 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeScale: Distributed Training for Sequence Recommendation Models with Minimal Scaling Cost
Apr 27, 2026Modern industrial Deep Learning Recommendation Models typically extract user preferences through the analysis of sequential interaction histories, subsequently generating predictions based on these derived interests. The inherent heterogeneity in data characteristics frequently result in substantial under-utilization of computational resources during large-scale training, primarily due to computational bubbles caused by severe stragglers and slow blocking communications. This paper introduces FreeScale, a solution designed to (1) mitigate the straggler problem through meticulously load balanced input samples (2) minimize the blocking communication by overlapping prioritized embedding communications with computations (3) resolve the GPU resource competition during computation and communication overlapping by communicating through SM-Free techniques. Empirical evaluation demonstrates that FreeScale achieves up to 90.3% reduction in computational bubbles when applied to real-world workloads running on 256 H100 GPUs.
Sparse Forcing: Native Trainable Sparse Attention for Real-time Autoregressive Diffusion Video Generation
Apr 23, 2026We introduce Sparse Forcing, a training-and-inference paradigm for autoregressive video diffusion models that improves long-horizon generation quality while reducing decoding latency. Sparse Forcing is motivated by an empirical observation in autoregressive diffusion rollouts: attention concentrates on a persistent subset of salient visual blocks, forming an implicit spatiotemporal memory in the KV cache, and exhibits a locally structured block-sparse pattern within sliding windows. Building on this observation, we propose a trainable native sparsity mechanism that learns to compress, preserve, and update these persistent blocks while restricting computation within each local window to a dynamically selected local neighborhood. To make the approach practical at scale for both training and inference, we further propose Persistent Block-Sparse Attention (PBSA), an efficient GPU kernel that accelerates sparse attention and memory updates for low-latency, memory-efficient decoding. Experiments show that Sparse Forcing improves the VBench score by +0.26 over Self-Forcing on 5-second text-to-video generation while delivering a 1.11-1.17x decoding speedup and 42% lower peak KV-cache footprint. The gains are more pronounced on longer-horizon rollouts, delivering improved visual quality with +0.68 and +2.74 VBench improvements, and 1.22x and 1.27x speedups on 20-second and 1-minute generations, respectively.
Pushing DSP-Free Coherent Interconnect to the Last Inch by Optically Analog Signal Processing
Mar 14, 2025



To support the boosting interconnect capacity of the AI-related data centers, novel techniques enabled high-speed and low-cost optics are continuously emerging. When the baud rate approaches 200 GBaud per lane, the bottle-neck of traditional intensity modulation direct detection (IM-DD) architectures becomes increasingly evident. The simplified coherent solutions are widely discussed and considered as one of the most promising candidates. In this paper, a novel coherent architecture based on self-homodyne coherent detection and optically analog signal processing (OASP) is demonstrated. Proved by experiment, the first DSP-free baud-rate sampled 64-GBaud QPSK/16-QAM receptions are achieved, with BERs of 1e-6 and 2e-2, respectively. Even with 1-km fiber link propagation, the BER for QPSK reception remains at 3.6e-6. When an ultra-simple 1-sps SISO filter is utilized, the performance degradation of the proposed scheme is less than 1 dB compared to legacy DSP-based coherent reception. The proposed results pave the way for the ultra-high-speed coherent optical interconnections, offering high power and cost efficiency.
Addressing Data Scarcity in Optical Matrix Multiplier Modeling Using Transfer Learning
Aug 10, 2023We present and experimentally evaluate using transfer learning to address experimental data scarcity when training neural network (NN) models for Mach-Zehnder interferometer mesh-based optical matrix multipliers. Our approach involves pre-training the model using synthetic data generated from a less accurate analytical model and fine-tuning with experimental data. Our investigation demonstrates that this method yields significant reductions in modeling errors compared to using an analytical model, or a standalone NN model when training data is limited. Utilizing regularization techniques and ensemble averaging, we achieve < 1 dB root-mean-square error on the matrix weights implemented by a photonic chip while using only 25% of the available data.
Data-efficient Modeling of Optical Matrix Multipliers Using Transfer Learning
Nov 29, 2022

We demonstrate transfer learning-assisted neural network models for optical matrix multipliers with scarce measurement data. Our approach uses <10\% of experimental data needed for best performance and outperforms analytical models for a Mach-Zehnder interferometer mesh.
Data-driven Modeling of Mach-Zehnder Interferometer-based Optical Matrix Multipliers
Oct 17, 2022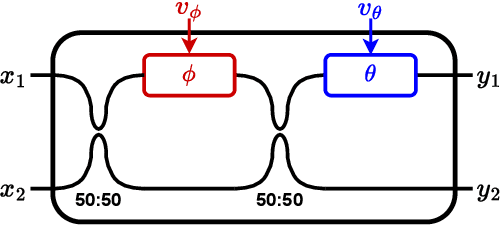
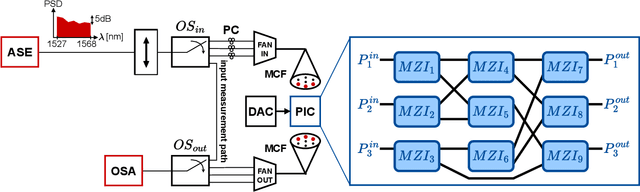
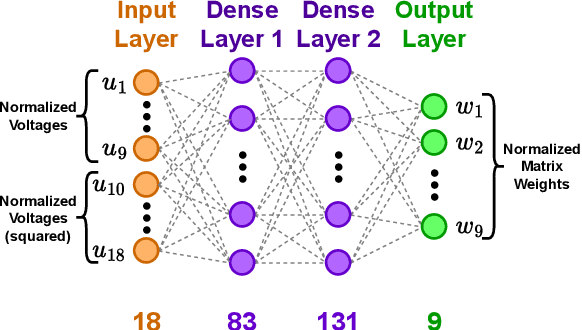
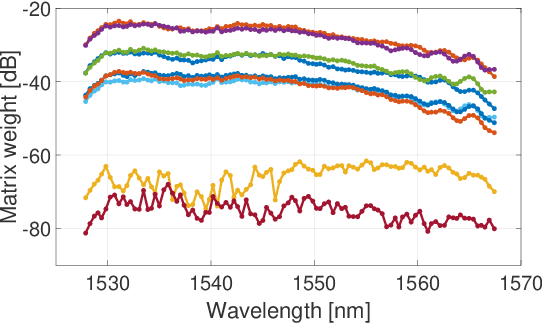
Photonic integrated circuits are facilitating the development of optical neural networks, which have the potential to be both faster and more energy efficient than their electronic counterparts since optical signals are especially well-suited for implementing matrix multiplications. However, accurate programming of photonic chips for optical matrix multiplication remains a difficult challenge. Here, we describe both simple analytical models and data-driven models for offline training of optical matrix multipliers. We train and evaluate the models using experimental data obtained from a fabricated chip featuring a Mach-Zehnder interferometer mesh implementing 3-by-3 matrix multiplication. The neural network-based models outperform the simple physics-based models in terms of prediction error. Furthermore, the neural network models are also able to predict the spectral variations in the matrix weights for up to 100 frequency channels covering the C-band. The use of neural network models for programming the chip for optical matrix multiplication yields increased performance on multiple machine learning tasks.
Comparison of Models for Training Optical Matrix Multipliers in Neuromorphic PICs
Nov 23, 2021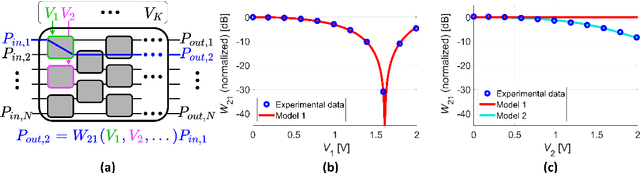

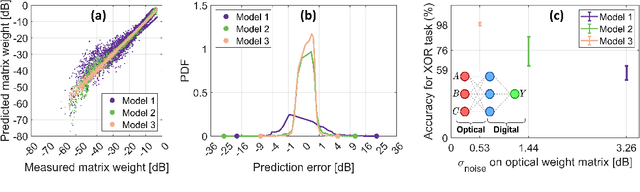
We experimentally compare simple physics-based vs. data-driven neural-network-based models for offline training of programmable photonic chips using Mach-Zehnder interferometer meshes. The neural-network model outperforms physics-based models for a chip with thermal crosstalk, yielding increased testing accuracy.
Captum: A unified and generic model interpretability library for PyTorch
Sep 16, 2020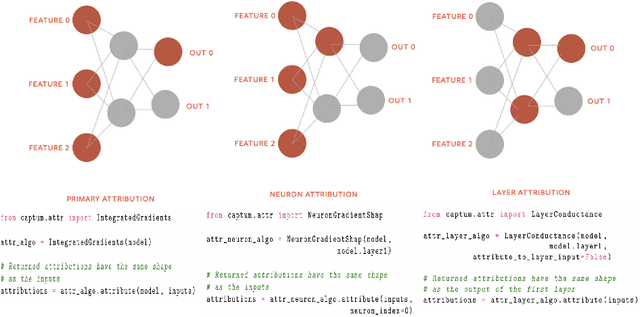

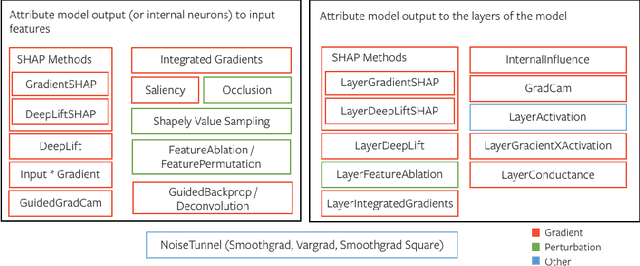
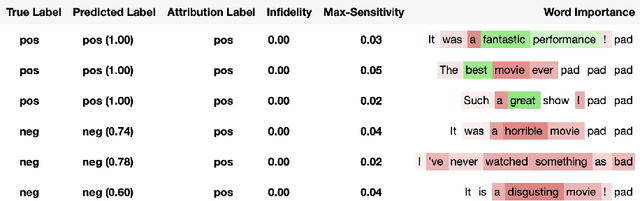
In this paper we introduce a novel, unified, open-source model interpretability library for PyTorch [12]. The library contains generic implementations of a number of gradient and perturbation-based attribution algorithms, also known as feature, neuron and layer importance algorithms, as well as a set of evaluation metrics for these algorithms. It can be used for both classification and non-classification models including graph-structured models built on Neural Networks (NN). In this paper we give a high-level overview of supported attribution algorithms and show how to perform memory-efficient and scalable computations. We emphasize that the three main characteristics of the library are multimodality, extensibility and ease of use. Multimodality supports different modality of inputs such as image, text, audio or video. Extensibility allows adding new algorithms and features. The library is also designed for easy understanding and use. Besides, we also introduce an interactive visualization tool called Captum Insights that is built on top of Captum library and allows sample-based model debugging and visualization using feature importance metrics.