 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring Latent Spaces for Stylized Response Generation
Sep 03, 2019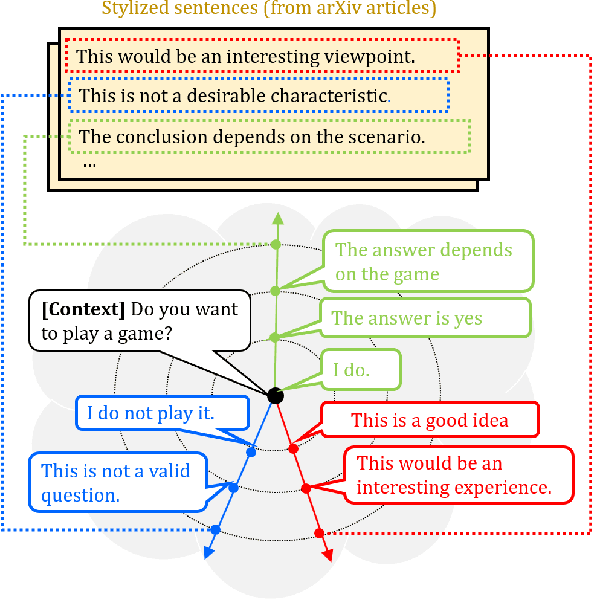
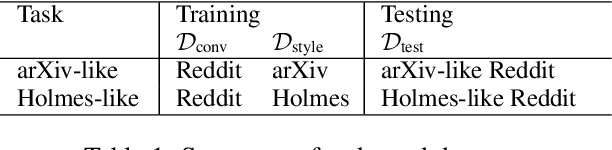
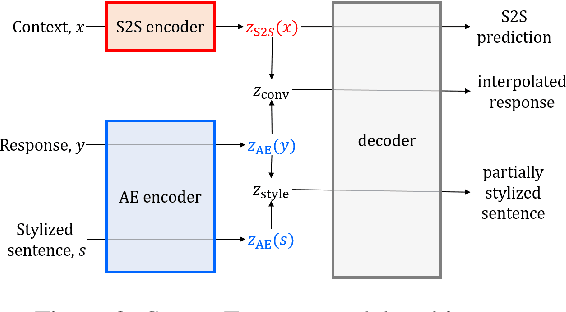

Generating responses in a targeted style is a useful yet challenging task, especially in the absence of parallel data. With limited data, existing methods tend to generate responses that are either less stylized or less context-relevant. We propose StyleFusion, which bridges conversation modeling and non-parallel style transfer by sharing a structured latent space. This structure allows the system to generate stylized relevant responses by sampling in the neighborhood of the conversation model prediction, and continuously control the style level. We demonstrate this method using dialogues from Reddit data and two sets of sentences with distinct styles (arXiv and Sherlock Holmes novels). Automatic and human evaluation show that, without sacrificing appropriateness, the system generates responses of the targeted style and outperforms competitive baselines.
* accepted to appear at EMNLP 2019 (long)
Conversing by Reading: Contentful Neural Conversation with On-demand Machine Reading
Jun 07, 2019
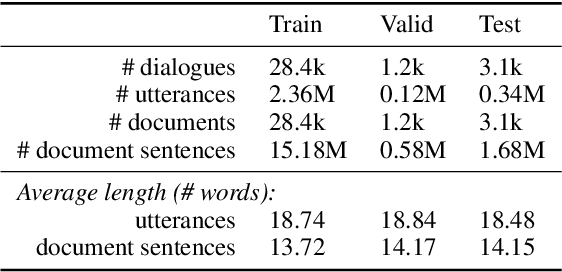
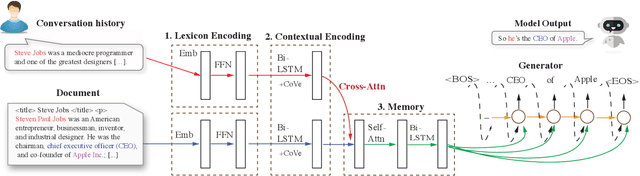
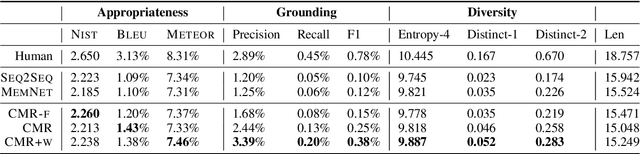
Although neural conversation models are effective in learning how to produce fluent responses, their primary challenge lies in knowing what to say to make the conversation contentful and non-vacuous. We present a new end-to-end approach to contentful neural conversation that jointly models response generation and on-demand machine reading. The key idea is to provide the conversation model with relevant long-form text on the fly as a source of external knowledge. The model performs QA-style reading comprehension on this text in response to each conversational turn, thereby allowing for more focused integration of external knowledge than has been possible in prior approaches. To support further research on knowledge-grounded conversation, we introduce a new large-scale conversation dataset grounded in external web pages (2.8M turns, 7.4M sentences of grounding). Both human evaluation and automated metrics show that our approach results in more contentful responses compared to a variety of previous methods, improving both the informativeness and diversity of generated output.
Towards Content Transfer through Grounded Text Generation
May 13, 2019

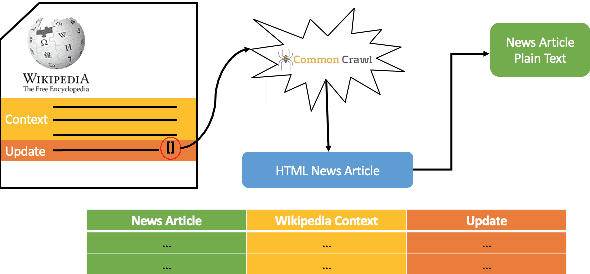
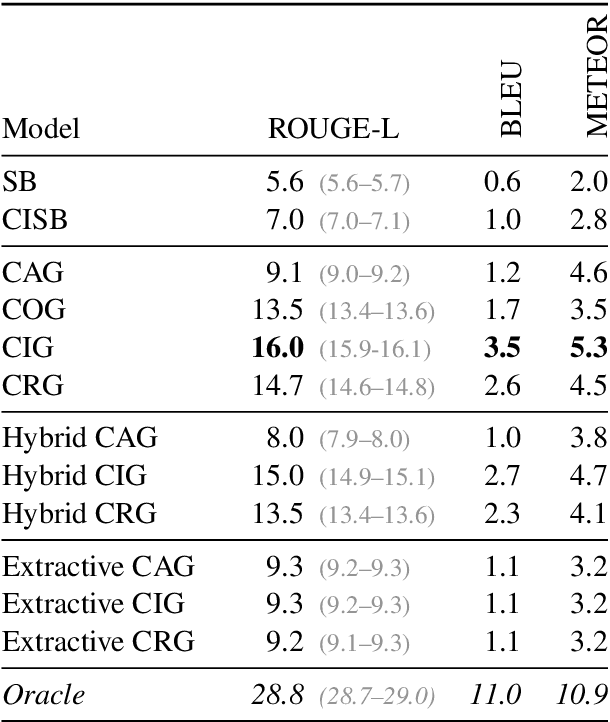
Recent work in neural generation has attracted significant interest in controlling the form of text, such as style, persona, and politeness. However, there has been less work on controlling neural text generation for content. This paper introduces the notion of Content Transfer for long-form text generation, where the task is to generate a next sentence in a document that both fits its context and is grounded in a content-rich external textual source such as a news story. Our experiments on Wikipedia data show significant improvements against competitive baselines. As another contribution of this paper, we release a benchmark dataset of 640k Wikipedia referenced sentences paired with the source articles to encourage exploration of this new task.
Jointly Optimizing Diversity and Relevance in Neural Response Generation
Apr 04, 2019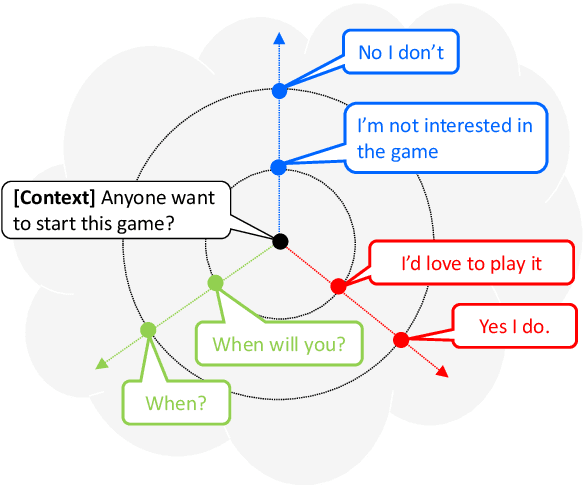
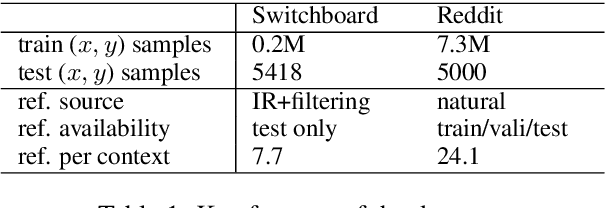
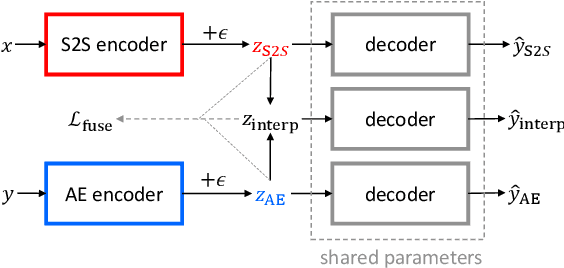

Although recent neural conversation models have shown great potential, they often generate bland and generic responses. While various approaches have been explored to diversify the output of the conversation model, the improvement often comes at the cost of decreased relevance. In this paper, we propose a SpaceFusion model to jointly optimize diversity and relevance that essentially fuses the latent space of a sequence-to-sequence model and that of an autoencoder model by leveraging novel regularization terms. As a result, our approach induces a latent space in which the distance and direction from the predicted response vector roughly match the relevance and diversity, respectively. This property also lends itself well to an intuitive visualization of the latent space. Both automatic and human evaluation results demonstrate that the proposed approach brings significant improvement compared to strong baselines in both diversity and relevance.
Consistent Dialogue Generation with Self-supervised Feature Learning
Mar 27, 2019
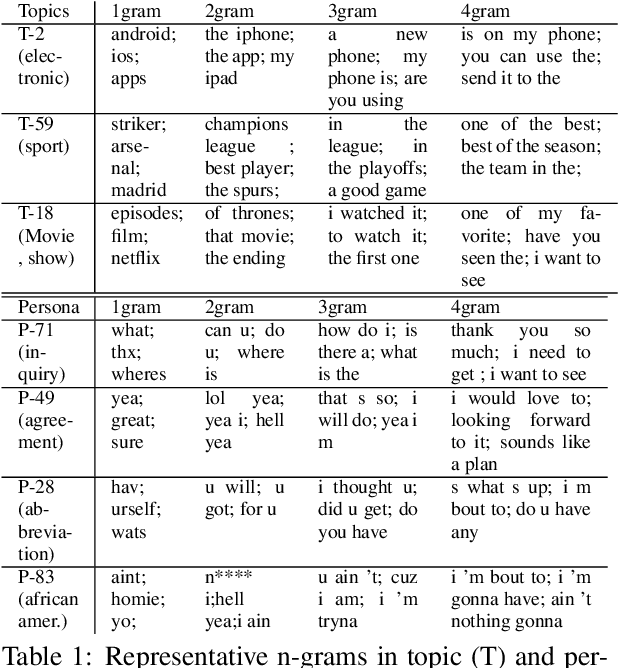
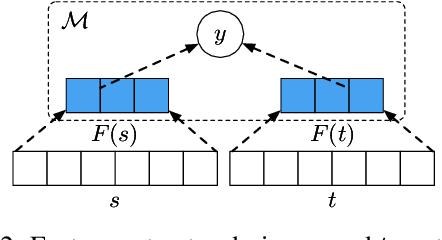
Generating responses that are consistent with the dialogue context is one of the central challenges in building engaging conversational agents. In this paper, we propose a neural conversation model that generates consistent responses by maintaining certain features related to topics and personas throughout the conversation. Unlike past work that requires external supervision such as user identities, which are often unavailable or classified as sensitive information, our approach trains topic and persona feature extractors in a self-supervised way by utilizing the natural structure of dialogue data. Moreover, we adopt a binary feature representation and introduce a feature disentangling loss which, paired with controllable response generation techniques, allows us to promote or demote certain learned topics and personas features. The evaluation result demonstrates the model's capability of capturing meaningful topics and personas features, and the incorporation of the learned features brings significant improvement in terms of the quality of generated responses on two datasets, even comparing with model which explicit persona information.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
Generating Informative and Diverse Conversational Responses via Adversarial Information Maximization
Nov 03, 2018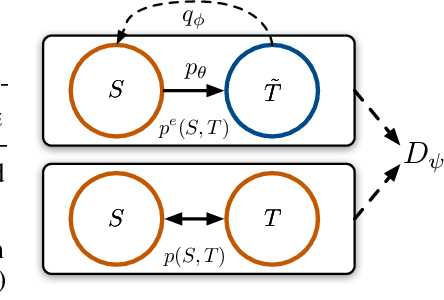
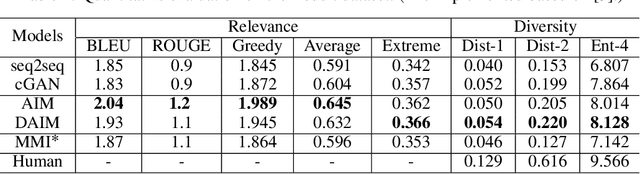

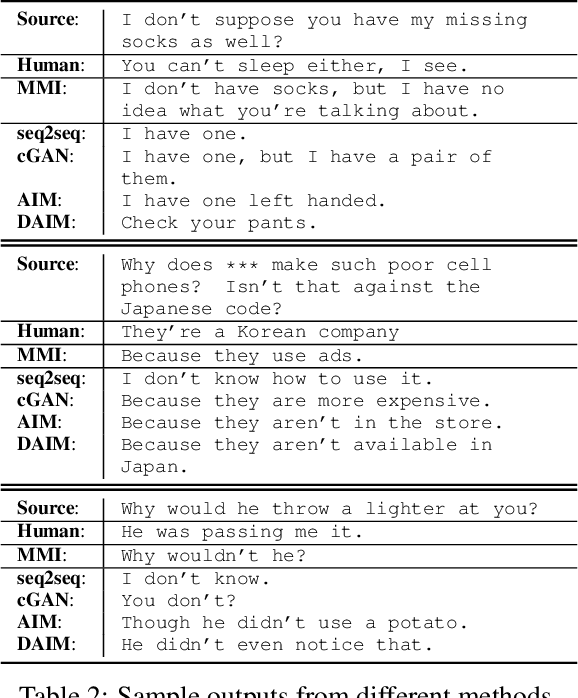
Responses generated by neural conversational models tend to lack informativeness and diversity. We present Adversarial Information Maximization (AIM), an adversarial learning strategy that addresses these two related but distinct problems. To foster response diversity, we leverage adversarial training that allows distributional matching of synthetic and real responses. To improve informativeness, our framework explicitly optimizes a variational lower bound on pairwise mutual information between query and response. Empirical results from automatic and human evaluations demonstrate that our methods significantly boost informativeness and diversity.
A bird's-eye view on coherence, and a worm's-eye view on cohesion
Nov 01, 2018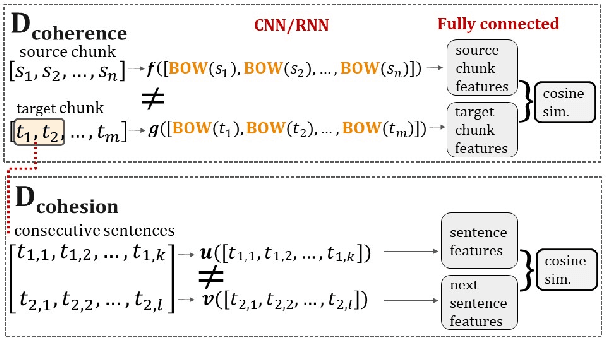
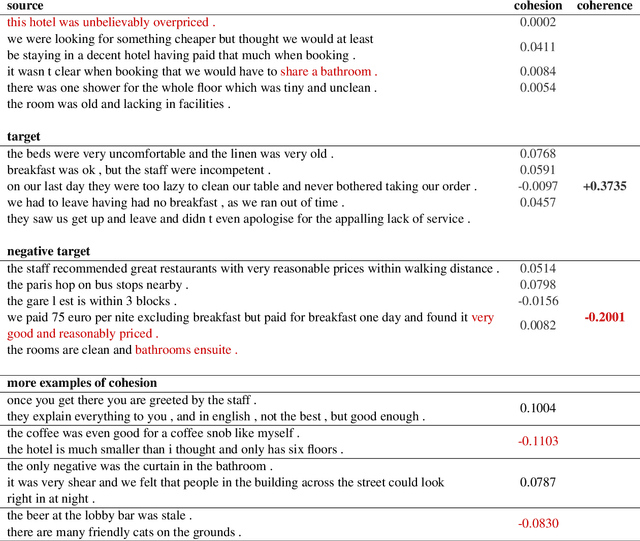


Generating coherent and cohesive long-form texts is a challenging problem in natural language generation. Previous works relied on a large amount of human-generated texts to train language models, however, few attempted to explicitly model the desired linguistic properties of natural language text, such as coherence and cohesion. In this work, we train two expert discriminators for coherence and cohesion, respectively, to provide hierarchical feedback for text generation. We also propose a simple variant of policy gradient, called 'negative-critical sequence training', using margin rewards, in which the 'baseline' is constructed from randomly generated negative samples. We demonstrate the effectiveness of our approach through empirical studies, showing significant improvements over the strong baseline -- attention-based bidirectional MLE-trained neural language model -- in a number of automated metrics. The proposed discriminators can serve as baseline architectures to promote further research to better extract, encode essential linguistic qualities, such as coherence and cohesion.
Neural Approaches to Conversational AI
Sep 21, 2018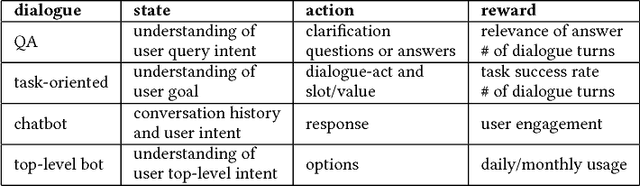
The present paper surveys neural approaches to conversational AI that have been developed in the last few years. We group conversational systems into three categories: (1) question answering agents, (2) task-oriented dialogue agents, and (3) chatbots. For each category, we present a review of state-of-the-art neural approaches, draw the connection between them and traditional approaches, and discuss the progress that has been made and challenges still being faced, using specific systems and models as case studies.
Multi-Task Learning for Speaker-Role Adaptation in Neural Conversation Models
Oct 20, 2017
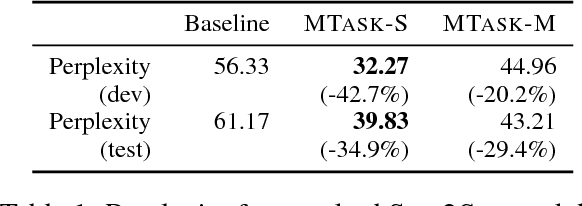
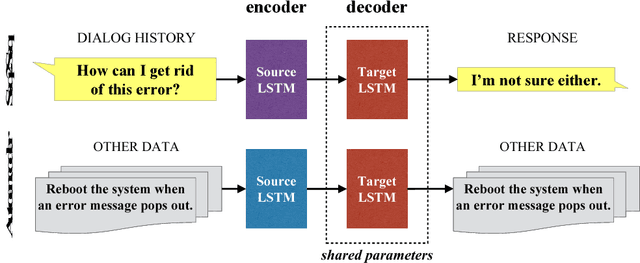
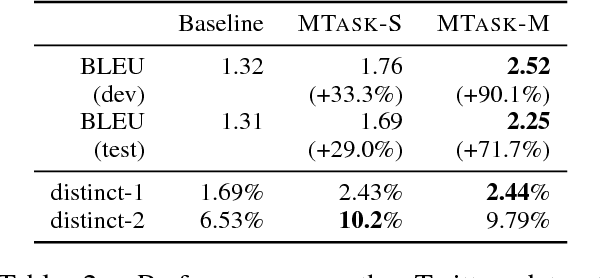
Building a persona-based conversation agent is challenging owing to the lack of large amounts of speaker-specific conversation data for model training. This paper addresses the problem by proposing a multi-task learning approach to training neural conversation models that leverages both conversation data across speakers and other types of data pertaining to the speaker and speaker roles to be modeled. Experiments show that our approach leads to significant improvements over baseline model quality, generating responses that capture more precisely speakers' traits and speaking styles. The model offers the benefits of being algorithmically simple and easy to implement, and not relying on large quantities of data representing specific individual speakers.