 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferred Q-learning
Feb 09, 2022We consider $Q$-learning with knowledge transfer, using samples from a target reinforcement learning (RL) task as well as source samples from different but related RL tasks. We propose transfer learning algorithms for both batch and online $Q$-learning with offline source studies. The proposed transferred $Q$-learning algorithm contains a novel re-targeting step that enables vertical information-cascading along multiple steps in an RL task, besides the usual horizontal information-gathering as transfer learning (TL) for supervised learning. We establish the first theoretical justifications of TL in RL tasks by showing a faster rate of convergence of the $Q$ function estimation in the offline RL transfer, and a lower regret bound in the offline-to-online RL transfer under certain similarity assumptions. Empirical evidences from both synthetic and real datasets are presented to back up the proposed algorithm and our theoretical results.
Robust Estimation for Nonparametric Families via Generative Adversarial Networks
Feb 02, 2022We provide a general framework for designing Generative Adversarial Networks (GANs) to solve high dimensional robust statistics problems, which aim at estimating unknown parameter of the true distribution given adversarially corrupted samples. Prior work focus on the problem of robust mean and covariance estimation when the true distribution lies in the family of Gaussian distributions or elliptical distributions, and analyze depth or scoring rule based GAN losses for the problem. Our work extend these to robust mean estimation, second moment estimation, and robust linear regression when the true distribution only has bounded Orlicz norms, which includes the broad family of sub-Gaussian, sub-Exponential and bounded moment distributions. We also provide a different set of sufficient conditions for the GAN loss to work: we only require its induced distance function to be a cumulative density function of some light-tailed distribution, which is easily satisfied by neural networks with sigmoid activation. In terms of techniques, our proposed GAN losses can be viewed as a smoothed and generalized Kolmogorov-Smirnov distance, which overcomes the computational intractability of the original Kolmogorov-Smirnov distance used in the prior work.
Reinforcement Learning with Heterogeneous Data: Estimation and Inference
Jan 31, 2022



Reinforcement Learning (RL) has the promise of providing data-driven support for decision-making in a wide range of problems in healthcare, education, business, and other domains. Classical RL methods focus on the mean of the total return and, thus, may provide misleading results in the setting of the heterogeneous populations that commonly underlie large-scale datasets. We introduce the K-Heterogeneous Markov Decision Process (K-Hetero MDP) to address sequential decision problems with population heterogeneity. We propose the Auto-Clustered Policy Evaluation (ACPE) for estimating the value of a given policy, and the Auto-Clustered Policy Iteration (ACPI) for estimating the optimal policy in a given policy class. Our auto-clustered algorithms can automatically detect and identify homogeneous sub-populations, while estimating the Q function and the optimal policy for each sub-population. We establish convergence rates and construct confidence intervals for the estimators obtained by the ACPE and ACPI. We present simulations to support our theoretical findings, and we conduct an empirical study on the standard MIMIC-III dataset. The latter analysis shows evidence of value heterogeneity and confirms the advantages of our new method.
Online Active Learning with Dynamic Marginal Gain Thresholding
Jan 25, 2022
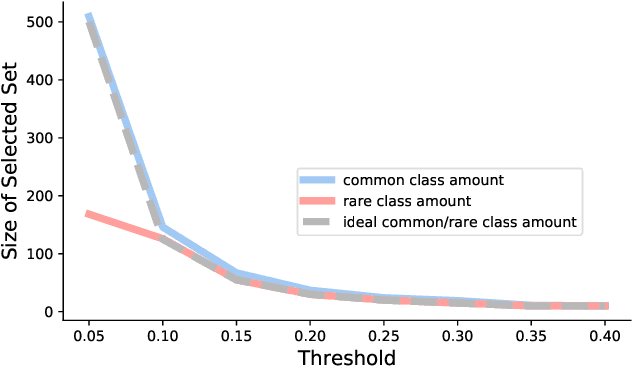
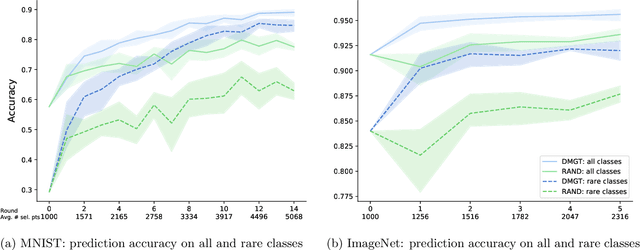
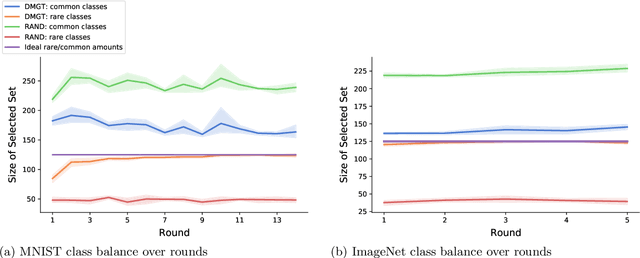
The blessing of ubiquitous data also comes with a curse: the communication, storage, and labeling of massive, mostly redundant datasets. In our work, we seek to solve the problem at its source, collecting only valuable data and throwing out the rest, via active learning. We propose an online algorithm which, given any stream of data, any assessment of its value, and any formulation of its selection cost, extracts the most valuable subset of the stream up to a constant factor while using minimal memory. Notably, our analysis also holds for the federated setting, in which multiple agents select online from individual data streams without coordination and with potentially very different appraisals of cost. One particularly important use case is selecting and labeling training sets from unlabeled collections of data that maximize the test-time performance of a given classifier. In prediction tasks on ImageNet and MNIST, we show that our selection method outperforms random selection by up to 5-20%.
Nonconvex Stochastic Scaled-Gradient Descent and Generalized Eigenvector Problems
Jan 24, 2022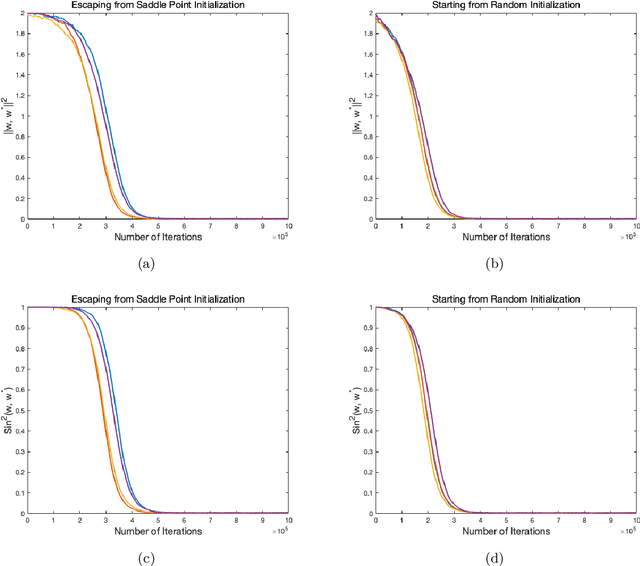
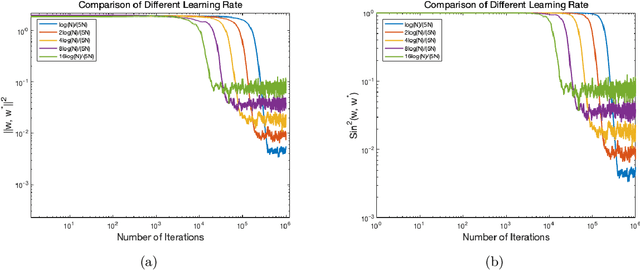
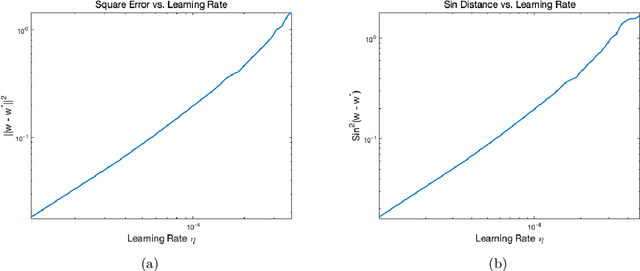
Motivated by the problem of online canonical correlation analysis, we propose the \emph{Stochastic Scaled-Gradient Descent} (SSGD) algorithm for minimizing the expectation of a stochastic function over a generic Riemannian manifold. SSGD generalizes the idea of projected stochastic gradient descent and allows the use of scaled stochastic gradients instead of stochastic gradients. In the special case of a spherical constraint, which arises in generalized eigenvector problems, we establish a nonasymptotic finite-sample bound of $\sqrt{1/T}$, and show that this rate is minimax optimal, up to a polylogarithmic factor of relevant parameters. On the asymptotic side, a novel trajectory-averaging argument allows us to achieve local asymptotic normality with a rate that matches that of Ruppert-Polyak-Juditsky averaging. We bring these ideas together in an application to online canonical correlation analysis, deriving, for the first time in the literature, an optimal one-time-scale algorithm with an explicit rate of local asymptotic convergence to normality. Numerical studies of canonical correlation analysis are also provided for synthetic data.
Polyak-Ruppert Averaged Q-Leaning is Statistically Efficient
Jan 23, 2022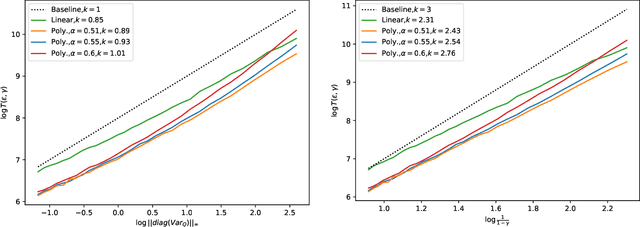
We study synchronous Q-learning with Polyak-Ruppert averaging (a.k.a., averaged Q-learning) in a $\gamma$-discounted MDP. We establish a functional central limit theorem (FCLT) for the averaged iteration $\bar{\boldsymbol{Q}}_T$ and show its standardized partial-sum process weakly converges to a rescaled Brownian motion. Furthermore, we show that $\bar{\boldsymbol{Q}}_T$ is actually a regular asymptotically linear (RAL) estimator for the optimal Q-value function $\boldsymbol{Q}^*$ with the most efficient influence function. This implies the averaged Q-learning iteration has the smallest asymptotic variance among all RAL estimators. In addition, we present a non-asymptotic analysis for the $\ell_{\infty}$ error $\mathbb{E}\|\bar{\boldsymbol{Q}}_T-\boldsymbol{Q}^*\|_{\infty}$, showing for polynomial step sizes it matches the instance-dependent lower bound as well as the optimal minimax complexity lower bound. In short, our theoretical analysis shows averaged Q-learning is statistically efficient.
Instance-Dependent Confidence and Early Stopping for Reinforcement Learning
Jan 21, 2022



Various algorithms for reinforcement learning (RL) exhibit dramatic variation in their convergence rates as a function of problem structure. Such problem-dependent behavior is not captured by worst-case analyses and has accordingly inspired a growing effort in obtaining instance-dependent guarantees and deriving instance-optimal algorithms for RL problems. This research has been carried out, however, primarily within the confines of theory, providing guarantees that explain \textit{ex post} the performance differences observed. A natural next step is to convert these theoretical guarantees into guidelines that are useful in practice. We address the problem of obtaining sharp instance-dependent confidence regions for the policy evaluation problem and the optimal value estimation problem of an MDP, given access to an instance-optimal algorithm. As a consequence, we propose a data-dependent stopping rule for instance-optimal algorithms. The proposed stopping rule adapts to the instance-specific difficulty of the problem and allows for early termination for problems with favorable structure.
Optimal variance-reduced stochastic approximation in Banach spaces
Jan 21, 2022We study the problem of estimating the fixed point of a contractive operator defined on a separable Banach space. Focusing on a stochastic query model that provides noisy evaluations of the operator, we analyze a variance-reduced stochastic approximation scheme, and establish non-asymptotic bounds for both the operator defect and the estimation error, measured in an arbitrary semi-norm. In contrast to worst-case guarantees, our bounds are instance-dependent, and achieve the local asymptotic minimax risk non-asymptotically. For linear operators, contractivity can be relaxed to multi-step contractivity, so that the theory can be applied to problems like average reward policy evaluation problem in reinforcement learning. We illustrate the theory via applications to stochastic shortest path problems, two-player zero-sum Markov games, as well as policy evaluation and $Q$-learning for tabular Markov decision processes.
Last-Iterate Convergence of Saddle Point Optimizers via High-Resolution Differential Equations
Dec 27, 2021
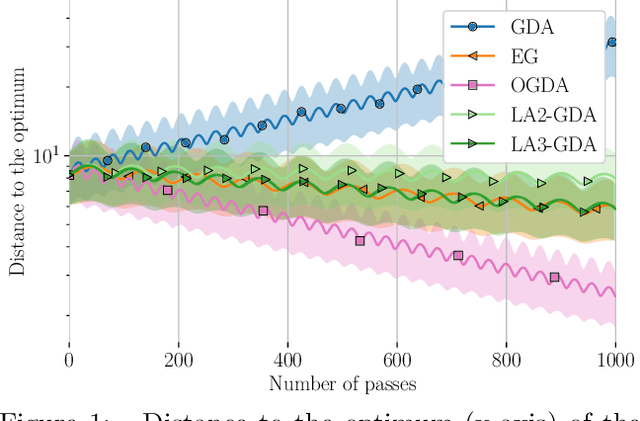

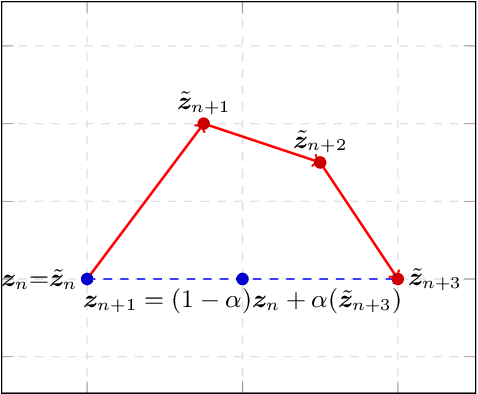
Several widely-used first-order saddle point optimization methods yield an identical continuous-time ordinary differential equation (ODE) to that of the Gradient Descent Ascent (GDA) method when derived naively. However, their convergence properties are very different even on simple bilinear games. We use a technique from fluid dynamics called High-Resolution Differential Equations (HRDEs) to design ODEs of several saddle point optimization methods. On bilinear games, the convergence properties of the derived HRDEs correspond to that of the starting discrete methods. Using these techniques, we show that the HRDE of Optimistic Gradient Descent Ascent (OGDA) has last-iterate convergence for general monotone variational inequalities. To our knowledge, this is the first continuous-time dynamics shown to converge for such a general setting. Moreover, we provide the rates for the best-iterate convergence of the OGDA method, relying solely on the first-order smoothness of the monotone operator.
Wasserstein Flow Meets Replicator Dynamics: A Mean-Field Analysis of Representation Learning in Actor-Critic
Dec 27, 2021Actor-critic (AC) algorithms, empowered by neural networks, have had significant empirical success in recent years. However, most of the existing theoretical support for AC algorithms focuses on the case of linear function approximations, or linearized neural networks, where the feature representation is fixed throughout training. Such a limitation fails to capture the key aspect of representation learning in neural AC, which is pivotal in practical problems. In this work, we take a mean-field perspective on the evolution and convergence of feature-based neural AC. Specifically, we consider a version of AC where the actor and critic are represented by overparameterized two-layer neural networks and are updated with two-timescale learning rates. The critic is updated by temporal-difference (TD) learning with a larger stepsize while the actor is updated via proximal policy optimization (PPO) with a smaller stepsize. In the continuous-time and infinite-width limiting regime, when the timescales are properly separated, we prove that neural AC finds the globally optimal policy at a sublinear rate. Additionally, we prove that the feature representation induced by the critic network is allowed to evolve within a neighborhood of the initial one.