 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWild-Places: A Large-Scale Dataset for Lidar Place Recognition in Unstructured Natural Environments
Nov 29, 2022Many existing datasets for lidar place recognition are solely representative of structured urban environments, and have recently been saturated in performance by deep learning based approaches. Natural and unstructured environments present many additional challenges for the tasks of long-term localisation but these environments are not represented in currently available datasets. To address this we introduce Wild-Places, a challenging large-scale dataset for lidar place recognition in unstructured, natural environments. Wild-Places contains eight lidar sequences collected with a handheld sensor payload over the course of fourteen months, containing a total of 67K undistorted lidar submaps along with accurate 6DoF ground truth. Our dataset contains multiple revisits both within and between sequences, allowing for both intra-sequence (i.e. loop closure detection) and inter-sequence (i.e. re-localisation) place recognition. We also benchmark several state-of-the-art approaches to demonstrate the challenges that this dataset introduces, particularly the case of long-term place recognition due to natural environments changing over time. Our dataset and code will be available at https://csiro-robotics.github.io/Wild-Places.
Uncertainty-Aware Lidar Place Recognition in Novel Environments
Oct 04, 2022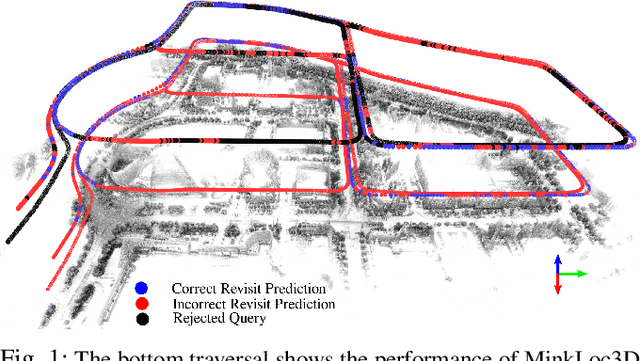
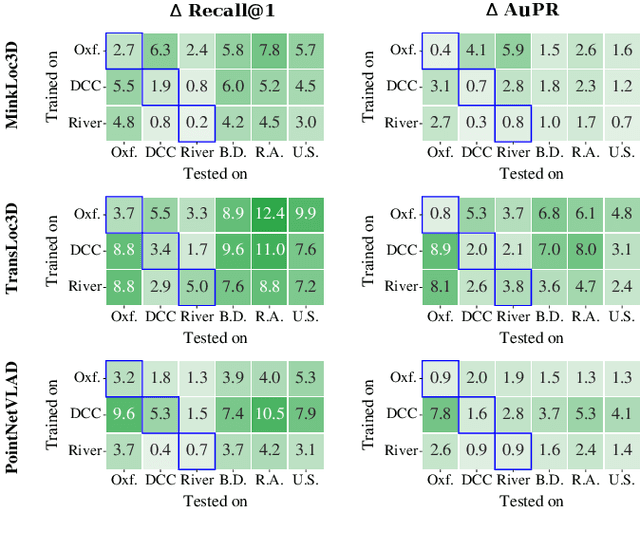
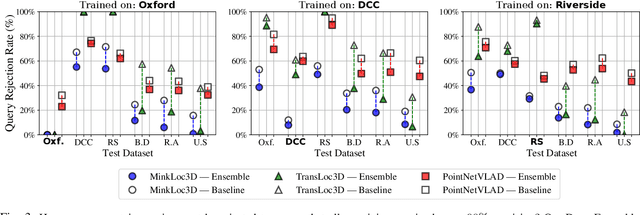
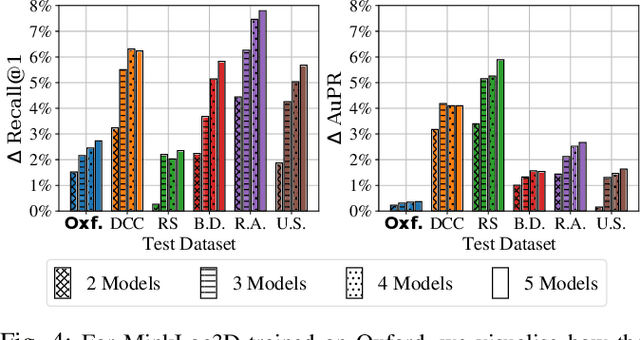
State-of-the-art approaches to lidar place recognition degrade significantly when tested on novel environments that are not present in their training dataset. To improve their reliability, we propose uncertainty-aware lidar place recognition, where each predicted place match must have an associated uncertainty that can be used to identify and reject potentially incorrect matches. We introduce a novel evaluation protocol designed to benchmark uncertainty-aware lidar place recognition, and present Deep Ensembles as the first uncertainty-aware approach for this task. Testing across three large-scale datasets and three state-of-the-art architectures, we show that Deep Ensembles consistently improves the performance of lidar place recognition in novel environments. Compared to a standard network, our results show that Deep Ensembles improves the Recall@1 by more than 5% and AuPR by more than 3% on average when tested on previously unseen environments. Our code repository will be made publicly available upon paper acceptance at https://github.com/csiro-robotics/Uncertainty-LPR.
A Letter on Progress Made on Husky Carbon: A Legged-Aerial, Multi-modal Platform
Jul 25, 2022
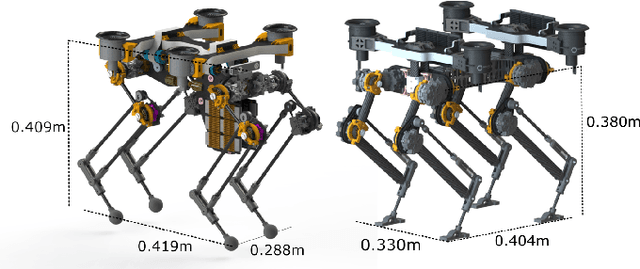
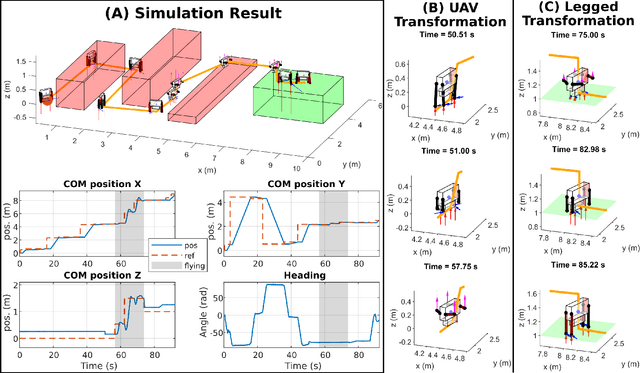
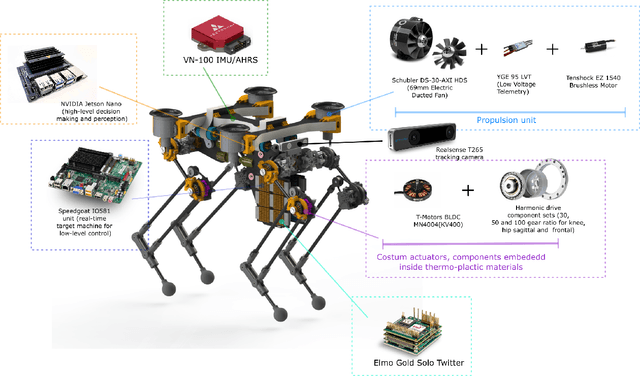
Animals, such as birds, widely use multi-modal locomotion by combining legged and aerial mobility with dominant inertial effects. The robotic biomimicry of this multi-modal locomotion feat can yield ultra-flexible systems in terms of their ability to negotiate their task spaces. The main objective of this paper is to discuss the challenges in achieving multi-modal locomotion, and to report our progress in developing our quadrupedal robot capable of multi-modal locomotion (legged and aerial locomotion), the Husky Carbon. We report the mechanical and electrical components utilized in our robot, in addition to the simulation and experimentation done to achieve our goal in developing a versatile multi-modal robotic platform.
Wildcat: Online Continuous-Time 3D Lidar-Inertial SLAM
May 25, 2022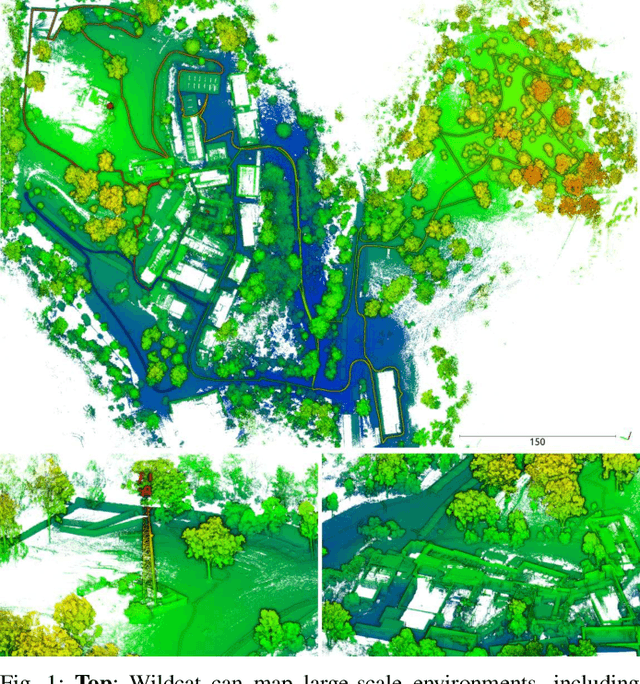
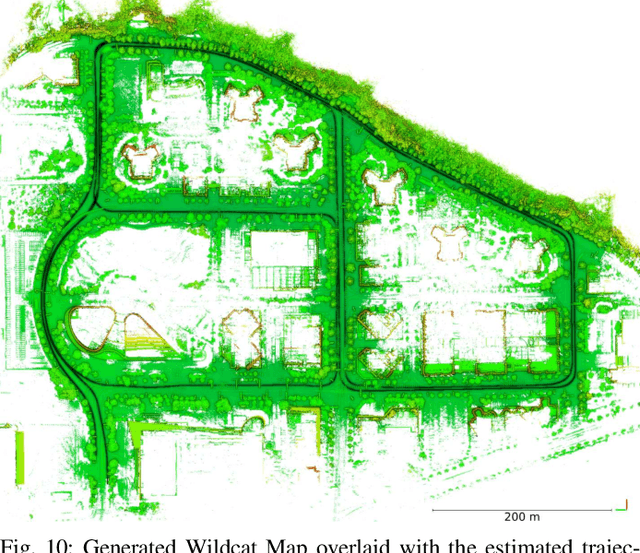
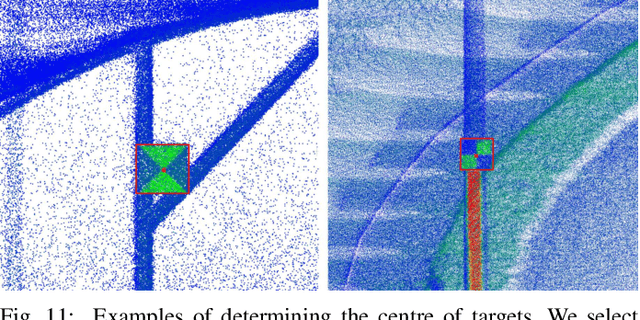
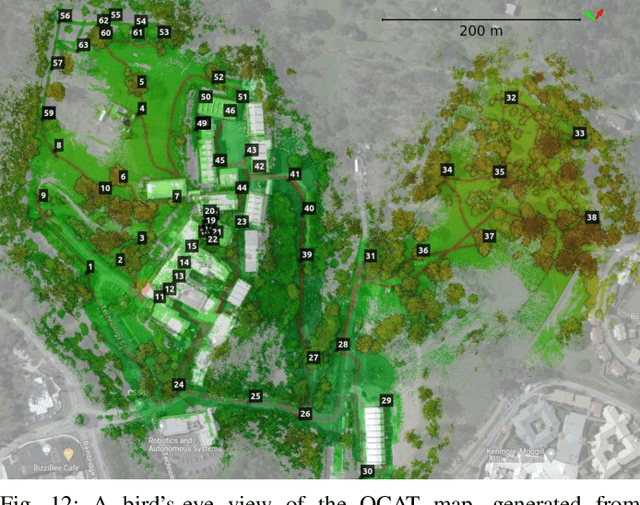
We present Wildcat, a novel online 3D lidar-inertial SLAM system with exceptional versatility and robustness. At its core, Wildcat combines a robust real-time lidar-inertial odometry module, utilising a continuous-time trajectory representation, with an efficient pose-graph optimisation module that seamlessly supports both the single- and multi-agent settings. The robustness of Wildcat was recently demonstrated in the DARPA Subterranean Challenge where it outperformed other SLAM systems across various types of sensing-degraded and perceptually challenging environments. In this paper, we extensively evaluate Wildcat in a diverse set of new and publicly available real-world datasets and showcase its superior robustness and versatility over two existing state-of-the-art lidar-inertial SLAM systems.
InCloud: Incremental Learning for Point Cloud Place Recognition
Mar 02, 2022
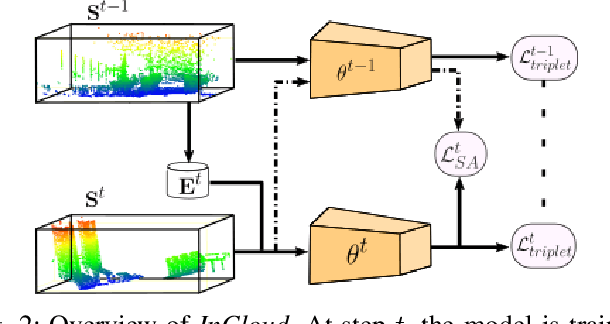
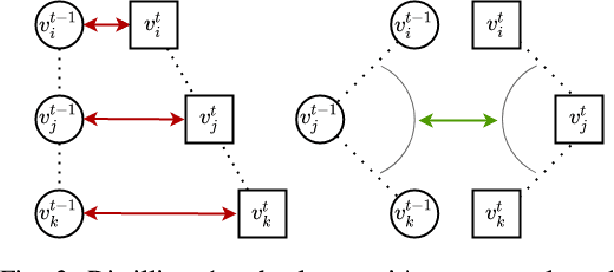
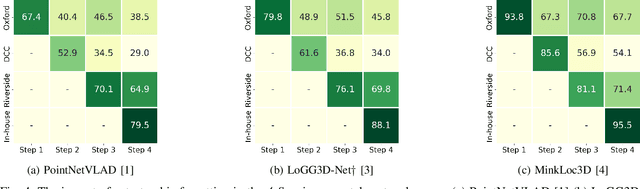
Place recognition is a fundamental component of robotics, and has seen tremendous improvements through the use of deep learning models in recent years. Networks can experience significant drops in performance when deployed in unseen or highly dynamic environments, and require additional training on the collected data. However naively fine-tuning on new training distributions can cause severe degradation of performance on previously visited domains, a phenomenon known as catastrophic forgetting. In this paper we address the problem of incremental learning for point cloud place recognition and introduce InCloud, a structure-aware distillation-based approach which preserves the higher-order structure of the network's embedding space. We introduce several challenging new benchmarks on four popular and large-scale LiDAR datasets (Oxford, MulRan, In-house and KITTI) showing broad improvements in point cloud place recognition performance over a variety of network architectures. To the best of our knowledge, this work is the first to effectively apply incremental learning for point cloud place recognition.
AEROS: Adaptive RObust least-Squares for Graph-Based SLAM
Oct 03, 2021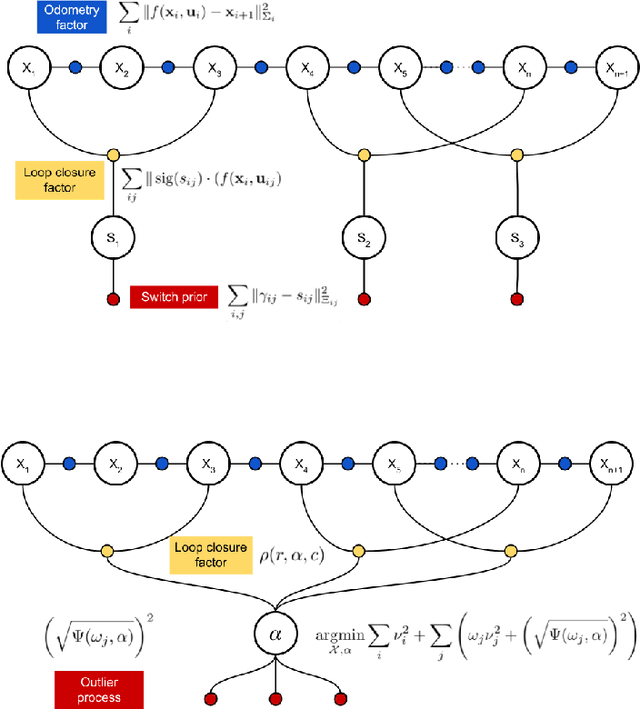
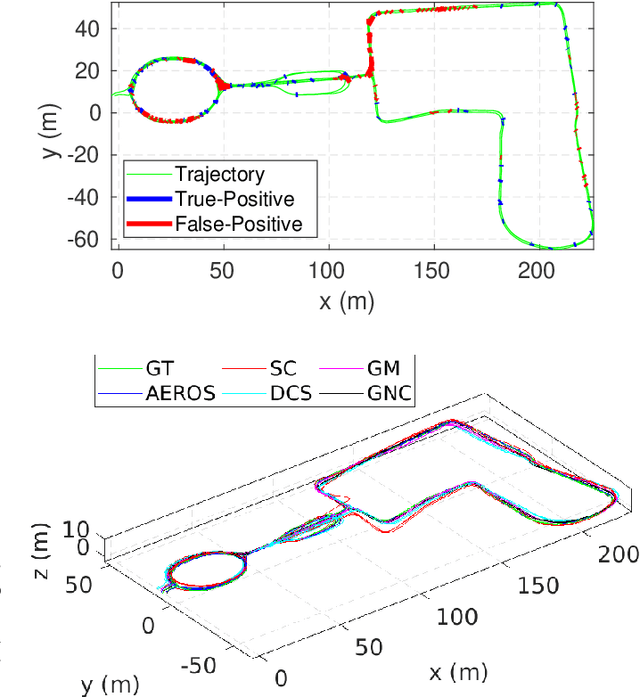
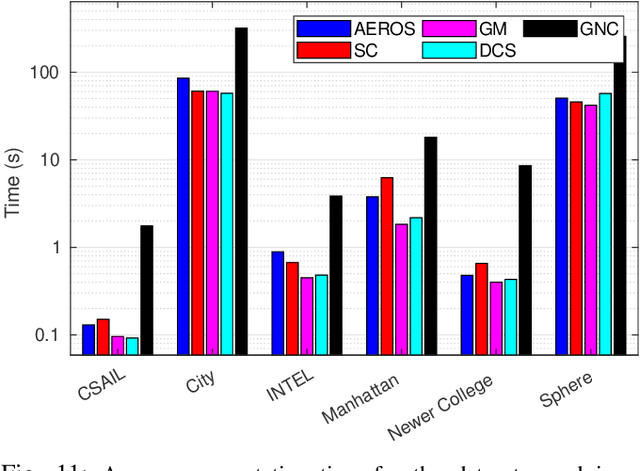
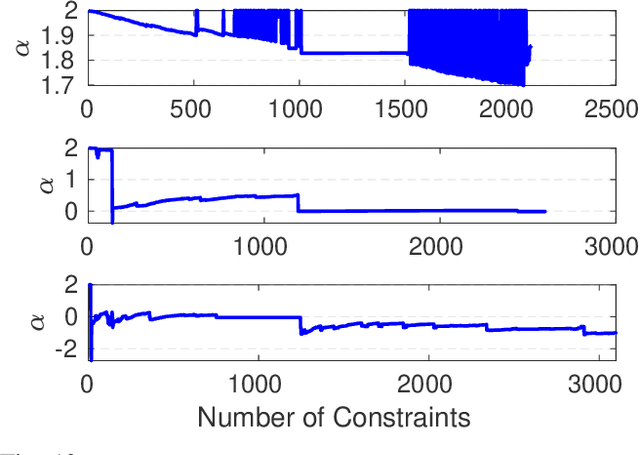
In robot localisation and mapping, outliers are unavoidable when loop-closure measurements are taken into account. A single false-positive loop-closure can have a very negative impact on SLAM problems causing an inferior trajectory to be produced or even for the optimisation to fail entirely. To address this issue, popular existing approaches define a hard switch for each loop-closure constraint. This paper presents AEROS, a novel approach to adaptively solve a robust least-squares minimisation problem by adding just a single extra latent parameter. It can be used in the back-end component of the SLAM problem to enable generalised robust cost minimisation by simultaneously estimating the continuous latent parameter along with the set of sensor poses in a single joint optimisation. This leads to a very closely curve fitting on the distribution of the residuals, thereby reducing the effect of outliers. Additionally, we formulate the robust optimisation problem using standard Gaussian factors so that it can be solved by direct application of popular incremental estimation approaches such as iSAM. Experimental results on publicly available synthetic datasets and real LiDAR-SLAM datasets collected from the 2D and 3D LiDAR systems show the competitiveness of our approach with the state-of-the-art techniques and its superiority on real world scenarios.
LoGG3D-Net: Locally Guided Global Descriptor Learning for 3D Place Recognition
Sep 22, 2021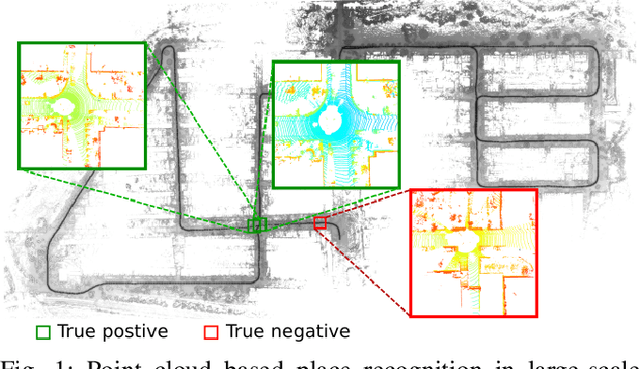
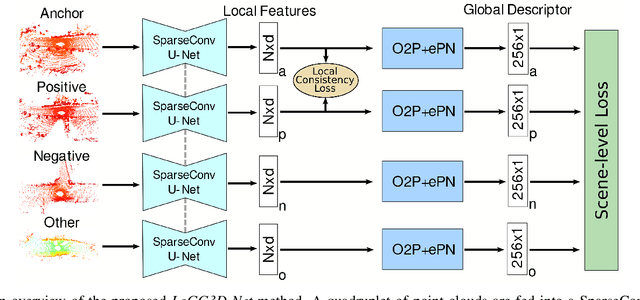
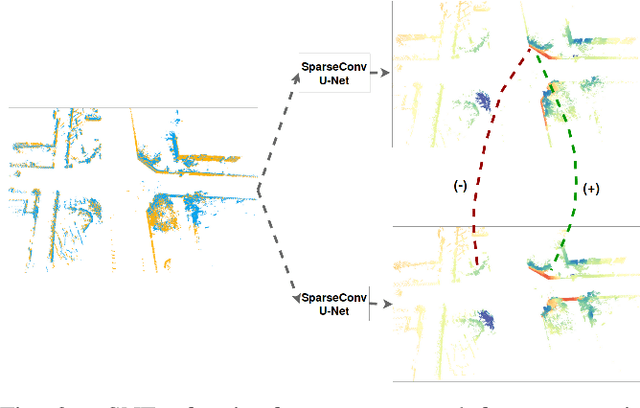
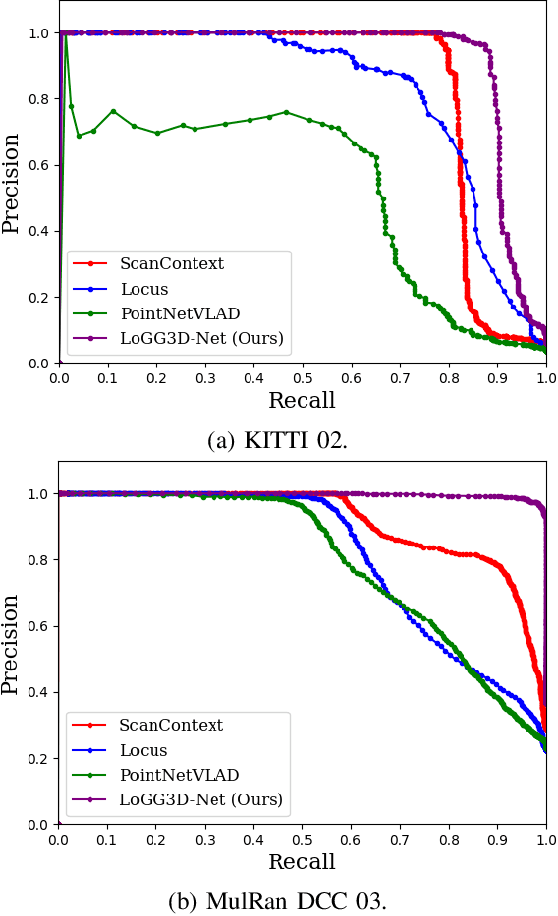
Retrieval-based place recognition is an efficient and effective solution for enabling re-localization within a pre-built map or global data association for Simultaneous Localization and Mapping (SLAM). The accuracy of such an approach is heavily dependent on the quality of the extracted scene-level representation. While end-to-end solutions, which learn a global descriptor from input point clouds, have demonstrated promising results, such approaches are limited in their ability to enforce desirable properties at the local feature level. In this paper, we demonstrate that the inclusion of an additional training signal (local consistency loss) can guide the network to learning local features which are consistent across revisits, hence leading to more repeatable global descriptors resulting in an overall improvement in place recognition performance. We formulate our approach in an end-to-end trainable architecture called LoGG3D-Net. Experiments on two large-scale public benchmarks (KITTI and MulRan) show that our method achieves mean $F1_{max}$ scores of $0.939$ and $0.968$ on KITTI and MulRan, respectively while operating in near real-time.
Online Estimation of Diameter at Breast Height (DBH) of Forest Trees Using a Handheld LiDAR
Aug 03, 2021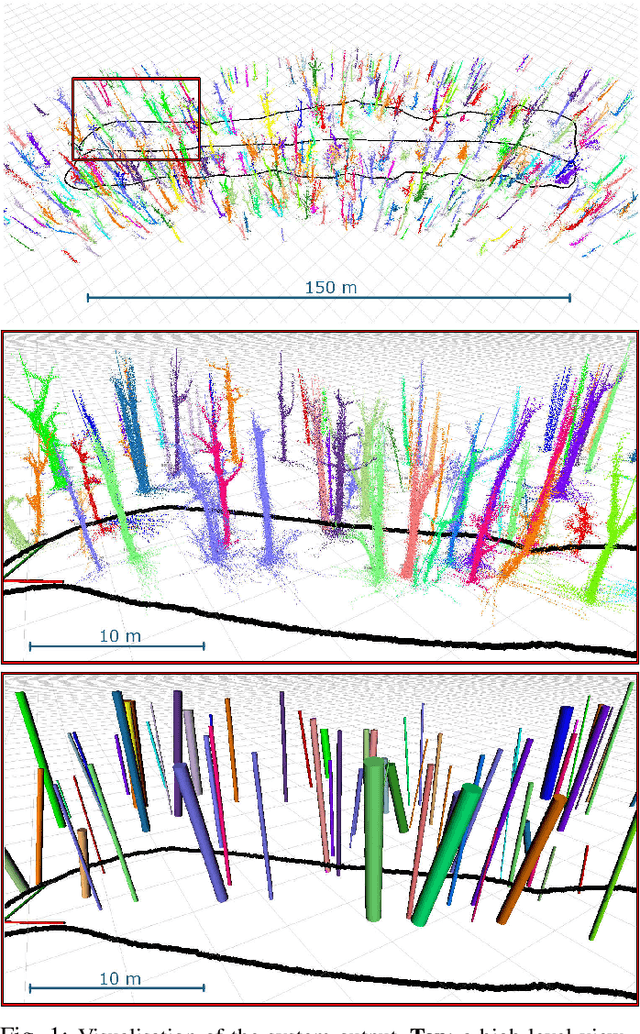
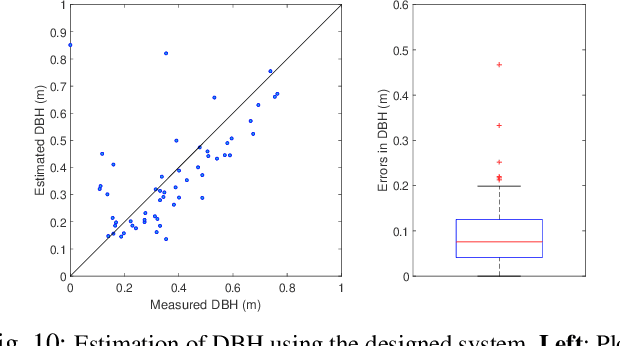

While mobile LiDAR sensors are increasingly used to scan in ecology and forestry applications, reconstruction and characterisation are typically carried out offline (to the best of our knowledge). Motivated by this, we present an online LiDAR system which can run on a handheld device to segment and track individual trees and identify them in a fixed coordinate system. Segments relating to each tree are accumulated over time, and tree models are completed as more scans are captured from different perspectives. Using this reconstruction we then fit a cylinder model to each tree trunk by solving a least-squares optimisation over the points to estimate the Diameter at Breast Height (DBH) of the trees. Experimental results demonstrate that our system can estimate DBH to within $\sim$7 cm accuracy for 90% of individual trees in a forest (Wytham Woods, Oxford)
Scalable and Elastic LiDAR Reconstruction in Complex Environments Through Spatial Analysis
Jun 29, 2021
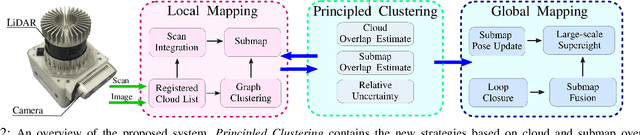
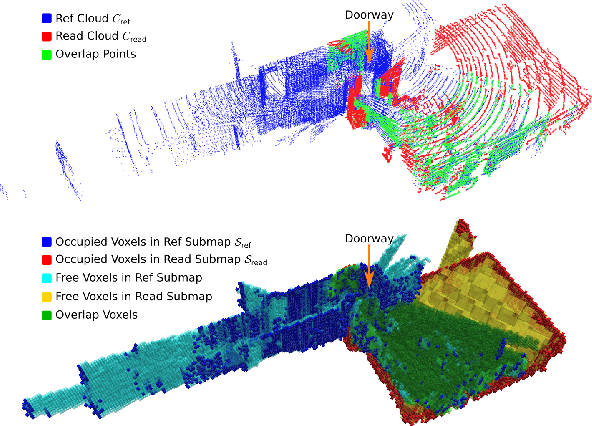

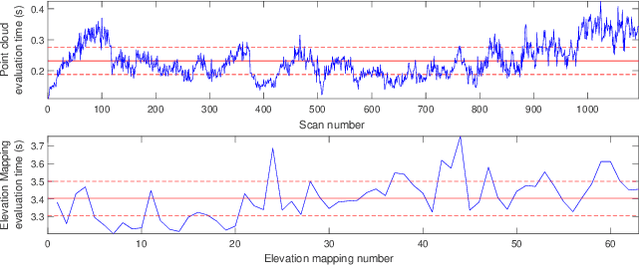
This paper presents novel strategies for spawning and fusing submaps within an elastic dense 3D reconstruction system. The proposed system uses spatial understanding of the scanned environment to control memory usage growth by fusing overlapping submaps in different ways. This allows the number of submaps and memory consumption to scale with the size of the environment rather than the duration of exploration. By analysing spatial overlap, our system segments distinct spaces, such as rooms and stairwells on the fly during exploration. Additionally, we present a new mathematical formulation of relative uncertainty between poses to improve the global consistency of the reconstruction. Performance is demonstrated using a multi-floor multi-room indoor experiment, a large-scale outdoor experiment and a simulated dataset. Relative to our baseline, the presented approach demonstrates improved scalability and accuracy.
Learning Camera Performance Models for Active Multi-Camera Visual Teach and Repeat
Mar 25, 2021
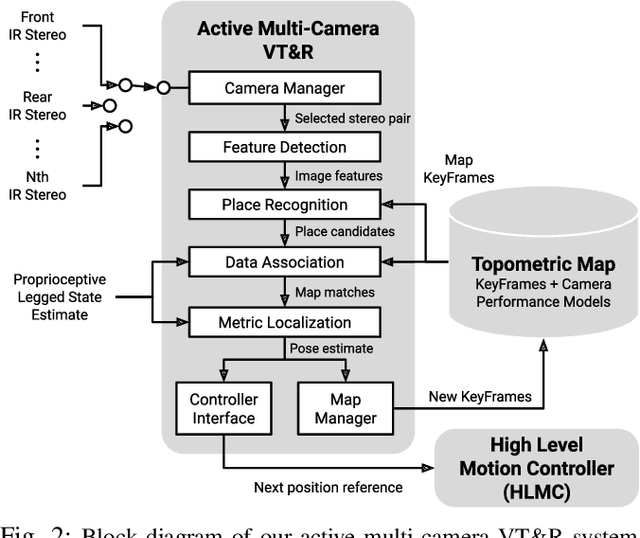
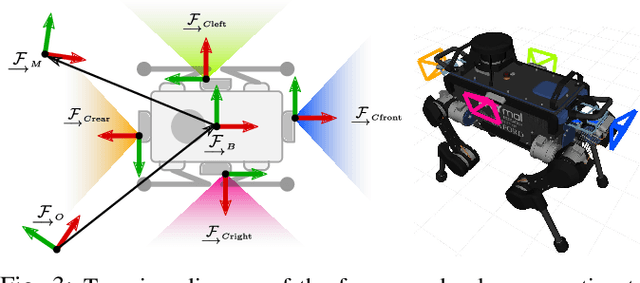
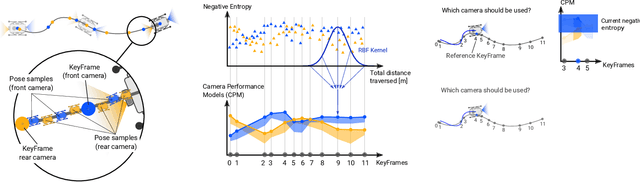
In dynamic and cramped industrial environments, achieving reliable Visual Teach and Repeat (VT&R) with a single-camera is challenging. In this work, we develop a robust method for non-synchronized multi-camera VT&R. Our contribution are expected Camera Performance Models (CPM) which evaluate the camera streams from the teach step to determine the most informative one for localization during the repeat step. By actively selecting the most suitable camera for localization, we are able to successfully complete missions when one of the cameras is occluded, faces into feature poor locations or if the environment has changed. Furthermore, we explore the specific challenges of achieving VT&R on a dynamic quadruped robot, ANYmal. The camera does not follow a linear path (due to the walking gait and holonomicity) such that precise path-following cannot be achieved. Our experiments feature forward and backward facing stereo cameras showing VT&R performance in cluttered indoor and outdoor scenarios. We compared the trajectories the robot executed during the repeat steps demonstrating typical tracking precision of less than 10cm on average. With a view towards omni-directional localization, we show how the approach generalizes to four cameras in simulation. Video: https://youtu.be/iAY0lyjAnqY