 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Stability of Nonlinear Receding Horizon Control: A Geometric Perspective
Mar 27, 2021
The widespread adoption of nonlinear Receding Horizon Control (RHC) strategies by industry has led to more than 30 years of intense research efforts to provide stability guarantees for these methods. However, current theoretical guarantees require that each (generally nonconvex) planning problem can be solved to (approximate) global optimality, which is an unrealistic requirement for the derivative-based local optimization methods generally used in practical implementations of RHC. This paper takes the first step towards understanding stability guarantees for nonlinear RHC when the inner planning problem is solved to first-order stationary points, but not necessarily global optima. Special attention is given to feedback linearizable systems, and a mixture of positive and negative results are provided. We establish that, under certain strong conditions, first-order solutions to RHC exponentially stabilize linearizable systems. Crucially, this guarantee requires that state costs applied to the planning problems are in a certain sense `compatible' with the global geometry of the system, and a simple counter-example demonstrates the necessity of this condition. These results highlight the need to rethink the role of global geometry in the context of optimization-based control.
A Variational Inequality Approach to Bayesian Regression Games
Mar 24, 2021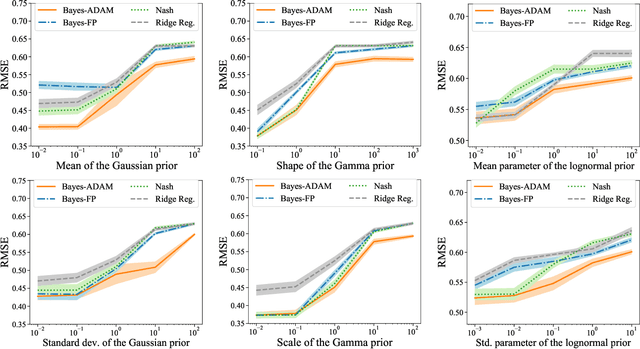
Bayesian regression games are a special class of two-player general-sum Bayesian games in which the learner is partially informed about the adversary's objective through a Bayesian prior. This formulation captures the uncertainty in regard to the adversary, and is useful in problems where the learner and adversary may have conflicting, but not necessarily perfectly antagonistic objectives. Although the Bayesian approach is a more general alternative to the standard minimax formulation, the applications of Bayesian regression games have been limited due to computational difficulties, and the existence and uniqueness of a Bayesian equilibrium are only known for quadratic cost functions. First, we prove the existence and uniqueness of a Bayesian equilibrium for a class of convex and smooth Bayesian games by regarding it as a solution of an infinite-dimensional variational inequality (VI) in Hilbert space. We consider two special cases in which the infinite-dimensional VI reduces to a high-dimensional VI or a nonconvex stochastic optimization, and provide two simple algorithms of solving them with strong convergence guarantees. Numerical results on real datasets demonstrate the promise of this approach.
Representation Matters: Assessing the Importance of Subgroup Allocations in Training Data
Mar 05, 2021
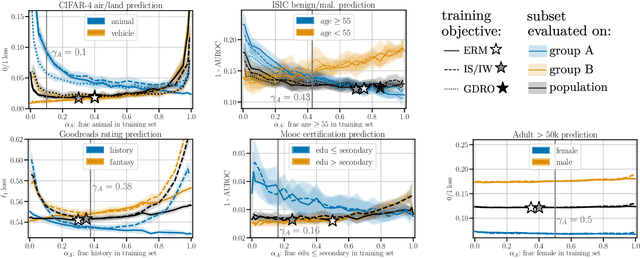
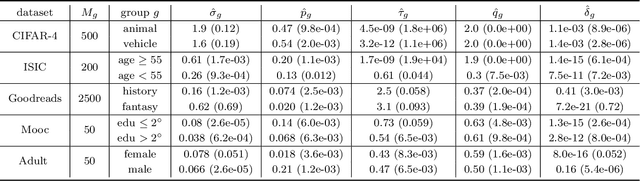
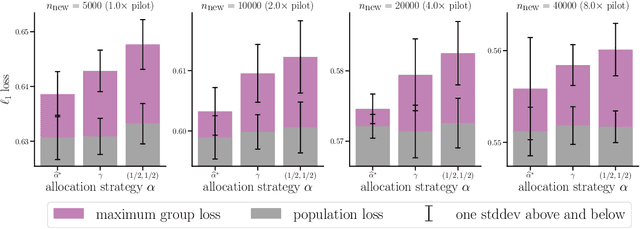
Collecting more diverse and representative training data is often touted as a remedy for the disparate performance of machine learning predictors across subpopulations. However, a precise framework for understanding how dataset properties like diversity affect learning outcomes is largely lacking. By casting data collection as part of the learning process, we demonstrate that diverse representation in training data is key not only to increasing subgroup performances, but also to achieving population level objectives. Our analysis and experiments describe how dataset compositions influence performance and provide constructive results for using trends in existing data, alongside domain knowledge, to help guide intentional, objective-aware dataset design.
Multi-Stage Decentralized Matching Markets: Uncertain Preferences and Strategic Behaviors
Feb 13, 2021


Matching markets are often organized in a multi-stage and decentralized manner. Moreover, participants in real-world matching markets often have uncertain preferences. This article develops a framework for learning optimal strategies in such settings, based on a nonparametric statistical approach and variational analysis. We propose an efficient algorithm, built upon concepts of "lower uncertainty bound" and "calibrated decentralized matching," for maximizing the participants' expected payoff. We show that there exists a welfare-versus-fairness trade-off that is characterized by the uncertainty level of acceptance. Participants will strategically act in favor of a low uncertainty level to reduce competition and increase expected payoff. We study signaling mechanisms that help to clear the congestion in such decentralized markets and find that the effects of signaling are heterogeneous, showing a dependence on the participants and matching stages. We prove that participants can be better off with multi-stage matching compared to single-stage matching. The deferred acceptance procedure assumes no limit on the number of stages and attains efficiency and fairness but may make some participants worse off than multi-stage matching. We demonstrate aspects of the theoretical predictions through simulations and an experiment using real data from college admissions.
Private Prediction Sets
Feb 11, 2021
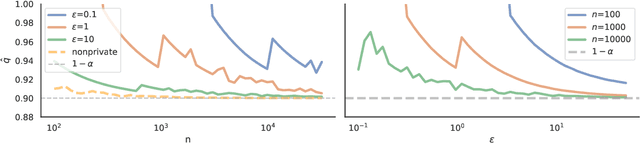
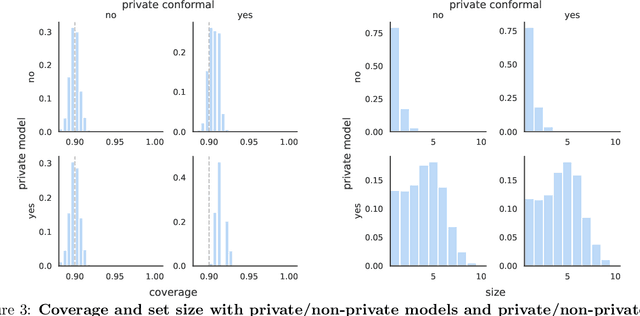
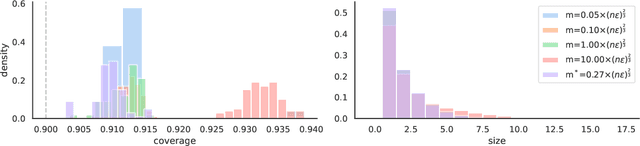
In real-world settings involving consequential decision-making, the deployment of machine learning systems generally requires both reliable uncertainty quantification and protection of individuals' privacy. We present a framework that treats these two desiderata jointly. Our framework is based on conformal prediction, a methodology that augments predictive models to return prediction sets that provide uncertainty quantification -- they provably cover the true response with a user-specified probability, such as 90%. One might hope that when used with privately-trained models, conformal prediction would yield privacy guarantees for the resulting prediction sets; unfortunately this is not the case. To remedy this key problem, we develop a method that takes any pre-trained predictive model and outputs differentially private prediction sets. Our method follows the general approach of split conformal prediction; we use holdout data to calibrate the size of the prediction sets but preserve privacy by using a privatized quantile subroutine. This subroutine compensates for the noise introduced to preserve privacy in order to guarantee correct coverage. We evaluate the method with experiments on the CIFAR-10, ImageNet, and CoronaHack datasets.
Distribution-Free, Risk-Controlling Prediction Sets
Jan 30, 2021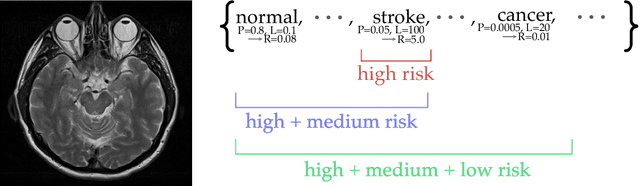
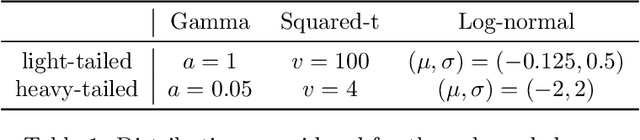
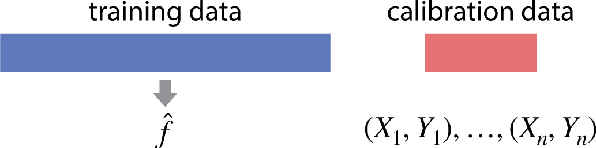
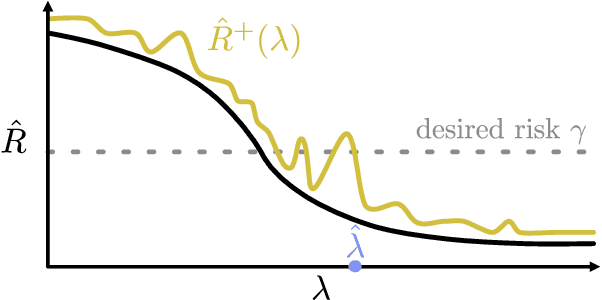
While improving prediction accuracy has been the focus of machine learning in recent years, this alone does not suffice for reliable decision-making. Deploying learning systems in consequential settings also requires calibrating and communicating the uncertainty of predictions. To convey instance-wise uncertainty for prediction tasks, we show how to generate set-valued predictions from a black-box predictor that control the expected loss on future test points at a user-specified level. Our approach provides explicit finite-sample guarantees for any dataset by using a holdout set to calibrate the size of the prediction sets. This framework enables simple, distribution-free, rigorous error control for many tasks, and we demonstrate it in five large-scale machine learning problems: (1) classification problems where some mistakes are more costly than others; (2) multi-label classification, where each observation has multiple associated labels; (3) classification problems where the labels have a hierarchical structure; (4) image segmentation, where we wish to predict a set of pixels containing an object of interest; and (5) protein structure prediction. Lastly, we discuss extensions to uncertainty quantification for ranking, metric learning and distributionally robust learning.
Bandit Learning in Decentralized Matching Markets
Dec 31, 2020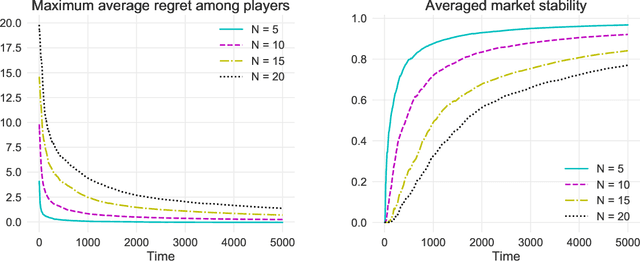
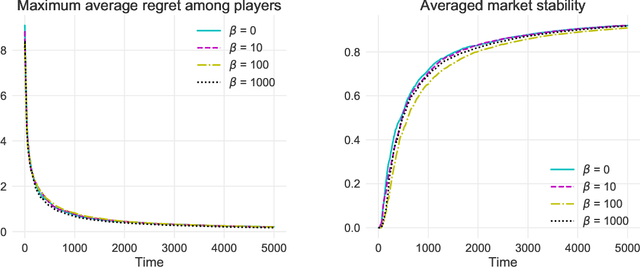
We study two-sided matching markets in which one side of the market (the players) does not have a priori knowledge about its preferences for the other side (the arms) and is required to learn its preferences from experience. Also, we assume the players have no direct means of communication. This model extends the standard stochastic multi-armed bandit framework to a decentralized multiple player setting with competition. We introduce a new algorithm for this setting that, over a time horizon $T$, attains $\mathcal{O}(\log(T))$ stable regret when preferences of the arms over players are shared, and $\mathcal{O}(\log(T)^2)$ regret when there are no assumptions on the preferences on either side.
Stochastic Approximation for Online Tensorial Independent Component Analysis
Dec 28, 2020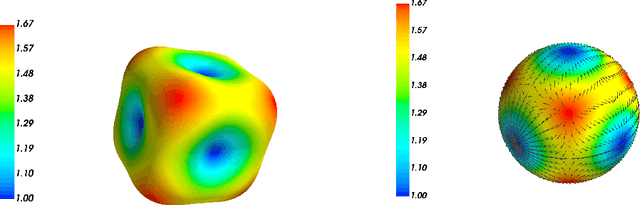
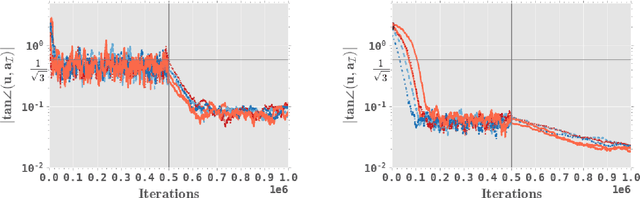
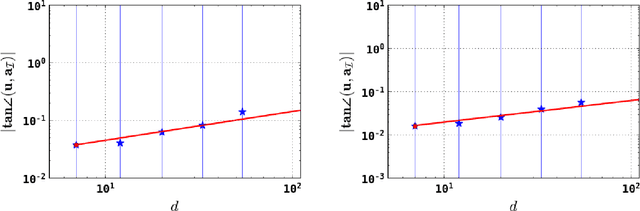
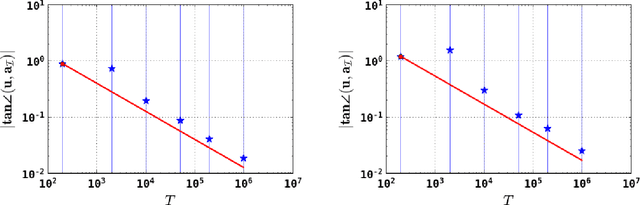
Independent component analysis (ICA) has been a popular dimension reduction tool in statistical machine learning and signal processing. In this paper, we present a convergence analysis for an online tensorial ICA algorithm, by viewing the problem as a nonconvex stochastic approximation problem. For estimating one component, we provide a dynamics-based analysis to prove that our online tensorial ICA algorithm with a specific choice of stepsize achieves a sharp finite-sample error bound. In particular, under a mild assumption on the data-generating distribution and a scaling condition such that $d^4 / T$ is sufficiently small up to a polylogarithmic factor of data dimension $d$ and sample size $T$, a sharp finite-sample error bound of $\tilde O(\sqrt{d / T})$ can be obtained. As a by-product, we also design an online tensorial ICA algorithm that estimates multiple independent components in parallel, achieving desirable finite-sample error bound for each independent component estimator.
Optimal Mean Estimation without a Variance
Dec 08, 2020We study the problem of heavy-tailed mean estimation in settings where the variance of the data-generating distribution does not exist. Concretely, given a sample $\mathbf{X} = \{X_i\}_{i = 1}^n$ from a distribution $\mathcal{D}$ over $\mathbb{R}^d$ with mean $\mu$ which satisfies the following \emph{weak-moment} assumption for some ${\alpha \in [0, 1]}$: \begin{equation*} \forall \|v\| = 1: \mathbb{E}_{X \thicksim \mathcal{D}}[\lvert \langle X - \mu, v\rangle \rvert^{1 + \alpha}] \leq 1, \end{equation*} and given a target failure probability, $\delta$, our goal is to design an estimator which attains the smallest possible confidence interval as a function of $n,d,\delta$. For the specific case of $\alpha = 1$, foundational work of Lugosi and Mendelson exhibits an estimator achieving subgaussian confidence intervals, and subsequent work has led to computationally efficient versions of this estimator. Here, we study the case of general $\alpha$, and establish the following information-theoretic lower bound on the optimal attainable confidence interval: \begin{equation*} \Omega \left(\sqrt{\frac{d}{n}} + \left(\frac{d}{n}\right)^{\frac{\alpha}{(1 + \alpha)}} + \left(\frac{\log 1 / \delta}{n}\right)^{\frac{\alpha}{(1 + \alpha)}}\right). \end{equation*} Moreover, we devise a computationally-efficient estimator which achieves this lower bound.
Bridging Exploration and General Function Approximation in Reinforcement Learning: Provably Efficient Kernel and Neural Value Iterations
Nov 09, 2020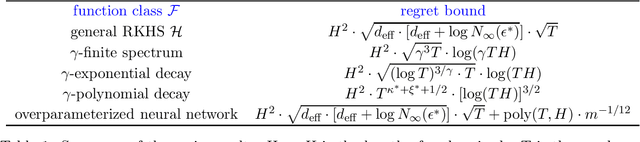
Reinforcement learning (RL) algorithms combined with modern function approximators such as kernel functions and deep neural networks have achieved significant empirical successes in large-scale application problems with a massive number of states. From a theoretical perspective, however, RL with functional approximation poses a fundamental challenge to developing algorithms with provable computational and statistical efficiency, due to the need to take into consideration both the exploration-exploitation tradeoff that is inherent in RL and the bias-variance tradeoff that is innate in statistical estimation. To address such a challenge, focusing on the episodic setting where the action-value functions are represented by a kernel function or over-parametrized neural network, we propose the first provable RL algorithm with both polynomial runtime and sample complexity, without additional assumptions on the data-generating model. In particular, for both the kernel and neural settings, we prove that an optimistic modification of the least-squares value iteration algorithm incurs an $\tilde{\mathcal{O}}(\delta_{\mathcal{F}} H^2 \sqrt{T})$ regret, where $\delta_{\mathcal{F}}$ characterizes the intrinsic complexity of the function class $\mathcal{F}$, $H$ is the length of each episode, and $T$ is the total number of episodes. Our regret bounds are independent of the number of states and therefore even allows it to diverge, which exhibits the benefit of function approximation.