 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Speech-Language Joint Pre-Training for Spoken Language Understanding
Oct 05, 2020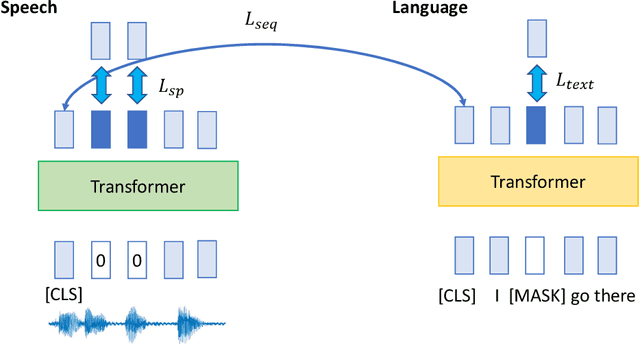
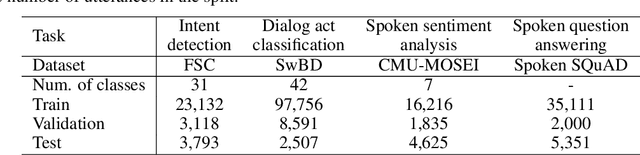

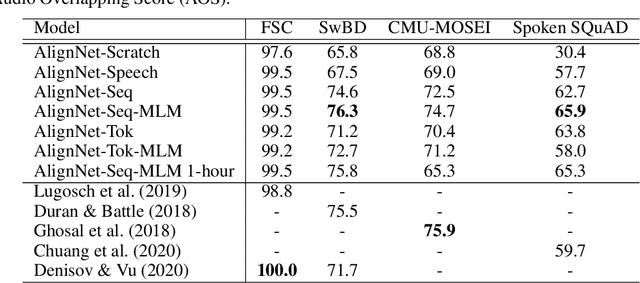
Spoken language understanding (SLU) requires a model to analyze input acoustic signals to understand its linguistic content and make predictions. To boost the models' performance, various pre-training methods have been proposed to utilize large-scale unlabeled text and speech data. However, the inherent disparities between the two modalities necessitate a mutual analysis. In this paper, we propose a novel semi-supervised learning method, AlignNet, to jointly pre-train the speech and language modules. Besides a self-supervised masked language modeling of the two individual modules, AlignNet aligns representations from paired speech and transcripts in a shared latent semantic space. Thus, during fine-tuning, the speech module alone can produce representations carrying both acoustic information and contextual semantic knowledge. Experimental results verify the effectiveness of our approach on various SLU tasks. For example, AlignNet improves the previous state-of-the-art accuracy on the Spoken SQuAD dataset by 6.2%.
JAKET: Joint Pre-training of Knowledge Graph and Language Understanding
Oct 02, 2020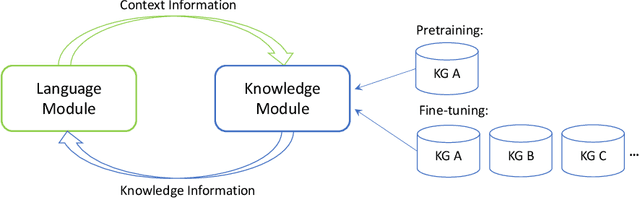
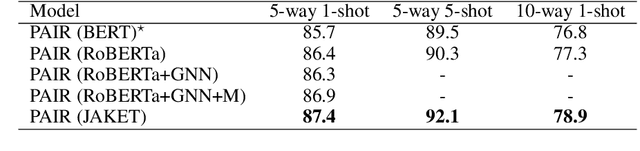
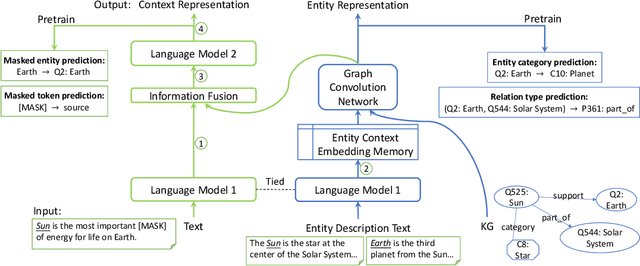
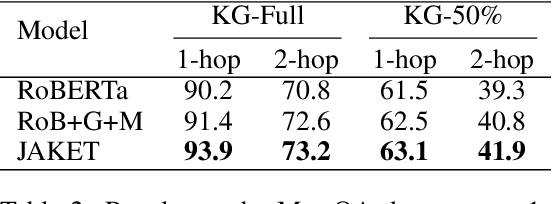
Knowledge graphs (KGs) contain rich information about world knowledge, entities and relations. Thus, they can be great supplements to existing pre-trained language models. However, it remains a challenge to efficiently integrate information from KG into language modeling. And the understanding of a knowledge graph requires related context. We propose a novel joint pre-training framework, JAKET, to model both the knowledge graph and language. The knowledge module and language module provide essential information to mutually assist each other: the knowledge module produces embeddings for entities in text while the language module generates context-aware initial embeddings for entities and relations in the graph. Our design enables the pre-trained model to easily adapt to unseen knowledge graphs in new domains. Experimental results on several knowledge-aware NLP tasks show that our proposed framework achieves superior performance by effectively leveraging knowledge in language understanding.
Mind The Facts: Knowledge-Boosted Coherent Abstractive Text Summarization
Jun 27, 2020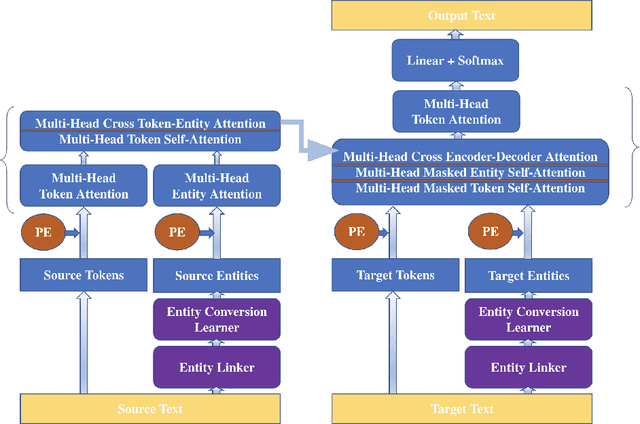


Neural models have become successful at producing abstractive summaries that are human-readable and fluent. However, these models have two critical shortcomings: they often don't respect the facts that are either included in the source article or are known to humans as commonsense knowledge, and they don't produce coherent summaries when the source article is long. In this work, we propose a novel architecture that extends Transformer encoder-decoder architecture in order to improve on these shortcomings. First, we incorporate entity-level knowledge from the Wikidata knowledge graph into the encoder-decoder architecture. Injecting structural world knowledge from Wikidata helps our abstractive summarization model to be more fact-aware. Second, we utilize the ideas used in Transformer-XL language model in our proposed encoder-decoder architecture. This helps our model with producing coherent summaries even when the source article is long. We test our model on CNN/Daily Mail summarization dataset and show improvements on ROUGE scores over the baseline Transformer model. We also include model predictions for which our model accurately conveys the facts, while the baseline Transformer model doesn't.
Meta Dialogue Policy Learning
Jun 03, 2020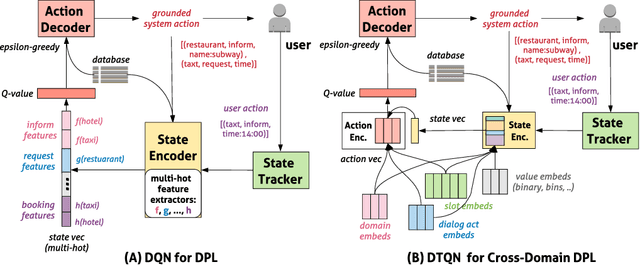
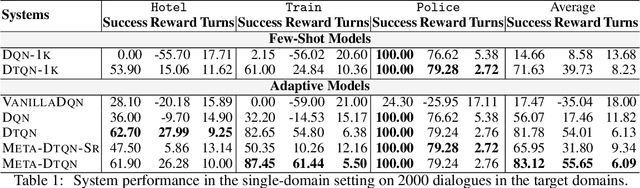
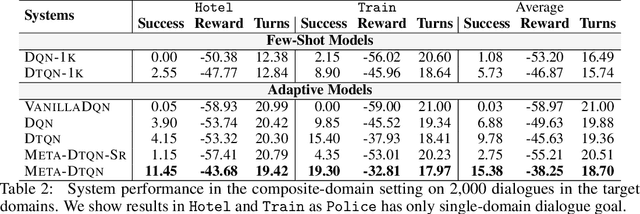
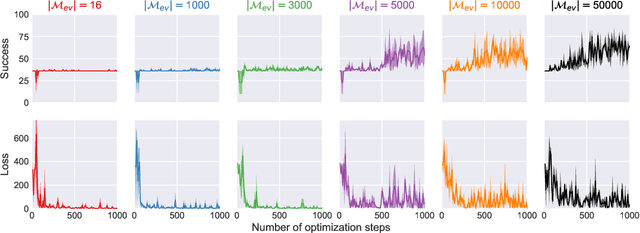
Dialog policy determines the next-step actions for agents and hence is central to a dialogue system. However, when migrated to novel domains with little data, a policy model can fail to adapt due to insufficient interactions with the new environment. We propose Deep Transferable Q-Network (DTQN) to utilize shareable low-level signals between domains, such as dialogue acts and slots. We decompose the state and action representation space into feature subspaces corresponding to these low-level components to facilitate cross-domain knowledge transfer. Furthermore, we embed DTQN in a meta-learning framework and introduce Meta-DTQN with a dual-replay mechanism to enable effective off-policy training and adaptation. In experiments, our model outperforms baseline models in terms of both success rate and dialogue efficiency on the multi-domain dialogue dataset MultiWOZ 2.0.
Data Augmentation for Spoken Language Understanding via Pretrained Models
Apr 29, 2020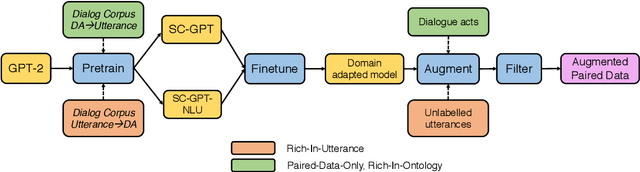
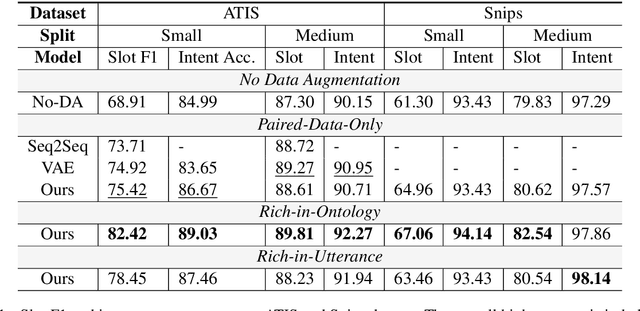
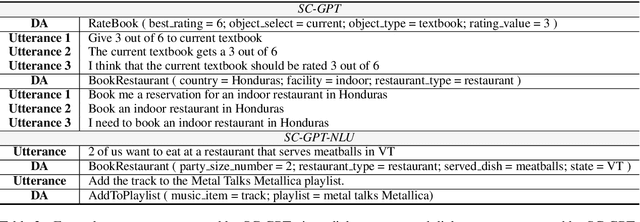
The training of spoken language understanding (SLU) models often faces the problem of data scarcity. In this paper, we put forward a data augmentation method with pretrained language models to boost the variability and accuracy of generated utterances. Furthermore, we investigate and propose solutions to two previously overlooked scenarios of data scarcity in SLU: i) Rich-in-Ontology: ontology information with numerous valid dialogue acts are given; ii) Rich-in-Utterance: a large number of unlabelled utterances are available. Empirical results show that our method can produce synthetic training data that boosts the performance of language understanding models in various scenarios.
End-to-End Abstractive Summarization for Meetings
Apr 22, 2020
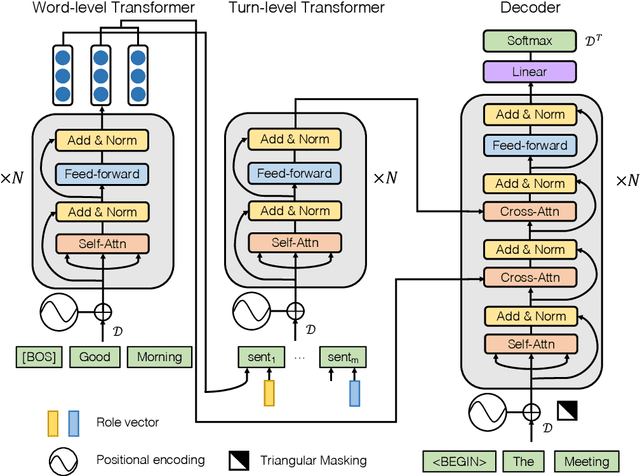
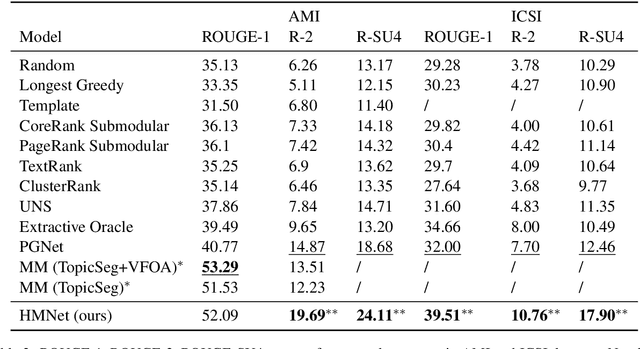
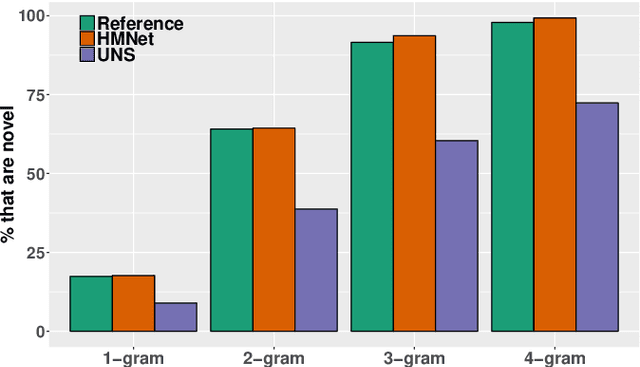
With the abundance of automatic meeting transcripts, meeting summarization is of great interest to both participants and other parties. Traditional methods of summarizing meetings depend on complex multi-step pipelines that make joint optimization intractable. Meanwhile, there are a handful of deep neural models for text summarization and dialogue systems. However, the semantic structure and styles of meeting transcripts are quite different from articles and conversations. In this paper, we propose a novel end-to-end abstractive summary network that adapts to the meeting scenario. We design a role vector to depict the difference among speakers and a hierarchical structure to accommodate long meeting transcripts. Empirical results show that our model considerably outperforms previous approaches in both automatic metrics and human evaluation. For example, in the ICSI dataset, the ROUGE-1 score increases from 32.00% to 39.51%.
Improving Readability for Automatic Speech Recognition Transcription
Apr 09, 2020
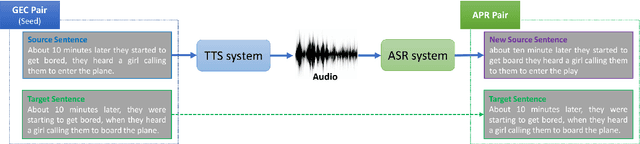
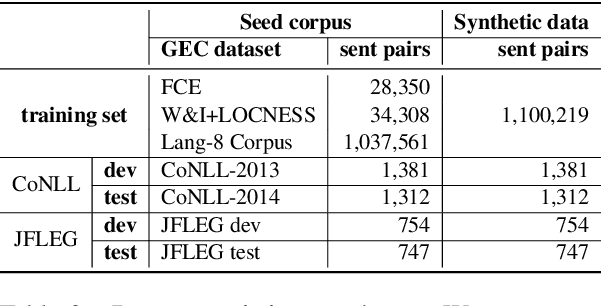
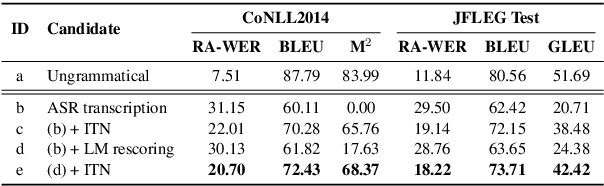
Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to grammatical errors, disfluency, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose a novel NLP task called ASR post-processing for readability (APR) that aims to transform the noisy ASR output into a readable text for humans and downstream tasks while maintaining the semantic meaning of the speaker. In addition, we describe a method to address the lack of task-specific data by synthesizing examples for the APR task using the datasets collected for Grammatical Error Correction (GEC) followed by text-to-speech (TTS) and ASR. Furthermore, we propose metrics borrowed from similar tasks to evaluate performance on the APR task. We compare fine-tuned models based on several open-sourced and adapted pre-trained models with the traditional pipeline method. Our results suggest that finetuned models improve the performance on the APR task significantly, hinting at the potential benefits of using APR systems. We hope that the read, understand, and rewrite approach of our work can serve as a basis that many NLP tasks and human readers can benefit from.
Boosting Factual Correctness of Abstractive Summarization
Apr 04, 2020
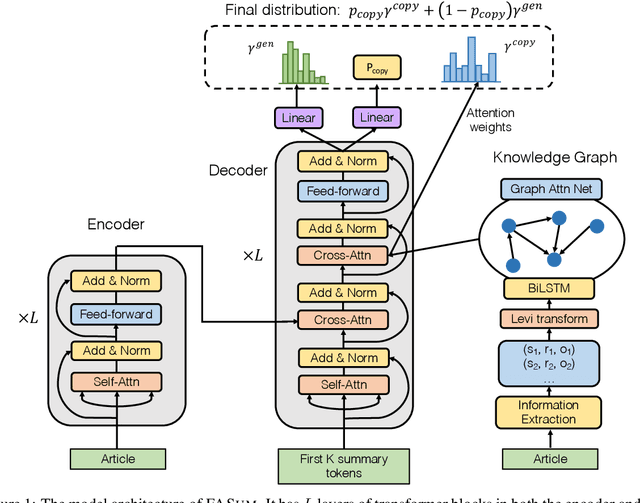
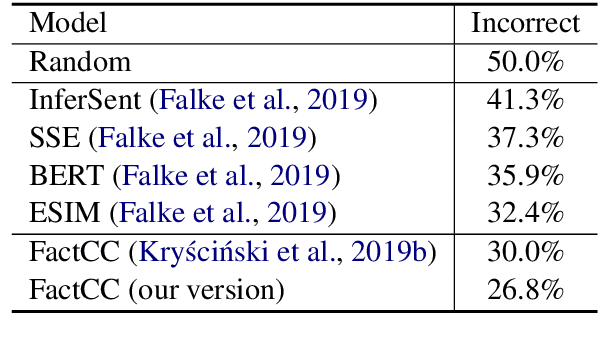
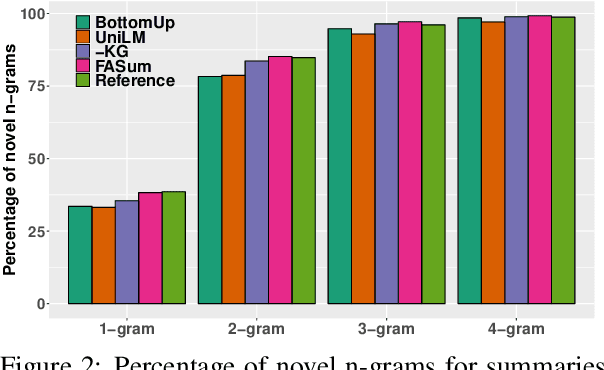
A commonly observed problem with abstractive summarization is the distortion or fabrication of factual information in the article. This inconsistency between summary and original text has led to various concerns over its applicability. In this paper, we firstly propose a Fact-Aware Summarization model, FASum, which extracts factual relations from the article and integrates this knowledge into the decoding process via neural graph computation. Then, we propose a Factual Corrector model, FC, that can modify abstractive summaries generated by any model to improve factual correctness. Empirical results show that FASum generates summaries with significantly higher factual correctness compared with state-of-the-art abstractive summarization systems, both under an independently trained factual correctness evaluator and human evaluation. And FC improves the factual correctness of summaries generated by various models via only modifying several entity tokens.
Few-shot Natural Language Generation for Task-Oriented Dialog
Feb 27, 2020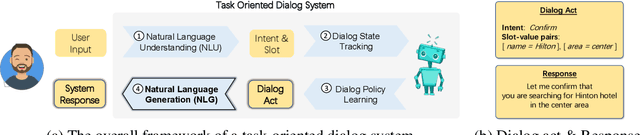
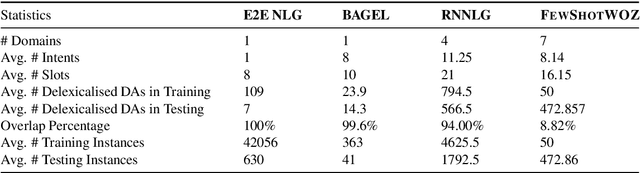
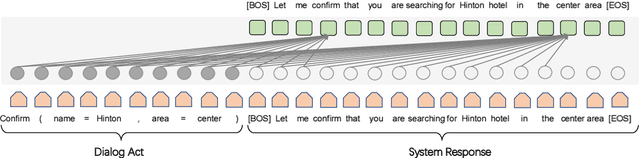
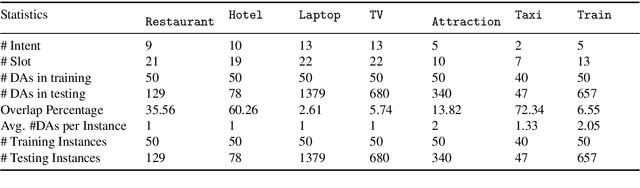
As a crucial component in task-oriented dialog systems, the Natural Language Generation (NLG) module converts a dialog act represented in a semantic form into a response in natural language. The success of traditional template-based or statistical models typically relies on heavily annotated data, which is infeasible for new domains. Therefore, it is pivotal for an NLG system to generalize well with limited labelled data in real applications. To this end, we present FewShotWoz, the first NLG benchmark to simulate the few-shot learning setting in task-oriented dialog systems. Further, we develop the SC-GPT model. It is pre-trained on a large set of annotated NLG corpus to acquire the controllable generation ability, and fine-tuned with only a few domain-specific labels to adapt to new domains. Experiments on FewShotWoz and the large Multi-Domain-WOZ datasets show that the proposed SC-GPT significantly outperforms existing methods, measured by various automatic metrics and human evaluations.
Make Lead Bias in Your Favor: A Simple and Effective Method for News Summarization
Jan 07, 2020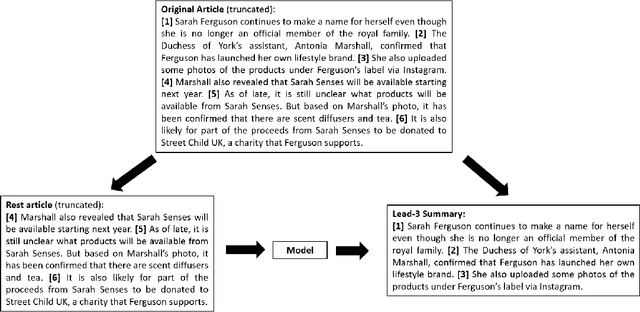
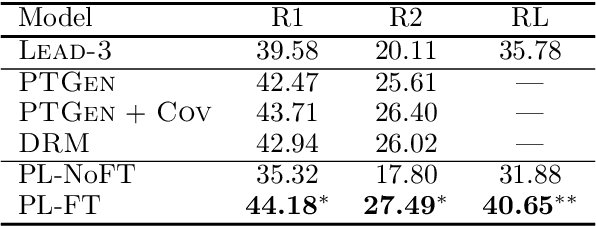
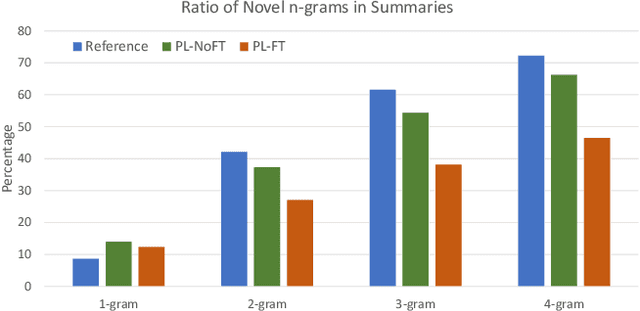
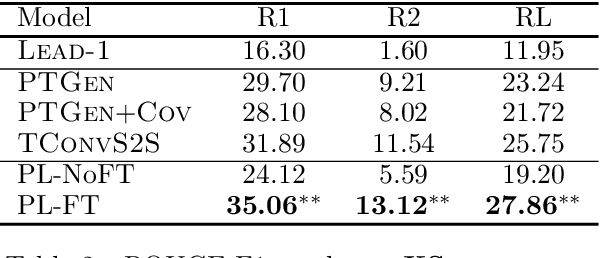
Lead bias is a common phenomenon in news summarization, where early parts of an article often contain the most salient information. While many algorithms exploit this fact in summary generation, it has a detrimental effect on teaching the model to discriminate and extract important information. We propose that the lead bias can be leveraged in a simple and effective way in our favor to pretrain abstractive news summarization models on large-scale unlabeled corpus: predicting the leading sentences using the rest of an article. Via careful data cleaning and filtering, our transformer-based pretrained model without any finetuning achieves remarkable results over various news summarization tasks. With further finetuning, our model outperforms many competitive baseline models. Human evaluations further show the effectiveness of our method.