 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Distributed Statistical Inference
Nov 06, 2016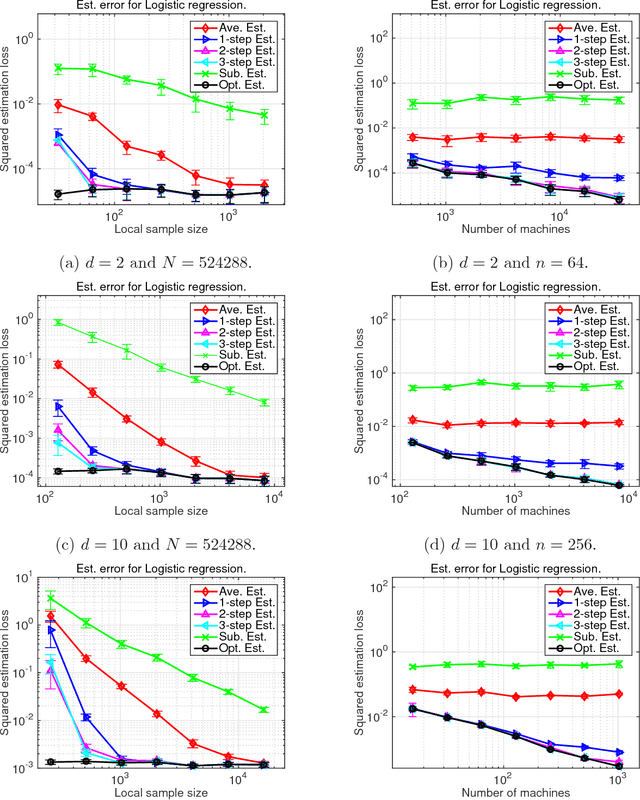
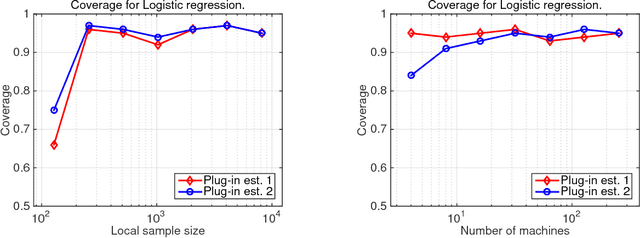
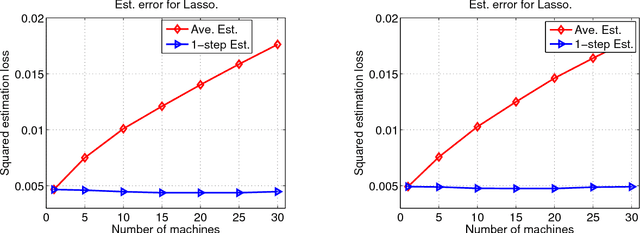
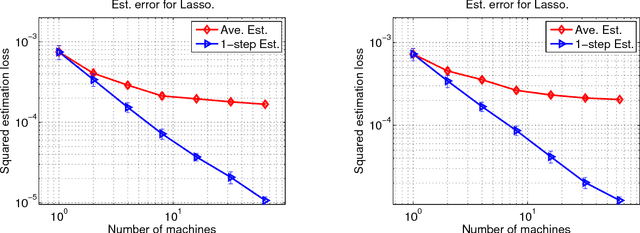
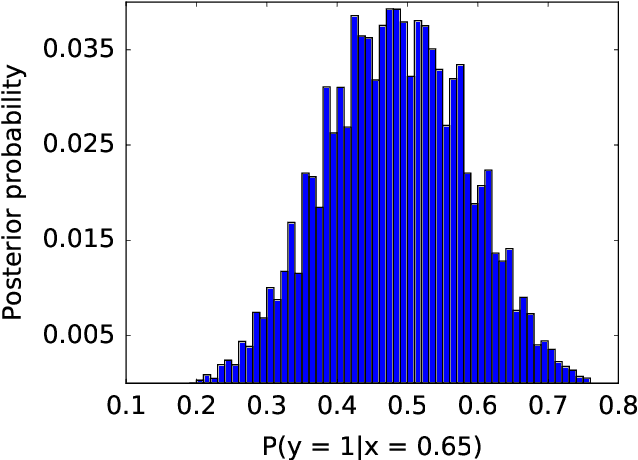
We present a Communication-efficient Surrogate Likelihood (CSL) framework for solving distributed statistical inference problems. CSL provides a communication-efficient surrogate to the global likelihood that can be used for low-dimensional estimation, high-dimensional regularized estimation and Bayesian inference. For low-dimensional estimation, CSL provably improves upon naive averaging schemes and facilitates the construction of confidence intervals. For high-dimensional regularized estimation, CSL leads to a minimax-optimal estimator with controlled communication cost. For Bayesian inference, CSL can be used to form a communication-efficient quasi-posterior distribution that converges to the true posterior. This quasi-posterior procedure significantly improves the computational efficiency of MCMC algorithms even in a non-distributed setting. We present both theoretical analysis and experiments to explore the properties of the CSL approximation.
Function-Specific Mixing Times and Concentration Away from Equilibrium
Sep 30, 2016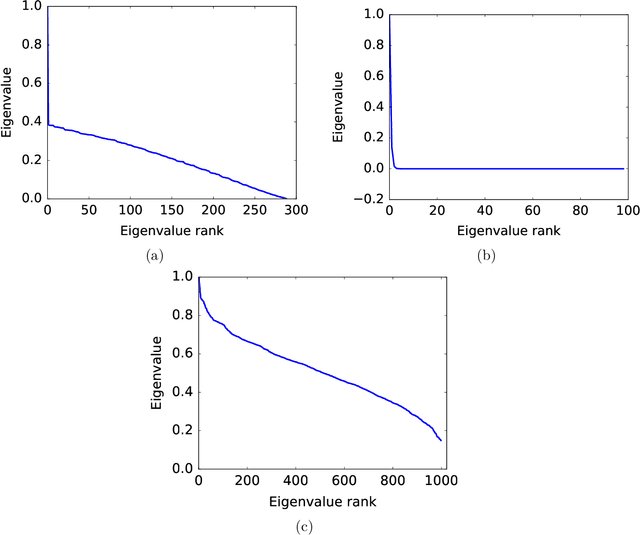
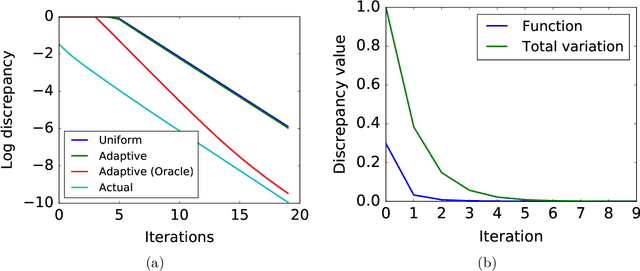
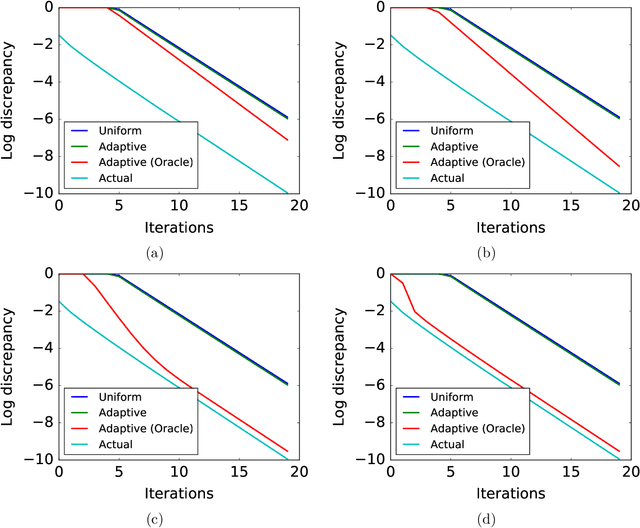
Slow mixing is the central hurdle when working with Markov chains, especially those used for Monte Carlo approximations (MCMC). In many applications, it is only of interest to estimate the stationary expectations of a small set of functions, and so the usual definition of mixing based on total variation convergence may be too conservative. Accordingly, we introduce function-specific analogs of mixing times and spectral gaps, and use them to prove Hoeffding-like function-specific concentration inequalities. These results show that it is possible for empirical expectations of functions to concentrate long before the underlying chain has mixed in the classical sense, and we show that the concentration rates we achieve are optimal up to constants. We use our techniques to derive confidence intervals that are sharper than those implied by both classical Markov chain Hoeffding bounds and Berry-Esseen-corrected CLT bounds. For applications that require testing, rather than point estimation, we show similar improvements over recent sequential testing results for MCMC. We conclude by applying our framework to real data examples of MCMC, providing evidence that our theory is both accurate and relevant to practice.
Distributed Optimization with Arbitrary Local Solvers
Aug 03, 2016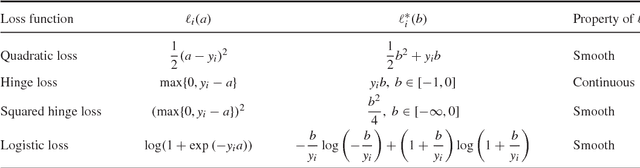
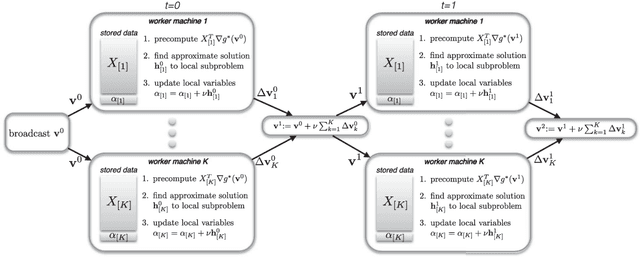

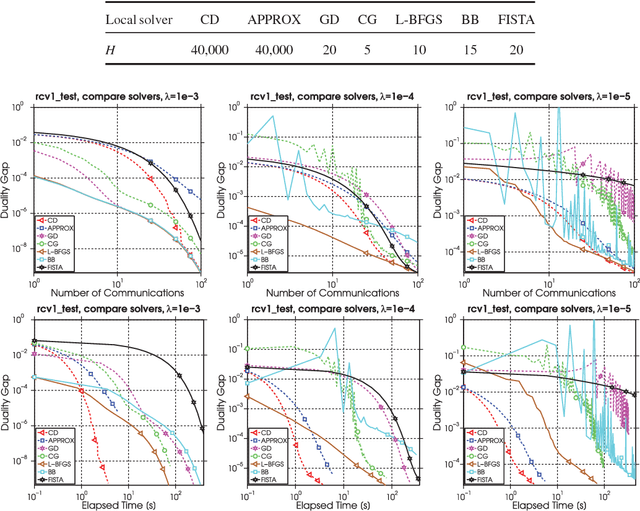
With the growth of data and necessity for distributed optimization methods, solvers that work well on a single machine must be re-designed to leverage distributed computation. Recent work in this area has been limited by focusing heavily on developing highly specific methods for the distributed environment. These special-purpose methods are often unable to fully leverage the competitive performance of their well-tuned and customized single machine counterparts. Further, they are unable to easily integrate improvements that continue to be made to single machine methods. To this end, we present a framework for distributed optimization that both allows the flexibility of arbitrary solvers to be used on each (single) machine locally, and yet maintains competitive performance against other state-of-the-art special-purpose distributed methods. We give strong primal-dual convergence rate guarantees for our framework that hold for arbitrary local solvers. We demonstrate the impact of local solver selection both theoretically and in an extensive experimental comparison. Finally, we provide thorough implementation details for our framework, highlighting areas for practical performance gains.
A Kernelized Stein Discrepancy for Goodness-of-fit Tests and Model Evaluation
Jul 01, 2016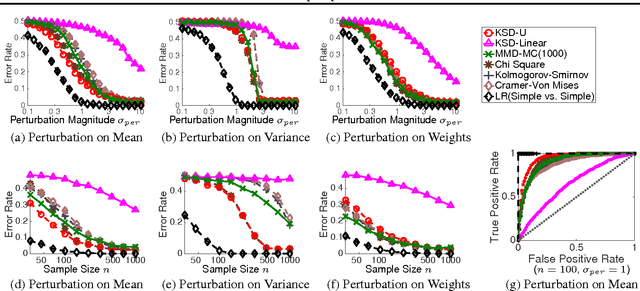
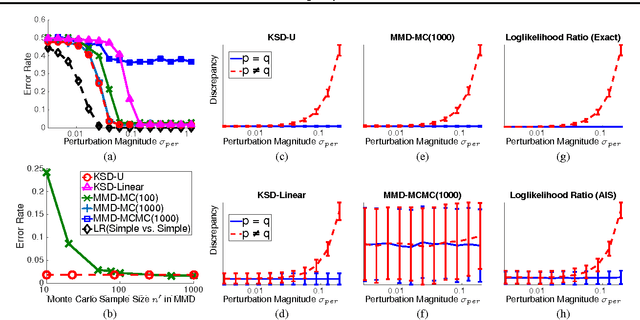
We derive a new discrepancy statistic for measuring differences between two probability distributions based on combining Stein's identity with the reproducing kernel Hilbert space theory. We apply our result to test how well a probabilistic model fits a set of observations, and derive a new class of powerful goodness-of-fit tests that are widely applicable for complex and high dimensional distributions, even for those with computationally intractable normalization constants. Both theoretical and empirical properties of our methods are studied thoroughly.
L1-Regularized Distributed Optimization: A Communication-Efficient Primal-Dual Framework
Jun 02, 2016
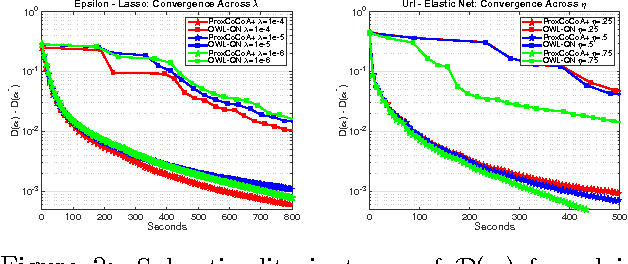
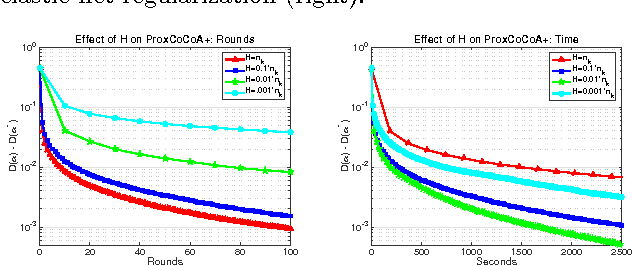
Despite the importance of sparsity in many large-scale applications, there are few methods for distributed optimization of sparsity-inducing objectives. In this paper, we present a communication-efficient framework for L1-regularized optimization in the distributed environment. By viewing classical objectives in a more general primal-dual setting, we develop a new class of methods that can be efficiently distributed and applied to common sparsity-inducing models, such as Lasso, sparse logistic regression, and elastic net-regularized problems. We provide theoretical convergence guarantees for our framework, and demonstrate its efficiency and flexibility with a thorough experimental comparison on Amazon EC2. Our proposed framework yields speedups of up to 50x as compared to current state-of-the-art methods for distributed L1-regularized optimization.
CYCLADES: Conflict-free Asynchronous Machine Learning
May 31, 2016
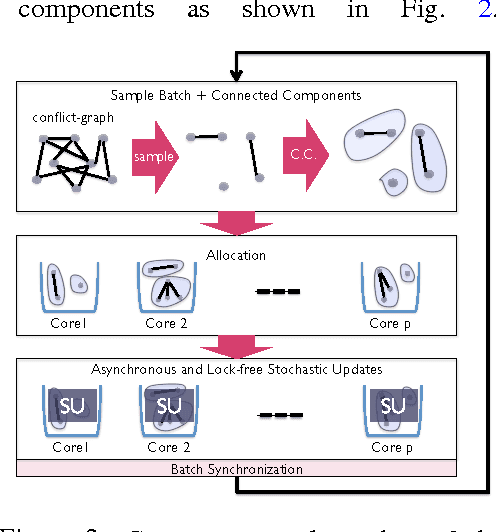

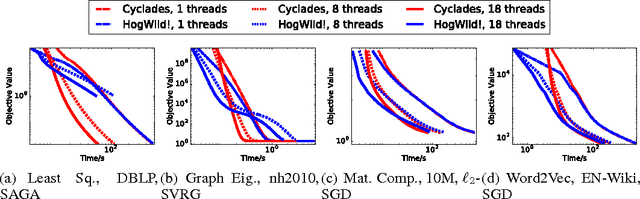
We present CYCLADES, a general framework for parallelizing stochastic optimization algorithms in a shared memory setting. CYCLADES is asynchronous during shared model updates, and requires no memory locking mechanisms, similar to HOGWILD!-type algorithms. Unlike HOGWILD!, CYCLADES introduces no conflicts during the parallel execution, and offers a black-box analysis for provable speedups across a large family of algorithms. Due to its inherent conflict-free nature and cache locality, our multi-core implementation of CYCLADES consistently outperforms HOGWILD!-type algorithms on sufficiently sparse datasets, leading to up to 40% speedup gains compared to the HOGWILD! implementation of SGD, and up to 5x gains over asynchronous implementations of variance reduction algorithms.
A Linearly-Convergent Stochastic L-BFGS Algorithm
Apr 13, 2016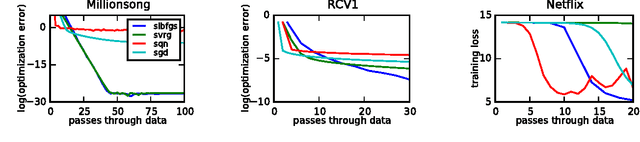
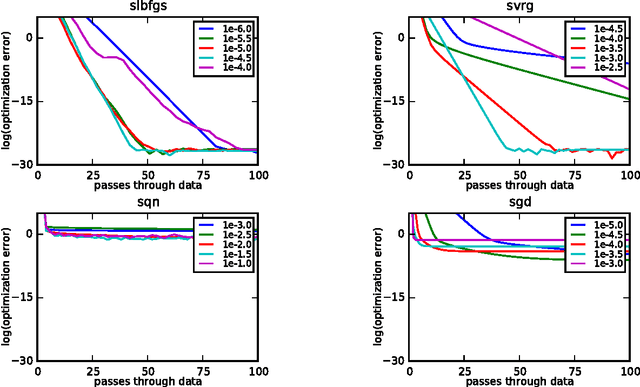
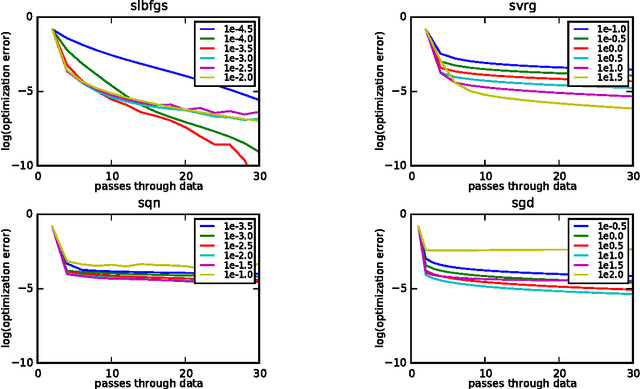
We propose a new stochastic L-BFGS algorithm and prove a linear convergence rate for strongly convex and smooth functions. Our algorithm draws heavily from a recent stochastic variant of L-BFGS proposed in Byrd et al. (2014) as well as a recent approach to variance reduction for stochastic gradient descent from Johnson and Zhang (2013). We demonstrate experimentally that our algorithm performs well on large-scale convex and non-convex optimization problems, exhibiting linear convergence and rapidly solving the optimization problems to high levels of precision. Furthermore, we show that our algorithm performs well for a wide-range of step sizes, often differing by several orders of magnitude.
Perturbed Iterate Analysis for Asynchronous Stochastic Optimization
Mar 25, 2016

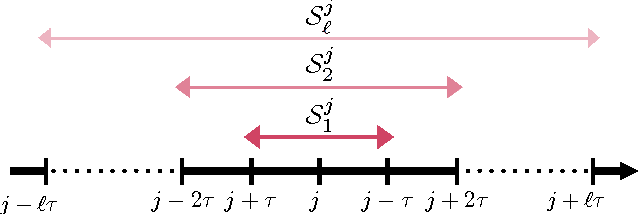
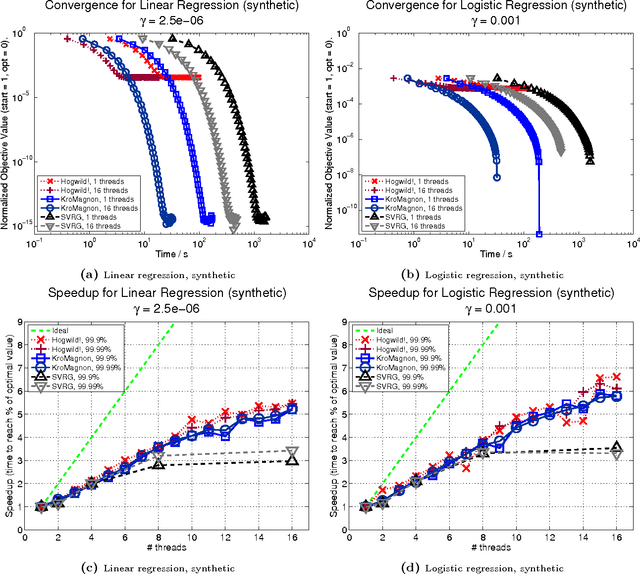
We introduce and analyze stochastic optimization methods where the input to each gradient update is perturbed by bounded noise. We show that this framework forms the basis of a unified approach to analyze asynchronous implementations of stochastic optimization algorithms.In this framework, asynchronous stochastic optimization algorithms can be thought of as serial methods operating on noisy inputs. Using our perturbed iterate framework, we provide new analyses of the Hogwild! algorithm and asynchronous stochastic coordinate descent, that are simpler than earlier analyses, remove many assumptions of previous models, and in some cases yield improved upper bounds on the convergence rates. We proceed to apply our framework to develop and analyze KroMagnon: a novel, parallel, sparse stochastic variance-reduced gradient (SVRG) algorithm. We demonstrate experimentally on a 16-core machine that the sparse and parallel version of SVRG is in some cases more than four orders of magnitude faster than the standard SVRG algorithm.
A Variational Perspective on Accelerated Methods in Optimization
Mar 14, 2016Accelerated gradient methods play a central role in optimization, achieving optimal rates in many settings. While many generalizations and extensions of Nesterov's original acceleration method have been proposed, it is not yet clear what is the natural scope of the acceleration concept. In this paper, we study accelerated methods from a continuous-time perspective. We show that there is a Lagrangian functional that we call the \emph{Bregman Lagrangian} which generates a large class of accelerated methods in continuous time, including (but not limited to) accelerated gradient descent, its non-Euclidean extension, and accelerated higher-order gradient methods. We show that the continuous-time limit of all of these methods correspond to traveling the same curve in spacetime at different speeds. From this perspective, Nesterov's technique and many of its generalizations can be viewed as a systematic way to go from the continuous-time curves generated by the Bregman Lagrangian to a family of discrete-time accelerated algorithms.
Gradient Descent Converges to Minimizers
Mar 04, 2016We show that gradient descent converges to a local minimizer, almost surely with random initialization. This is proved by applying the Stable Manifold Theorem from dynamical systems theory.