 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Bounds for Kernel-Based Reinforcement Learning
Apr 12, 2020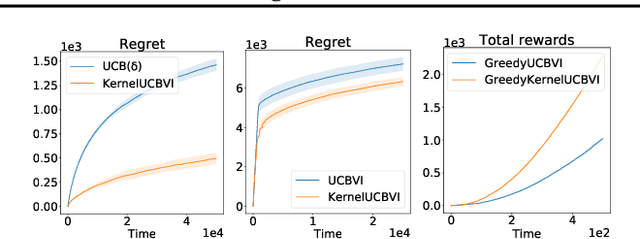

We consider the exploration-exploitation dilemma in finite-horizon reinforcement learning problems whose state-action space is endowed with a metric. We introduce Kernel-UCBVI, a model-based optimistic algorithm that leverages the smoothness of the MDP and a non-parametric kernel estimator of the rewards and transitions to efficiently balance exploration and exploitation. Unlike existing approaches with regret guarantees, it does not use any kind of partitioning of the state-action space. For problems with $K$ episodes and horizon $H$, we provide a regret bound of $O\left( H^3 K^{\max\left(\frac{1}{2}, \frac{2d}{2d+1}\right)}\right)$, where $d$ is the covering dimension of the joint state-action space. We empirically validate Kernel-UCBVI on discrete and continuous MDPs.
Taylor Expansion Policy Optimization
Mar 13, 2020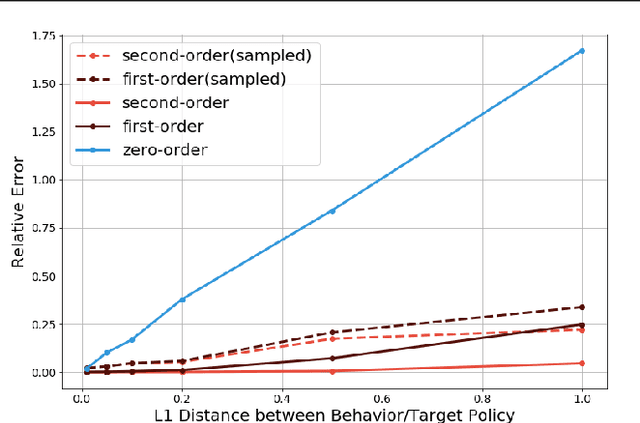
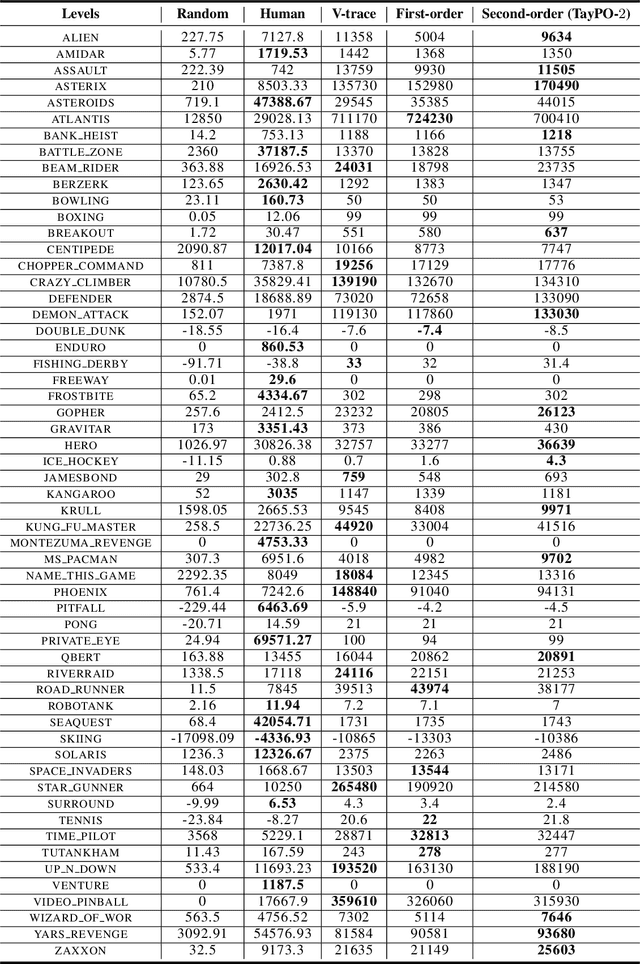
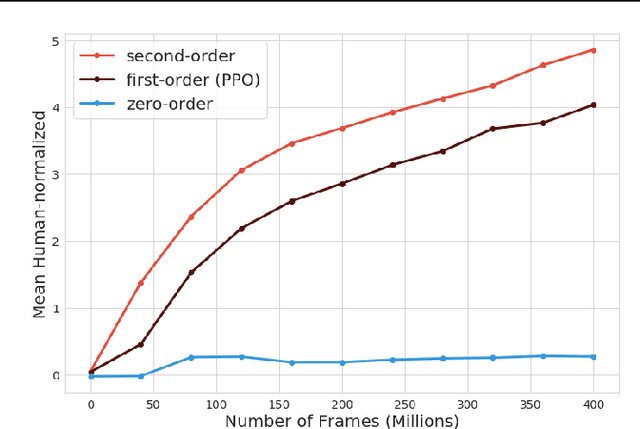
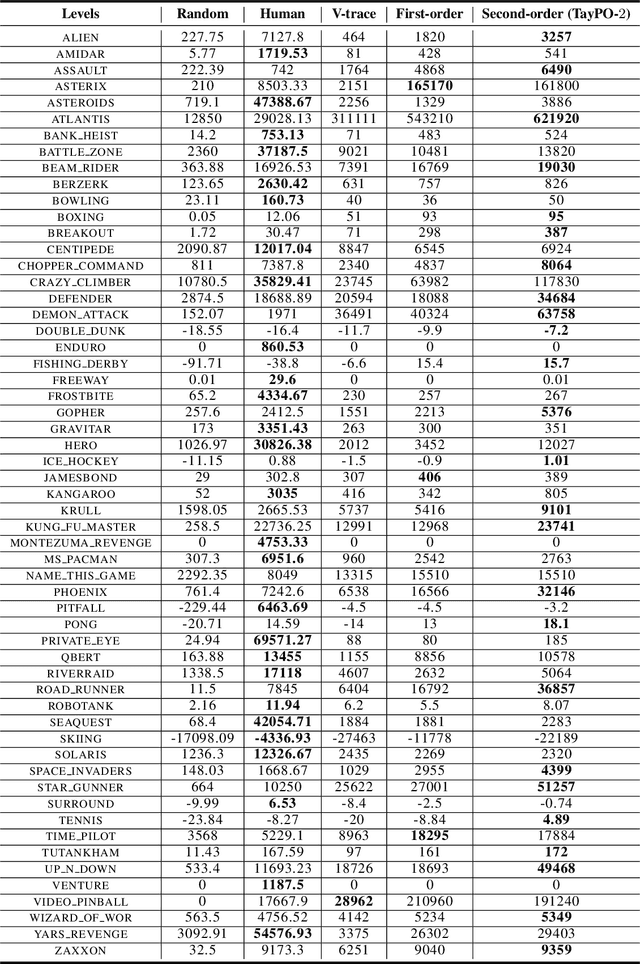
In this work, we investigate the application of Taylor expansions in reinforcement learning. In particular, we propose Taylor expansion policy optimization, a policy optimization formalism that generalizes prior work (e.g., TRPO) as a first-order special case. We also show that Taylor expansions intimately relate to off-policy evaluation. Finally, we show that this new formulation entails modifications which improve the performance of several state-of-the-art distributed algorithms.
Near-linear Time Gaussian Process Optimization with Adaptive Batching and Resparsification
Feb 26, 2020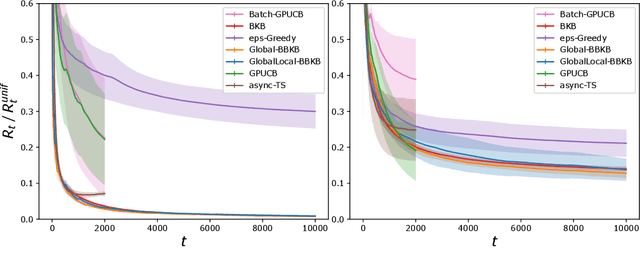
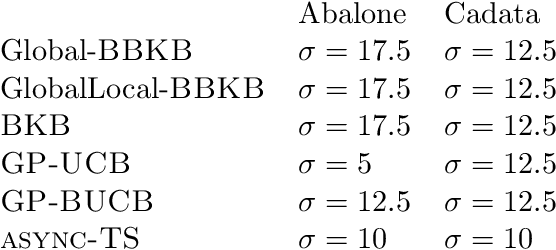
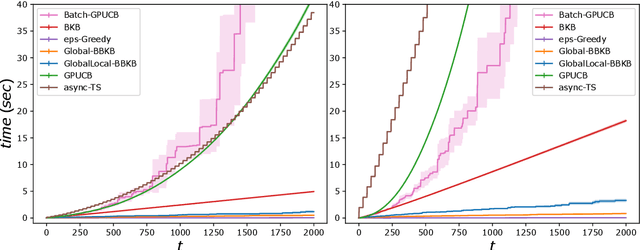
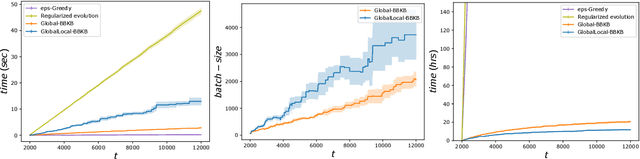
Gaussian processes (GP) are one of the most successful frameworks to model uncertainty. However, GP optimization (e.g., GP-UCB) suffers from major scalability issues. Experimental time grows linearly with the number of evaluations, unless candidates are selected in batches (e.g., using GP-BUCB) and evaluated in parallel. Furthermore, computational cost is often prohibitive since algorithms such as GP-BUCB require a time at least quadratic in the number of dimensions and iterations to select each batch. In this paper, we introduce BBKB (Batch Budgeted Kernel Bandits), the first no-regret GP optimization algorithm that provably runs in near-linear time and selects candidates in batches. This is obtained with a new guarantee for the tracking of the posterior variances that allows BBKB to choose increasingly larger batches, improving over GP-BUCB. Moreover, we show that the same bound can be used to adaptively delay costly updates to the sparse GP approximation used by BBKB, achieving a near-constant per-step amortized cost. These findings are then confirmed in several experiments, where BBKB is much faster than state-of-the-art methods.
No-Regret Exploration in Goal-Oriented Reinforcement Learning
Jan 30, 2020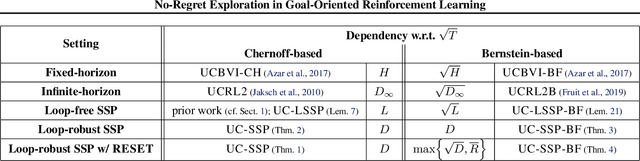
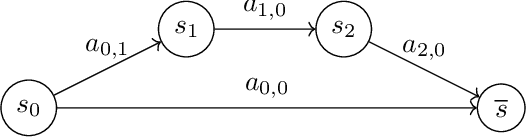

Many popular reinforcement learning problems (e.g., navigation in a maze, some Atari games, mountain car) are instances of the episodic setting under its stochastic shortest path (SSP) formulation, where an agent has to achieve a goal state while minimizing the cumulative cost. Despite the popularity of this setting, the exploration-exploitation dilemma has been sparsely studied in general SSP problems, with most of the theoretical literature focusing on different problems (i.e., fixed-horizon and infinite-horizon) or making the restrictive loop-free SSP assumption (i.e., no state can be visited twice during an episode). In this paper, we study the general SSP problem with no assumption on its dynamics (some policies may actually never reach the goal). We introduce UC-SSP, the first no-regret algorithm in this setting, and prove a regret bound scaling as $\displaystyle \widetilde{\mathcal{O}}( D S \sqrt{ A D K})$ after $K$ episodes for any unknown SSP with $S$ states, $A$ actions, positive costs and SSP-diameter $D$, defined as the smallest expected hitting time from any starting state to the goal. We achieve this result by crafting a novel stopping rule, such that UC-SSP may interrupt the current policy if it is taking too long to achieve the goal and switch to alternative policies that are designed to rapidly terminate the episode.
Multiagent Evaluation under Incomplete Information
Oct 30, 2019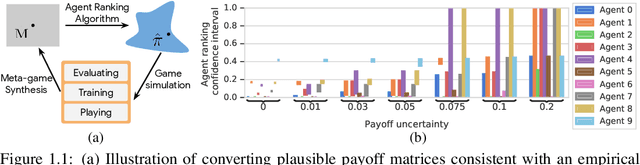
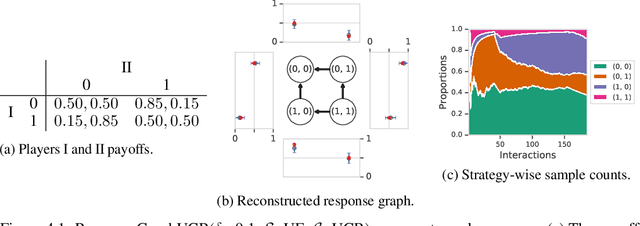
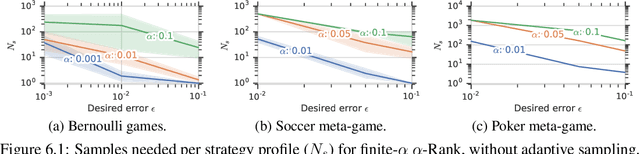
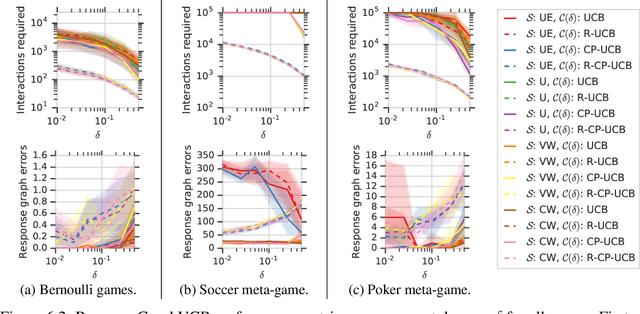
This paper investigates the evaluation of learned multiagent strategies in the incomplete information setting, which plays a critical role in ranking and training of agents. Traditionally, researchers have relied on Elo ratings for this purpose, with recent works also using methods based on Nash equilibria. Unfortunately, Elo is unable to handle intransitive agent interactions, and other techniques are restricted to zero-sum, two-player settings or are limited by the fact that the Nash equilibrium is intractable to compute. Recently, a ranking method called {\alpha}-Rank, relying on a new graph-based game-theoretic solution concept, was shown to tractably apply to general games. However, evaluations based on Elo or {\alpha}-Rank typically assume noise-free game outcomes, despite the data often being collected from noisy simulations, making this assumption unrealistic in practice. This paper investigates multiagent evaluation in the incomplete information regime, involving general-sum many-player games with noisy outcomes. We derive sample complexity guarantees required to confidently rank agents in this setting. We propose adaptive algorithms for accurate ranking, provide correctness and sample complexity guarantees, then introduce a means of connecting uncertainties in noisy match outcomes to uncertainties in rankings. We evaluate the performance of these approaches in several domains, including Bernoulli games, a soccer meta-game, and Kuhn poker.
Fixed-Confidence Guarantees for Bayesian Best-Arm Identification
Oct 28, 2019

We investigate and provide new insights on the sampling rule called Top-Two Thompson Sampling (TTTS). In particular, we justify its use for fixed-confidence best-arm identification. We further propose a variant of TTTS called Top-Two Transportation Cost (T3C), which disposes of the computational burden of TTTS. As our main contribution, we provide the first sample complexity analysis of TTTS and T3C when coupled with a very natural Bayesian stopping rule, for bandits with Gaussian rewards, solving one of the open questions raised by Russo (2016). We also provide new posterior convergence results for TTTS under two models that are commonly used in practice: bandits with Gaussian and Bernoulli rewards and conjugate priors.
Derivative-Free & Order-Robust Optimisation
Oct 22, 2019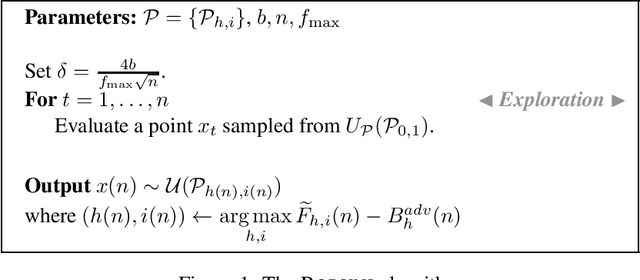
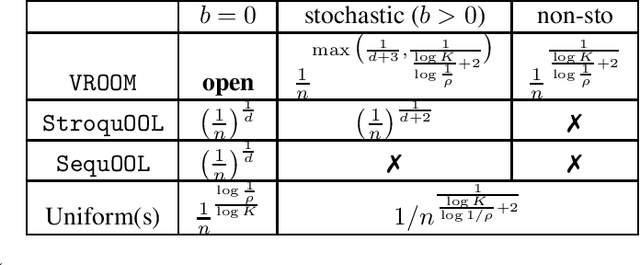

In this paper, we formalise order-robust optimisation as an instance of online learning minimising simple regret, and propose Vroom, a zero'th order optimisation algorithm capable of achieving vanishing regret in non-stationary environments, while recovering favorable rates under stochastic reward-generating processes. Our results are the first to target simple regret definitions in adversarial scenarios unveiling a challenge that has been rarely considered in prior work.
Exact sampling of determinantal point processes with sublinear time preprocessing
May 31, 2019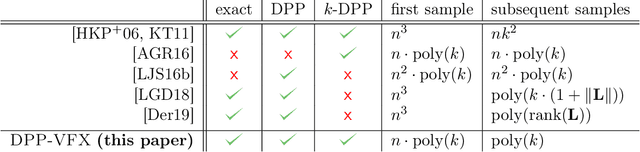
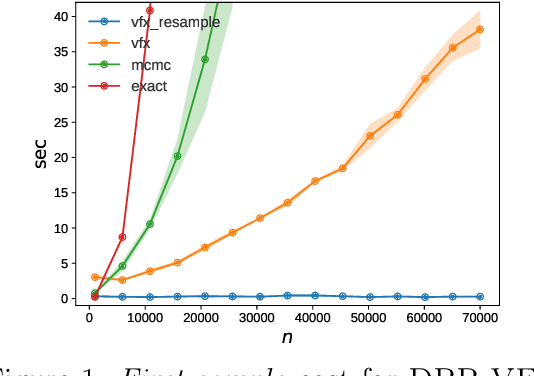
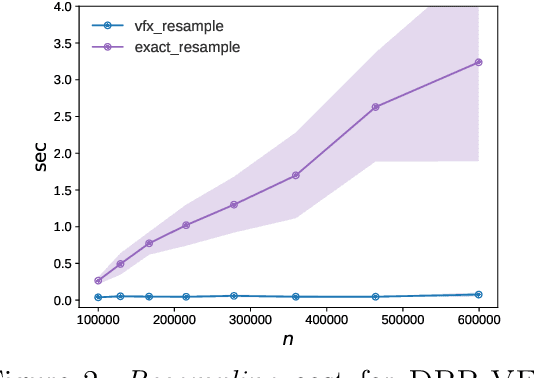
We study the complexity of sampling from a distribution over all index subsets of the set $\{1,...,n\}$ with the probability of a subset $S$ proportional to the determinant of the submatrix $\mathbf{L}_S$ of some $n\times n$ p.s.d. matrix $\mathbf{L}$, where $\mathbf{L}_S$ corresponds to the entries of $\mathbf{L}$ indexed by $S$. Known as a determinantal point process, this distribution is used in machine learning to induce diversity in subset selection. In practice, we often wish to sample multiple subsets $S$ with small expected size $k = E[|S|] \ll n$ from a very large matrix $\mathbf{L}$, so it is important to minimize the preprocessing cost of the procedure (performed once) as well as the sampling cost (performed repeatedly). For this purpose, we propose a new algorithm which, given access to $\mathbf{L}$, samples exactly from a determinantal point process while satisfying the following two properties: (1) its preprocessing cost is $n \cdot \text{poly}(k)$, i.e., sublinear in the size of $\mathbf{L}$, and (2) its sampling cost is $\text{poly}(k)$, i.e., independent of the size of $\mathbf{L}$. Prior to our results, state-of-the-art exact samplers required $O(n^3)$ preprocessing time and sampling time linear in $n$ or dependent on the spectral properties of $\mathbf{L}$. We also give a reduction which allows using our algorithm for exact sampling from cardinality constrained determinantal point processes with $n\cdot\text{poly}(k)$ time preprocessing.
Gaussian Process Optimization with Adaptive Sketching: Scalable and No Regret
Mar 13, 2019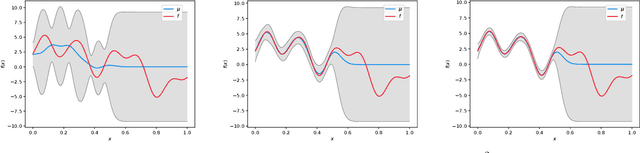
Gaussian processes (GP) are a popular Bayesian approach for the optimization of black-box functions. Despite their effectiveness in simple problems, GP-based algorithms hardly scale to complex high-dimensional functions, as their per-iteration time and space cost is at least quadratic in the number of dimensions $d$ and iterations $t$. Given a set of $A$ alternative to choose from, the overall runtime $O(t^3A)$ quickly becomes prohibitive. In this paper, we introduce BKB (budgeted kernelized bandit), a novel approximate GP algorithm for optimization under bandit feedback that achieves near-optimal regret (and hence near-optimal convergence rate) with near-constant per-iteration complexity and no assumption on the input space or covariance of the GP. Combining a kernelized linear bandit algorithm (GP-UCB) with randomized matrix sketching technique (i.e., leverage score sampling), we prove that selecting inducing points based on their posterior variance gives an accurate low-rank approximation of the GP, preserving variance estimates and confidence intervals. As a consequence, BKB does not suffer from variance starvation, an important problem faced by many previous sparse GP approximations. Moreover, we show that our procedure selects at most $\tilde{O}(d_{eff})$ points, where $d_{eff}$ is the effective dimension of the explored space, which is typically much smaller than both $d$ and $t$. This greatly reduces the dimensionality of the problem, thus leading to a $O(TAd_{eff}^2)$ runtime and $O(A d_{eff})$ space complexity.
Exploiting Structure of Uncertainty for Efficient Combinatorial Semi-Bandits
Feb 11, 2019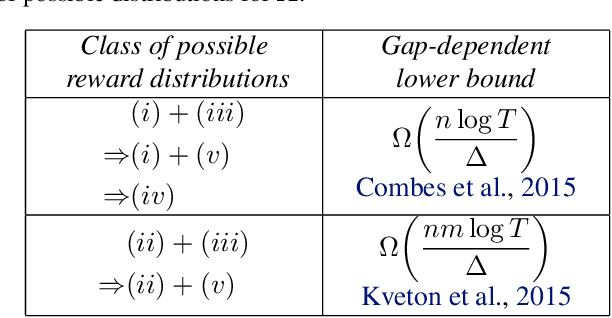
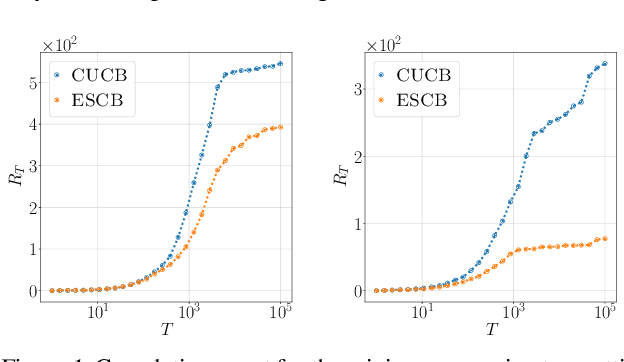

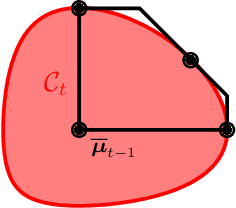
We improve the efficiency of algorithms for stochastic \emph{combinatorial semi-bandits}. In most interesting problems, state-of-the-art algorithms take advantage of structural properties of rewards, such as \emph{independence}. However, while being minimax optimal in terms of regret, these algorithms are intractable. In our paper, we first reduce their implementation to a specific \emph{submodular maximization}. Then, in case of \emph{matroid} constraints, we design adapted approximation routines, thereby providing the first efficient algorithms that exploit the reward structure. In particular, we improve the state-of-the-art efficient gap-free regret bound by a factor $\sqrt{k}$, where $k$ is the maximum action size. Finally, we show how our improvement translates to more general \emph{budgeted combinatorial semi-bandits}.