, PWC-Net uses the cur- rent optical flow estimate to warp the CNN features of the second image. It then uses the warped features and features of the first image to construct a cost volume, which is processed by a CNN to estimate the optical flow. PWC-Net is 17 times smaller in size and easier to train than the recent FlowNet2 model. Moreover, it outperforms all published optical flow methods on the MPI Sintel final pass and KITTI 2015 benchmarks, running at about 35 fps on Sintel resolution (1024x436) images. Our models are available on https://github.com/NVlabs/PWC-Net.
Localization-Aware Active Learning for Object Detection
Jan 16, 2018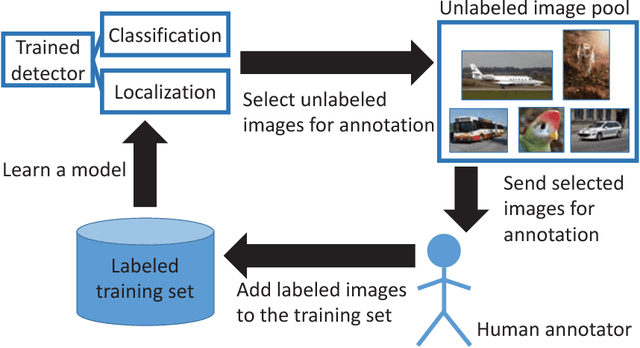
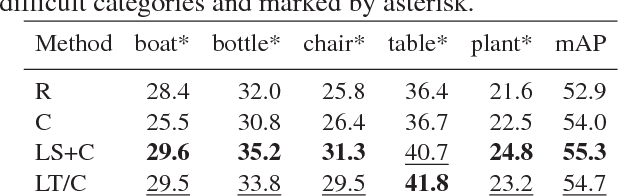

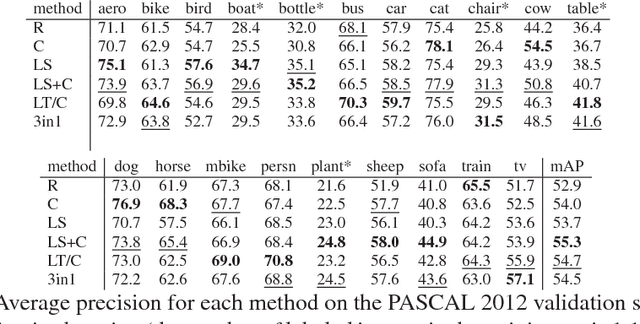
Active learning - a class of algorithms that iteratively searches for the most informative samples to include in a training dataset - has been shown to be effective at annotating data for image classification. However, the use of active learning for object detection is still largely unexplored as determining informativeness of an object-location hypothesis is more difficult. In this paper, we address this issue and present two metrics for measuring the informativeness of an object hypothesis, which allow us to leverage active learning to reduce the amount of annotated data needed to achieve a target object detection performance. Our first metric measures 'localization tightness' of an object hypothesis, which is based on the overlapping ratio between the region proposal and the final prediction. Our second metric measures 'localization stability' of an object hypothesis, which is based on the variation of predicted object locations when input images are corrupted by noise. Our experimental results show that by augmenting a conventional active-learning algorithm designed for classification with the proposed metrics, the amount of labeled training data required can be reduced up to 25%. Moreover, on PASCAL 2007 and 2012 datasets our localization-stability method has an average relative improvement of 96.5% and 81.9% over the baseline method using classification only.
Reblur2Deblur: Deblurring Videos via Self-Supervised Learning
Jan 16, 2018
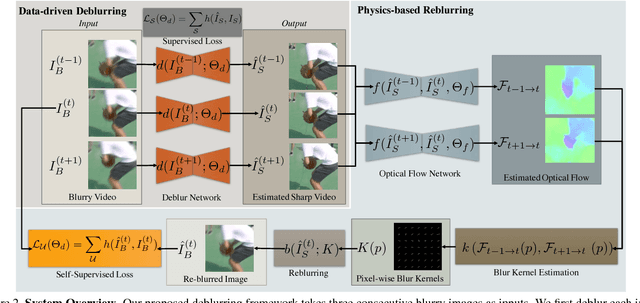

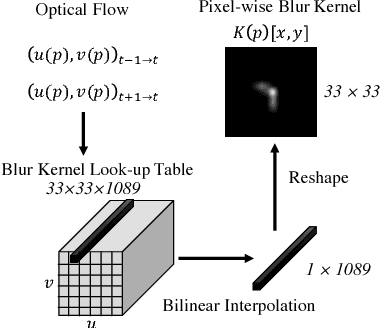
Motion blur is a fundamental problem in computer vision as it impacts image quality and hinders inference. Traditional deblurring algorithms leverage the physics of the image formation model and use hand-crafted priors: they usually produce results that better reflect the underlying scene, but present artifacts. Recent learning-based methods implicitly extract the distribution of natural images directly from the data and use it to synthesize plausible images. Their results are impressive, but they are not always faithful to the content of the latent image. We present an approach that bridges the two. Our method fine-tunes existing deblurring neural networks in a self-supervised fashion by enforcing that the output, when blurred based on the optical flow between subsequent frames, matches the input blurry image. We show that our method significantly improves the performance of existing methods on several datasets both visually and in terms of image quality metrics. The supplementary material is https://goo.gl/nYPjEQ
Learning Binary Residual Representations for Domain-specific Video Streaming
Dec 14, 2017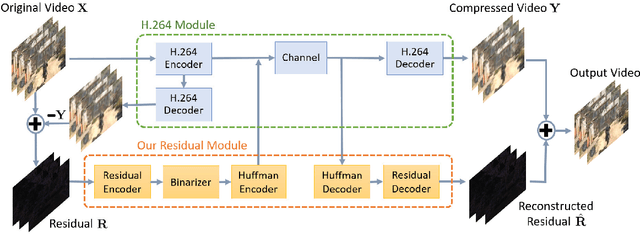
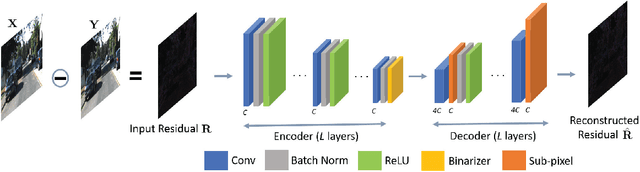

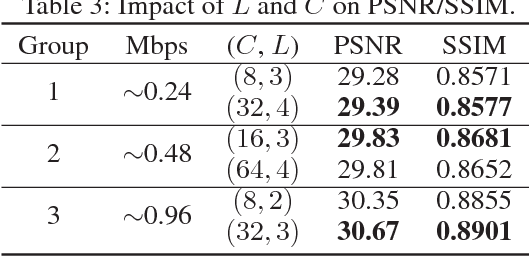
We study domain-specific video streaming. Specifically, we target a streaming setting where the videos to be streamed from a server to a client are all in the same domain and they have to be compressed to a small size for low-latency transmission. Several popular video streaming services, such as the video game streaming services of GeForce Now and Twitch, fall in this category. While conventional video compression standards such as H.264 are commonly used for this task, we hypothesize that one can leverage the property that the videos are all in the same domain to achieve better video quality. Based on this hypothesis, we propose a novel video compression pipeline. Specifically, we first apply H.264 to compress domain-specific videos. We then train a novel binary autoencoder to encode the leftover domain-specific residual information frame-by-frame into binary representations. These binary representations are then compressed and sent to the client together with the H.264 stream. In our experiments, we show that our pipeline yields consistent gains over standard H.264 compression across several benchmark datasets while using the same channel bandwidth.
MoCoGAN: Decomposing Motion and Content for Video Generation
Dec 14, 2017
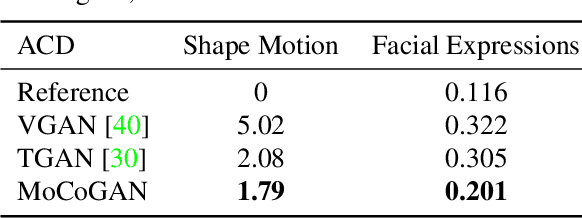
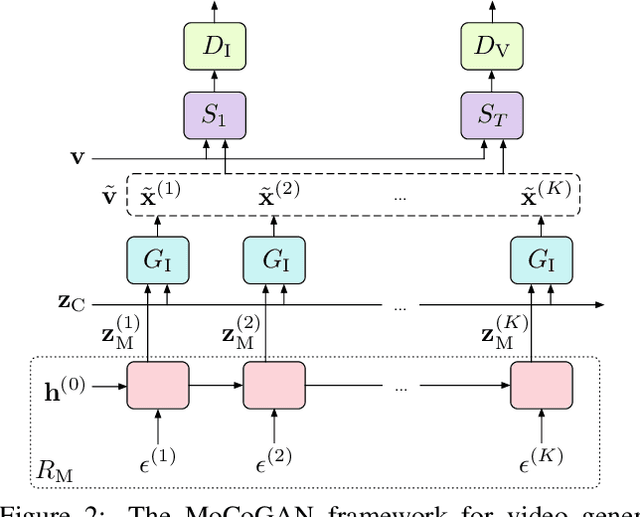

Visual signals in a video can be divided into content and motion. While content specifies which objects are in the video, motion describes their dynamics. Based on this prior, we propose the Motion and Content decomposed Generative Adversarial Network (MoCoGAN) framework for video generation. The proposed framework generates a video by mapping a sequence of random vectors to a sequence of video frames. Each random vector consists of a content part and a motion part. While the content part is kept fixed, the motion part is realized as a stochastic process. To learn motion and content decomposition in an unsupervised manner, we introduce a novel adversarial learning scheme utilizing both image and video discriminators. Extensive experimental results on several challenging datasets with qualitative and quantitative comparison to the state-of-the-art approaches, verify effectiveness of the proposed framework. In addition, we show that MoCoGAN allows one to generate videos with same content but different motion as well as videos with different content and same motion.
Detecting Adversarial Attacks on Neural Network Policies with Visual Foresight
Oct 02, 2017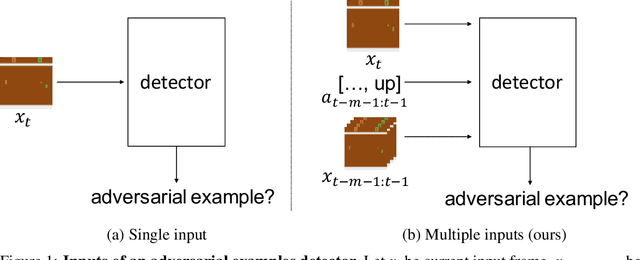
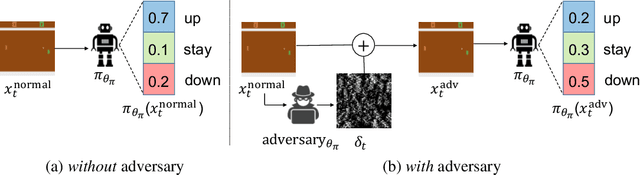
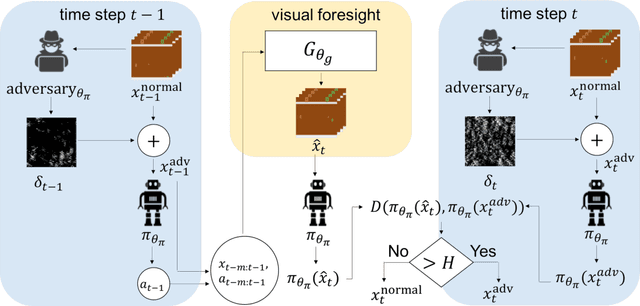
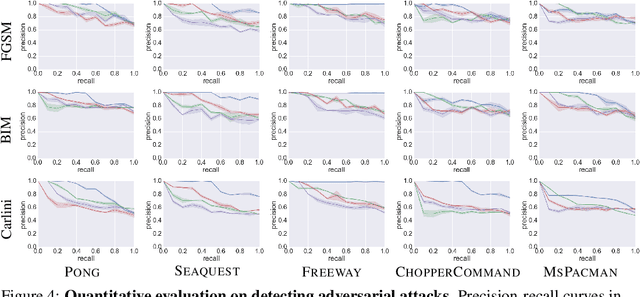
Deep reinforcement learning has shown promising results in learning control policies for complex sequential decision-making tasks. However, these neural network-based policies are known to be vulnerable to adversarial examples. This vulnerability poses a potentially serious threat to safety-critical systems such as autonomous vehicles. In this paper, we propose a defense mechanism to defend reinforcement learning agents from adversarial attacks by leveraging an action-conditioned frame prediction module. Our core idea is that the adversarial examples targeting at a neural network-based policy are not effective for the frame prediction model. By comparing the action distribution produced by a policy from processing the current observed frame to the action distribution produced by the same policy from processing the predicted frame from the action-conditioned frame prediction module, we can detect the presence of adversarial examples. Beyond detecting the presence of adversarial examples, our method allows the agent to continue performing the task using the predicted frame when the agent is under attack. We evaluate the performance of our algorithm using five games in Atari 2600. Our results demonstrate that the proposed defense mechanism achieves favorable performance against baseline algorithms in detecting adversarial examples and in earning rewards when the agents are under attack.
CASENet: Deep Category-Aware Semantic Edge Detection
May 27, 2017
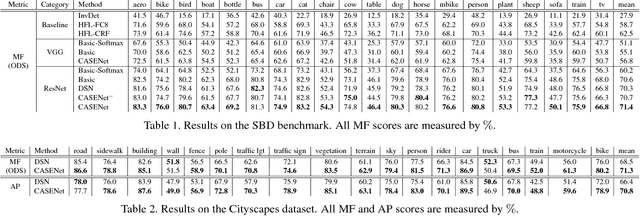

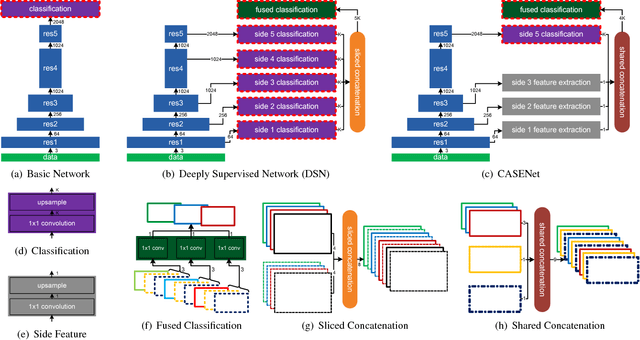
Boundary and edge cues are highly beneficial in improving a wide variety of vision tasks such as semantic segmentation, object recognition, stereo, and object proposal generation. Recently, the problem of edge detection has been revisited and significant progress has been made with deep learning. While classical edge detection is a challenging binary problem in itself, the category-aware semantic edge detection by nature is an even more challenging multi-label problem. We model the problem such that each edge pixel can be associated with more than one class as they appear in contours or junctions belonging to two or more semantic classes. To this end, we propose a novel end-to-end deep semantic edge learning architecture based on ResNet and a new skip-layer architecture where category-wise edge activations at the top convolution layer share and are fused with the same set of bottom layer features. We then propose a multi-label loss function to supervise the fused activations. We show that our proposed architecture benefits this problem with better performance, and we outperform the current state-of-the-art semantic edge detection methods by a large margin on standard data sets such as SBD and Cityscapes.