 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Benchmarking for Robotic Perception in Natural Environments
Jun 10, 2026Natural environments present a complex challenge to robotics perception systems. Current models, particularly vision foundation models, are largely trained on structured, urban environments leading to weaknesses in their perception for field robotics tasks. We showcase the limitations of current models using our recently released WildCross benchmark, a new cross-modal benchmark for place recognition and metric depth estimation in large-scale natural environments. WildCross comprises over 476K sequential RGB frames with semi-dense depth and surface normal annotations, each aligned with accurate 6DoF pose and synchronized dense lidar submaps. In this work, we provide an expanded analysis of the benchmark results from the recent WildCross benchmark, with particular emphasis on expanded metric depth estimation experiments. Access to the code repository and dataset for this work can be found at https://csiro-robotics.github.io/WildCross.
WildCross: A Cross-Modal Large Scale Benchmark for Place Recognition and Metric Depth Estimation in Natural Environments
Mar 02, 2026Recent years have seen a significant increase in demand for robotic solutions in unstructured natural environments, alongside growing interest in bridging 2D and 3D scene understanding. However, existing robotics datasets are predominantly captured in structured urban environments, making them inadequate for addressing the challenges posed by complex, unstructured natural settings. To address this gap, we propose WildCross, a cross-modal benchmark for place recognition and metric depth estimation in large-scale natural environments. WildCross comprises over 476K sequential RGB frames with semi-dense depth and surface normal annotations, each aligned with accurate 6DoF poses and synchronized dense lidar submaps. We conduct comprehensive experiments on visual, lidar, and cross-modal place recognition, as well as metric depth estimation, demonstrating the value of WildCross as a challenging benchmark for multi-modal robotic perception tasks. We provide access to the code repository and dataset at https://csiro-robotics.github.io/WildCross.
REGRACE: A Robust and Efficient Graph-based Re-localization Algorithm using Consistency Evaluation
Mar 05, 2025



Loop closures are essential for correcting odometry drift and creating consistent maps, especially in the context of large-scale navigation. Current methods using dense point clouds for accurate place recognition do not scale well due to computationally expensive scan-to-scan comparisons. Alternative object-centric approaches are more efficient but often struggle with sensitivity to viewpoint variation. In this work, we introduce REGRACE, a novel approach that addresses these challenges of scalability and perspective difference in re-localization by using LiDAR-based submaps. We introduce rotation-invariant features for each labeled object and enhance them with neighborhood context through a graph neural network. To identify potential revisits, we employ a scalable bag-of-words approach, pooling one learned global feature per submap. Additionally, we define a revisit with geometrical consistency cues rather than embedding distance, allowing us to recognize far-away loop closures. Our evaluations demonstrate that REGRACE achieves similar results compared to state-of-the-art place recognition and registration baselines while being twice as fast.
SOLVR: Submap Oriented LiDAR-Visual Re-Localisation
Sep 16, 2024This paper proposes SOLVR, a unified pipeline for learning based LiDAR-Visual re-localisation which performs place recognition and 6-DoF registration across sensor modalities. We propose a strategy to align the input sensor modalities by leveraging stereo image streams to produce metric depth predictions with pose information, followed by fusing multiple scene views from a local window using a probabilistic occupancy framework to expand the limited field-of-view of the camera. Additionally, SOLVR adopts a flexible definition of what constitutes positive examples for different training losses, allowing us to simultaneously optimise place recognition and registration performance. Furthermore, we replace RANSAC with a registration function that weights a simple least-squares fitting with the estimated inlier likelihood of sparse keypoint correspondences, improving performance in scenarios with a low inlier ratio between the query and retrieved place. Our experiments on the KITTI and KITTI360 datasets show that SOLVR achieves state-of-the-art performance for LiDAR-Visual place recognition and registration, particularly improving registration accuracy over larger distances between the query and retrieved place.
WildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
Pose-Graph Attentional Graph Neural Network for Lidar Place Recognition
Aug 31, 2023



This paper proposes a lidar place recognition approach, called P-GAT, to increase the receptive field between point clouds captured over time. Instead of comparing pairs of point clouds, we compare the similarity between sets of point clouds to use the maximum spatial and temporal information between neighbour clouds utilising the concept of pose-graph SLAM. Leveraging intra- and inter-attention and graph neural network, P-GAT relates point clouds captured in nearby locations in Euclidean space and their embeddings in feature space. Experimental results on the large-scale publically available datasets demonstrate the effectiveness of our approach in recognising scenes lacking distinct features and when training and testing environments have different distributions (domain adaptation). Further, an exhaustive comparison with the state-of-the-art shows improvements in performance gains. Code will be available upon acceptance.
GeoAdapt: Self-Supervised Test-Time Adaption in LiDAR Place Recognition Using Geometric Priors
Aug 09, 2023



LiDAR place recognition approaches based on deep learning suffer a significant degradation in performance when there is a shift between the distribution of the training and testing datasets, with re-training often required to achieve top performance. However, obtaining accurate ground truth on new environments can be prohibitively expensive, especially in complex or GPS-deprived environments. To address this issue we propose GeoAdapt, which introduces a novel auxiliary classification head to generate pseudo-labels for re-training on unseen environments in a self-supervised manner. GeoAdapt uses geometric consistency as a prior to improve the robustness of our generated pseudo-labels against domain shift, improving the performance and reliability of our Test-Time Adaptation approach. Comprehensive experiments show that GeoAdapt significantly boosts place recognition performance across moderate to severe domain shifts, and is competitive with fully supervised test-time adaptation approaches. Our code will be available at https://github.com/csiro-robotics/GeoAdapt.
Wild-Places: A Large-Scale Dataset for Lidar Place Recognition in Unstructured Natural Environments
Nov 29, 2022Many existing datasets for lidar place recognition are solely representative of structured urban environments, and have recently been saturated in performance by deep learning based approaches. Natural and unstructured environments present many additional challenges for the tasks of long-term localisation but these environments are not represented in currently available datasets. To address this we introduce Wild-Places, a challenging large-scale dataset for lidar place recognition in unstructured, natural environments. Wild-Places contains eight lidar sequences collected with a handheld sensor payload over the course of fourteen months, containing a total of 67K undistorted lidar submaps along with accurate 6DoF ground truth. Our dataset contains multiple revisits both within and between sequences, allowing for both intra-sequence (i.e. loop closure detection) and inter-sequence (i.e. re-localisation) place recognition. We also benchmark several state-of-the-art approaches to demonstrate the challenges that this dataset introduces, particularly the case of long-term place recognition due to natural environments changing over time. Our dataset and code will be available at https://csiro-robotics.github.io/Wild-Places.
Uncertainty-Aware Lidar Place Recognition in Novel Environments
Oct 04, 2022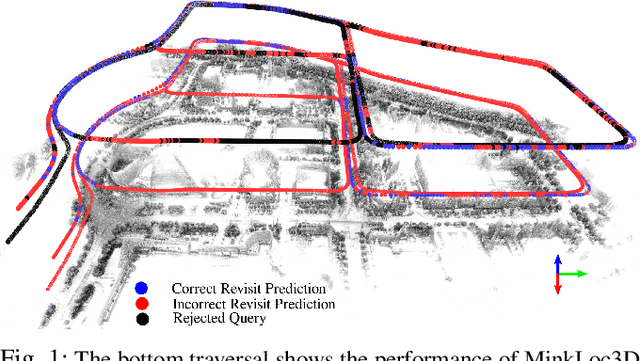
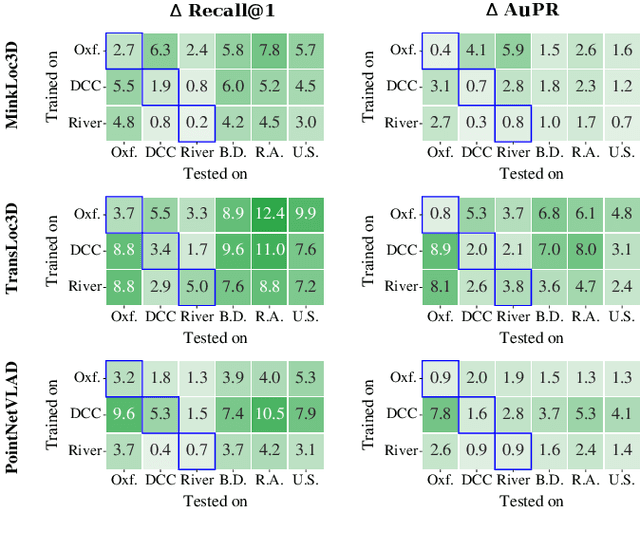
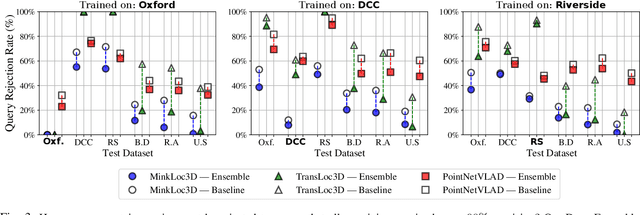
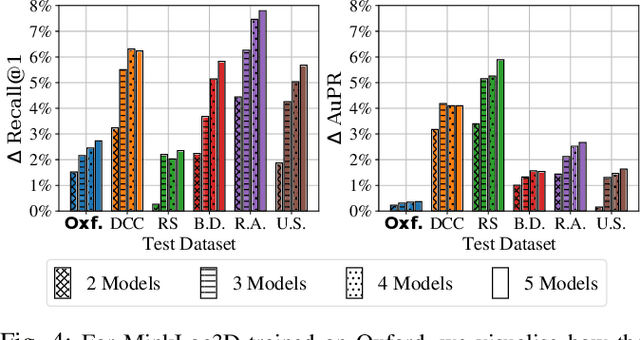
State-of-the-art approaches to lidar place recognition degrade significantly when tested on novel environments that are not present in their training dataset. To improve their reliability, we propose uncertainty-aware lidar place recognition, where each predicted place match must have an associated uncertainty that can be used to identify and reject potentially incorrect matches. We introduce a novel evaluation protocol designed to benchmark uncertainty-aware lidar place recognition, and present Deep Ensembles as the first uncertainty-aware approach for this task. Testing across three large-scale datasets and three state-of-the-art architectures, we show that Deep Ensembles consistently improves the performance of lidar place recognition in novel environments. Compared to a standard network, our results show that Deep Ensembles improves the Recall@1 by more than 5% and AuPR by more than 3% on average when tested on previously unseen environments. Our code repository will be made publicly available upon paper acceptance at https://github.com/csiro-robotics/Uncertainty-LPR.
InCloud: Incremental Learning for Point Cloud Place Recognition
Mar 02, 2022
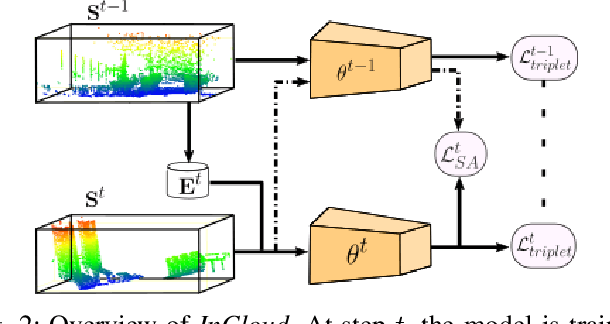
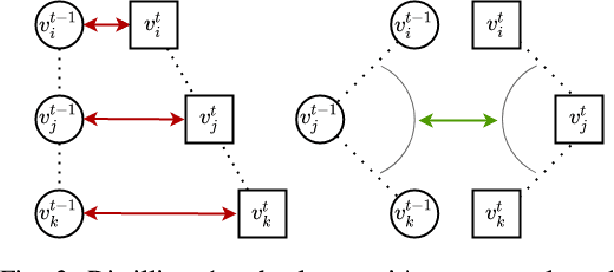
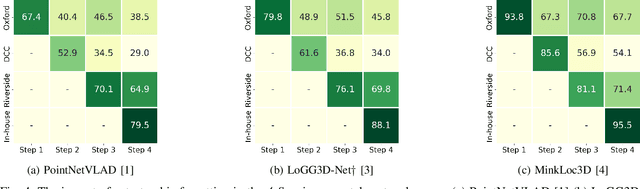
Place recognition is a fundamental component of robotics, and has seen tremendous improvements through the use of deep learning models in recent years. Networks can experience significant drops in performance when deployed in unseen or highly dynamic environments, and require additional training on the collected data. However naively fine-tuning on new training distributions can cause severe degradation of performance on previously visited domains, a phenomenon known as catastrophic forgetting. In this paper we address the problem of incremental learning for point cloud place recognition and introduce InCloud, a structure-aware distillation-based approach which preserves the higher-order structure of the network's embedding space. We introduce several challenging new benchmarks on four popular and large-scale LiDAR datasets (Oxford, MulRan, In-house and KITTI) showing broad improvements in point cloud place recognition performance over a variety of network architectures. To the best of our knowledge, this work is the first to effectively apply incremental learning for point cloud place recognition.