 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Extractive-Abstractive Spectrum: Uncovering Verifiability Trade-offs in LLM Generations
Nov 26, 2024



Across all fields of academic study, experts cite their sources when sharing information. While large language models (LLMs) excel at synthesizing information, they do not provide reliable citation to sources, making it difficult to trace and verify the origins of the information they present. In contrast, search engines make sources readily accessible to users and place the burden of synthesizing information on the user. Through a survey, we find that users prefer search engines over LLMs for high-stakes queries, where concerns regarding information provenance outweigh the perceived utility of LLM responses. To examine the interplay between verifiability and utility of information-sharing tools, we introduce the extractive-abstractive spectrum, in which search engines and LLMs are extreme endpoints encapsulating multiple unexplored intermediate operating points. Search engines are extractive because they respond to queries with snippets of sources with links (citations) to the original webpages. LLMs are abstractive because they address queries with answers that synthesize and logically transform relevant information from training and in-context sources without reliable citation. We define five operating points that span the extractive-abstractive spectrum and conduct human evaluations on seven systems across four diverse query distributions that reflect real-world QA settings: web search, language simplification, multi-step reasoning, and medical advice. As outputs become more abstractive, we find that perceived utility improves by as much as 200%, while the proportion of properly cited sentences decreases by as much as 50% and users take up to 3 times as long to verify cited information. Our findings recommend distinct operating points for domain-specific LLM systems and our failure analysis informs approaches to high-utility LLM systems that empower users to verify information.
Unifying Corroborative and Contributive Attributions in Large Language Models
Nov 20, 2023As businesses, products, and services spring up around large language models, the trustworthiness of these models hinges on the verifiability of their outputs. However, methods for explaining language model outputs largely fall across two distinct fields of study which both use the term "attribution" to refer to entirely separate techniques: citation generation and training data attribution. In many modern applications, such as legal document generation and medical question answering, both types of attributions are important. In this work, we argue for and present a unified framework of large language model attributions. We show how existing methods of different types of attribution fall under the unified framework. We also use the framework to discuss real-world use cases where one or both types of attributions are required. We believe that this unified framework will guide the use case driven development of systems that leverage both types of attribution, as well as the standardization of their evaluation.
Representation Matters: Assessing the Importance of Subgroup Allocations in Training Data
Mar 05, 2021
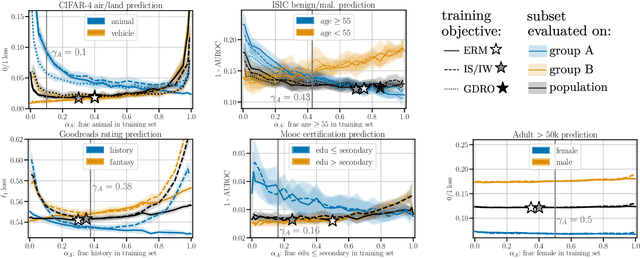
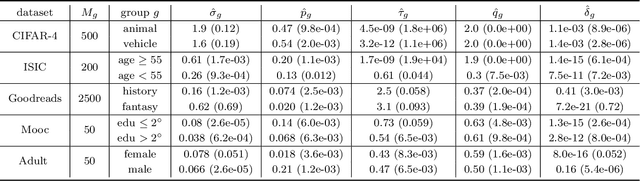
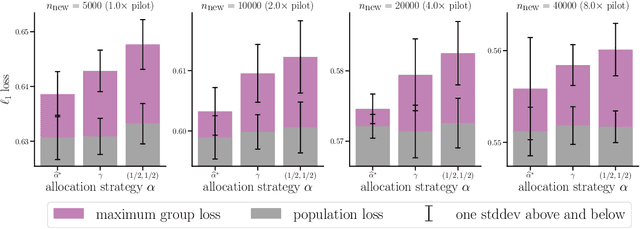
Collecting more diverse and representative training data is often touted as a remedy for the disparate performance of machine learning predictors across subpopulations. However, a precise framework for understanding how dataset properties like diversity affect learning outcomes is largely lacking. By casting data collection as part of the learning process, we demonstrate that diverse representation in training data is key not only to increasing subgroup performances, but also to achieving population level objectives. Our analysis and experiments describe how dataset compositions influence performance and provide constructive results for using trends in existing data, alongside domain knowledge, to help guide intentional, objective-aware dataset design.