 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-free adaptive planning for deterministic dynamics & discounted rewards
Apr 20, 2026We address the problem of planning in an environment with deterministic dynamics and stochastic rewards with discounted returns. The optimal value function is not known, nor are the rewards bounded. We propose Platypoos, a simple scale-free planning algorithm that adapts to the unknown scale and smoothness of the reward function. We provide a sample complexity analysis for Platypoos that improves upon prior work and holds simultaneously over a broad range of discount factors and reward scales, without the algorithm knowing them. We also establish a matching lower bound showing our analysis is optimal up to constants.
* 36th International Conference on Machine Learning (ICML 2019)
Best of both worlds: Stochastic & adversarial best-arm identification
Apr 16, 2026We study bandit best-arm identification with arbitrary and potentially adversarial rewards. A simple random uniform learner obtains the optimal rate of error in the adversarial scenario. However, this type of strategy is suboptimal when the rewards are sampled stochastically. Therefore, we ask: Can we design a learner that performs optimally in both the stochastic and adversarial problems while not being aware of the nature of the rewards? First, we show that designing such a learner is impossible in general. In particular, to be robust to adversarial rewards, we can only guarantee optimal rates of error on a subset of the stochastic problems. We give a lower bound that characterizes the optimal rate in stochastic problems if the strategy is constrained to be robust to adversarial rewards. Finally, we design a simple parameter-free algorithm and show that its probability of error matches (up to log factors) the lower bound in stochastic problems, and it is also robust to adversarial ones.
Derivative-Free & Order-Robust Optimisation
Oct 22, 2019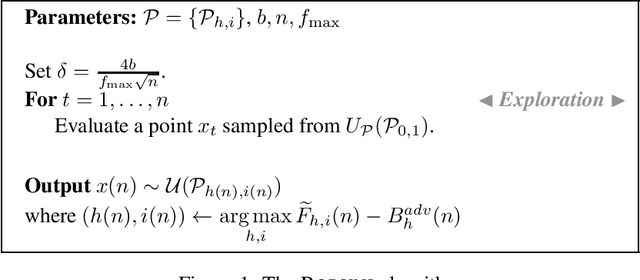
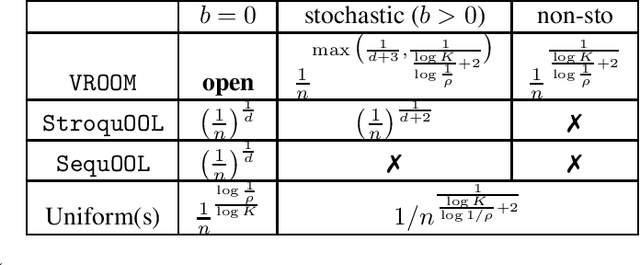

In this paper, we formalise order-robust optimisation as an instance of online learning minimising simple regret, and propose Vroom, a zero'th order optimisation algorithm capable of achieving vanishing regret in non-stationary environments, while recovering favorable rates under stochastic reward-generating processes. Our results are the first to target simple regret definitions in adversarial scenarios unveiling a challenge that has been rarely considered in prior work.
MANAS: Multi-Agent Neural Architecture Search
Sep 05, 2019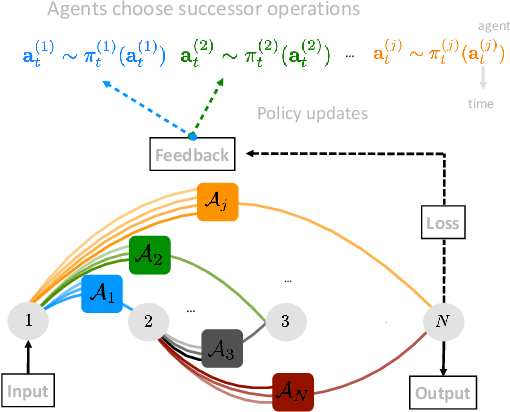
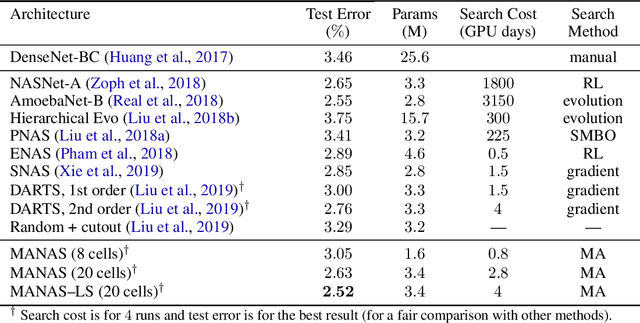
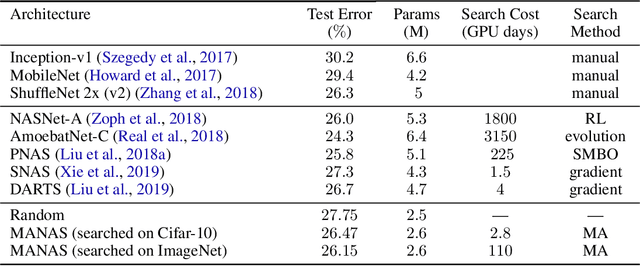
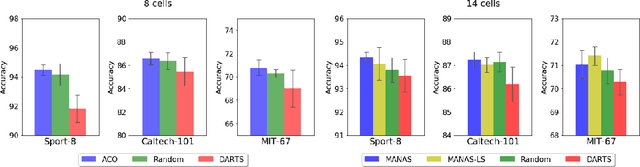
The Neural Architecture Search (NAS) problem is typically formulated as a graph search problem where the goal is to learn the optimal operations over edges in order to maximise a graph-level global objective. Due to the large architecture parameter space, efficiency is a key bottleneck preventing NAS from its practical use. In this paper, we address the issue by framing NAS as a multi-agent problem where agents control a subset of the network and coordinate to reach optimal architectures. We provide two distinct lightweight implementations, with reduced memory requirements (1/8th of state-of-the-art), and performances above those of much more computationally expensive methods. Theoretically, we demonstrate vanishing regrets of the form O(sqrt(T)), with T being the total number of rounds. Finally, aware that random search is an, often ignored, effective baseline we perform additional experiments on 3 alternative datasets and 2 network configurations, and achieve favourable results in comparison.
A simple parameter-free and adaptive approach to optimization under a minimal local smoothness assumption
Oct 01, 2018
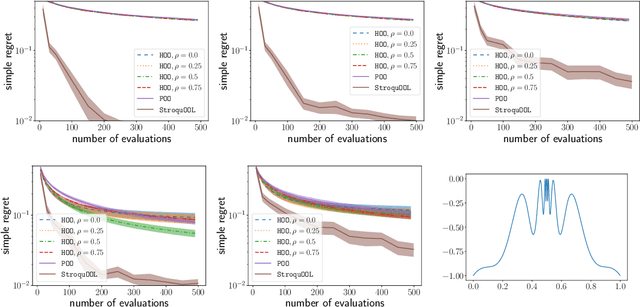
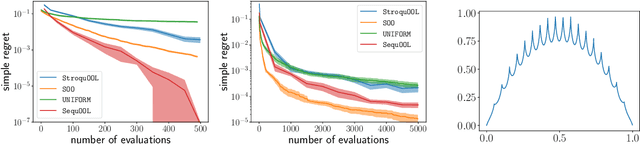
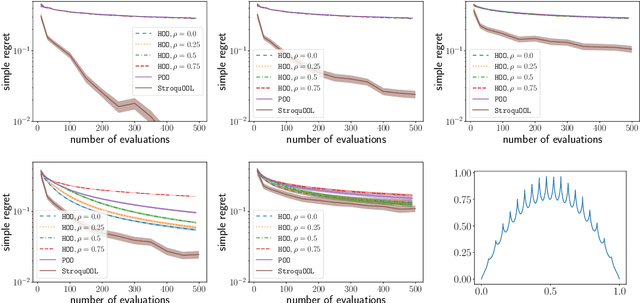
We study the problem of optimizing a function under a \emph{budgeted number of evaluations}. We only assume that the function is \emph{locally} smooth around one of its global optima. The difficulty of optimization is measured in terms of 1) the amount of \emph{noise} $b$ of the function evaluation and 2) the local smoothness, $d$, of the function. A smaller $d$ results in smaller optimization error. We come with a new, simple, and parameter-free approach. First, for all values of $b$ and $d$, this approach recovers at least the state-of-the-art regret guarantees. Second, our approach additionally obtains these results while being \textit{agnostic} to the values of both $b$ and $d$. This leads to the first algorithm that naturally adapts to an \textit{unknown} range of noise $b$ and leads to significant improvements in a moderate and low-noise regime. Third, our approach also obtains a remarkable improvement over the state-of-the-art \SOO algorithm when the noise is very low which includes the case of optimization under deterministic feedback ($b=0$). There, under our minimal local smoothness assumption, this improvement is of exponential magnitude and holds for a class of functions that covers the vast majority of functions that practitioners optimize ($d=0$). We show that our algorithmic improvement is also borne out in the numerical experiments, where we empirically show faster convergence on common benchmark functions.
Hit-and-Run for Sampling and Planning in Non-Convex Spaces
Oct 19, 2016
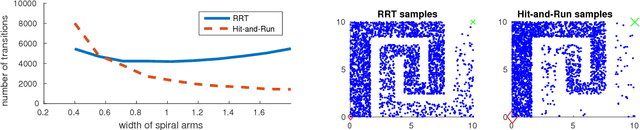
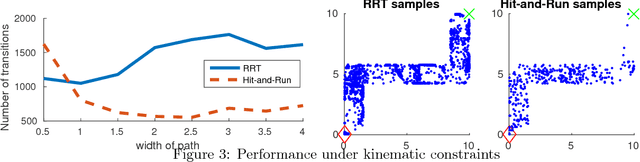
We propose the Hit-and-Run algorithm for planning and sampling problems in non-convex spaces. For sampling, we show the first analysis of the Hit-and-Run algorithm in non-convex spaces and show that it mixes fast as long as certain smoothness conditions are satisfied. In particular, our analysis reveals an intriguing connection between fast mixing and the existence of smooth measure-preserving mappings from a convex space to the non-convex space. For planning, we show advantages of Hit-and-Run compared to state-of-the-art planning methods such as Rapidly-Exploring Random Trees.
Approximate Modified Policy Iteration
May 18, 2012
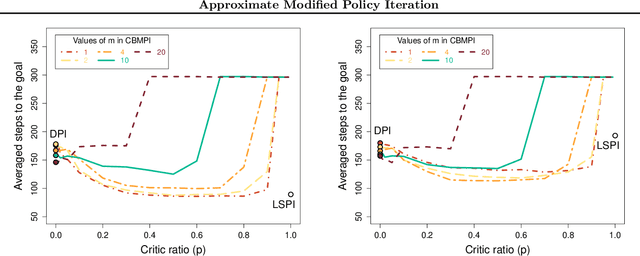
Modified policy iteration (MPI) is a dynamic programming (DP) algorithm that contains the two celebrated policy and value iteration methods. Despite its generality, MPI has not been thoroughly studied, especially its approximation form which is used when the state and/or action spaces are large or infinite. In this paper, we propose three implementations of approximate MPI (AMPI) that are extensions of well-known approximate DP algorithms: fitted-value iteration, fitted-Q iteration, and classification-based policy iteration. We provide error propagation analyses that unify those for approximate policy and value iteration. On the last classification-based implementation, we develop a finite-sample analysis that shows that MPI's main parameter allows to control the balance between the estimation error of the classifier and the overall value function approximation.