 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning in Robotics: An Upcoming Breakthrough? A Review of Promises and Challenges
Nov 29, 2023Transfer learning is a conceptually-enticing paradigm in pursuit of truly intelligent embodied agents. The core concept -- reusing prior knowledge to learn in and from novel situations -- is successfully leveraged by humans to handle novel situations. In recent years, transfer learning has received renewed interest from the community from different perspectives, including imitation learning, domain adaptation, and transfer of experience from simulation to the real world, among others. In this paper, we unify the concept of transfer learning in robotics and provide the first taxonomy of its kind considering the key concepts of robot, task, and environment. Through a review of the promises and challenges in the field, we identify the need of transferring at different abstraction levels, the need of quantifying the transfer gap and the quality of transfer, as well as the dangers of negative transfer. Via this position paper, we hope to channel the effort of the community towards the most significant roadblocks to realize the full potential of transfer learning in robotics.
Enabling Robot Manipulation of Soft and Rigid Objects with Vision-based Tactile Sensors
Jun 09, 2023



Endowing robots with tactile capabilities opens up new possibilities for their interaction with the environment, including the ability to handle fragile and/or soft objects. In this work, we equip the robot gripper with low-cost vision-based tactile sensors and propose a manipulation algorithm that adapts to both rigid and soft objects without requiring any knowledge of their properties. The algorithm relies on a touch and slip detection method, which considers the variation in the tactile images with respect to reference ones. We validate the approach on seven different objects, with different properties in terms of rigidity and fragility, to perform unplugging and lifting tasks. Furthermore, to enhance applicability, we combine the manipulation algorithm with a grasp sampler for the task of finding and picking a grape from a bunch without damaging~it.
A Virtual Reality Framework for Human-Robot Collaboration in Cloth Folding
May 12, 2023We present a virtual reality (VR) framework to automate the data collection process in cloth folding tasks. The framework uses skeleton representations to help the user define the folding plans for different classes of garments, allowing for replicating the folding on unseen items of the same class. We evaluate the framework in the context of automating garment folding tasks. A quantitative analysis is performed on 3 classes of garments, demonstrating that the framework reduces the need for intervention by the user. We also compare skeleton representations with RGB and binary images in a classification task on a large dataset of clothing items, motivating the use of the framework for other classes of garments.
Ensemble Latent Space Roadmap for Improved Robustness in Visual Action Planning
Mar 27, 2023



Planning in learned latent spaces helps to decrease the dimensionality of raw observations. In this work, we propose to leverage the ensemble paradigm to enhance the robustness of latent planning systems. We rely on our Latent Space Roadmap (LSR) framework, which builds a graph in a learned structured latent space to perform planning. Given multiple LSR framework instances, that differ either on their latent spaces or on the parameters for constructing the graph, we use the action information as well as the embedded nodes of the produced plans to define similarity measures. These are then utilized to select the most promising plans. We validate the performance of our Ensemble LSR (ENS-LSR) on simulated box stacking and grape harvesting tasks as well as on a real-world robotic T-shirt folding experiment.
EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics
Sep 19, 2022
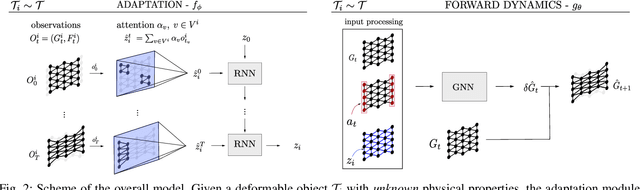
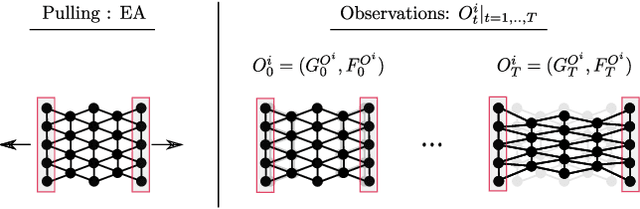
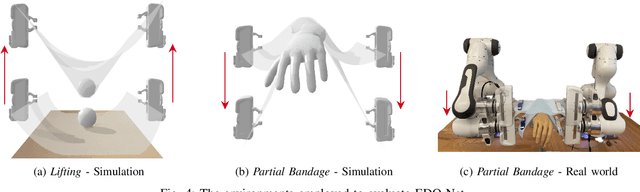
We study the problem of learning graph dynamics of deformable objects which generalize to unknown physical properties. In particular, we leverage a latent representation of elastic physical properties of cloth-like deformable objects which we explore through a pulling interaction. We propose EDO-Net (Elastic Deformable Object - Net), a model trained in a self-supervised fashion on a large variety of samples with different elastic properties. EDO-Net jointly learns an adaptation module, responsible for extracting a latent representation of the physical properties of the object, and a forward-dynamics module, which leverages the latent representation to predict future states of cloth-like objects, represented as graphs. We evaluate EDO-Net both in simulation and real world, assessing its capabilities of: 1) generalizing to unknown physical properties of cloth-like deformable objects, 2) transferring the learned representation to new downstream tasks.
Elastic Context: Encoding Elasticity for Data-driven Models of Textiles
Sep 19, 2022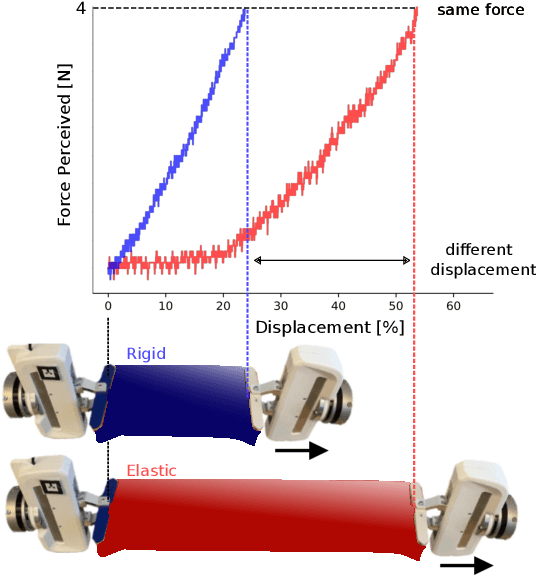
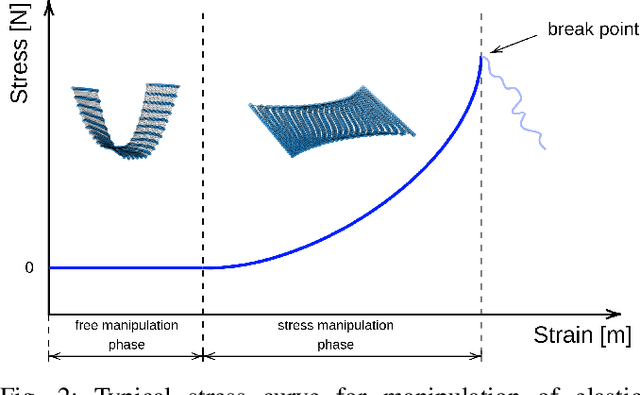
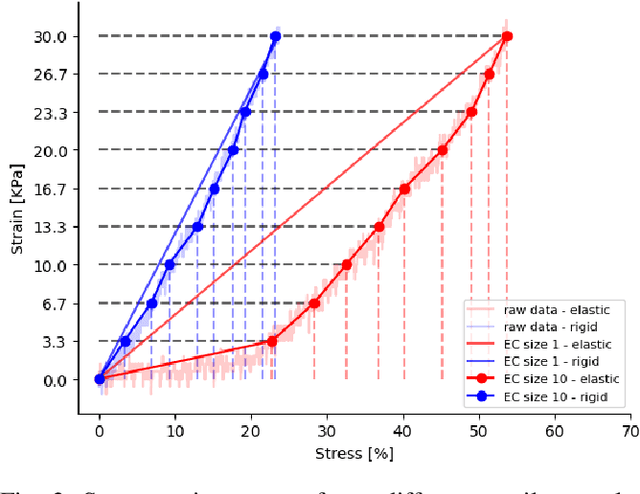
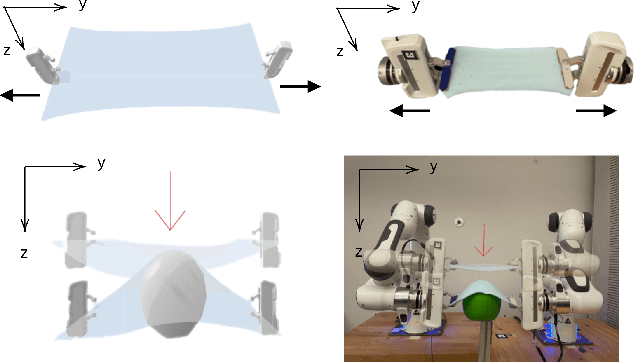
Physical interaction with textiles, such as assistive dressing, relies on advanced dextreous capabilities. The underlying complexity in textile behavior when being pulled and stretched, is due to both the yarn material properties and the textile construction technique. Today, there are no commonly adopted and annotated datasets on which the various interaction or property identification methods are assessed. One important property that affects the interaction is material elasticity that results from both the yarn material and construction technique: these two are intertwined and, if not known a-priori, almost impossible to identify through sensing commonly available on robotic platforms. We introduce Elastic Context (EC), a concept that integrates various properties that affect elastic behavior, to enable a more effective physical interaction with textiles. The definition of EC relies on stress/strain curves commonly used in textile engineering, which we reformulated for robotic applications. We employ EC using Graph Neural Network (GNN) to learn generalized elastic behaviors of textiles. Furthermore, we explore the effect the dimension of the EC has on accurate force modeling of non-linear real-world elastic behaviors, highlighting the challenges of current robotic setups to sense textile properties.
Augment-Connect-Explore: a Paradigm for Visual Action Planning with Data Scarcity
Mar 24, 2022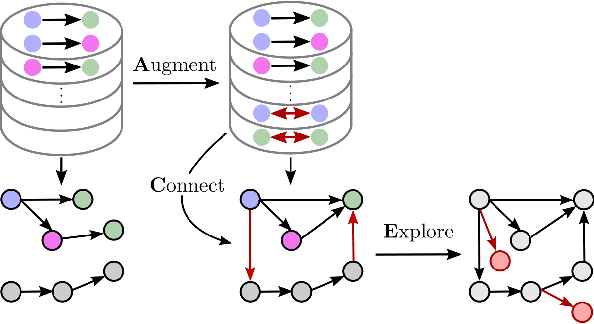
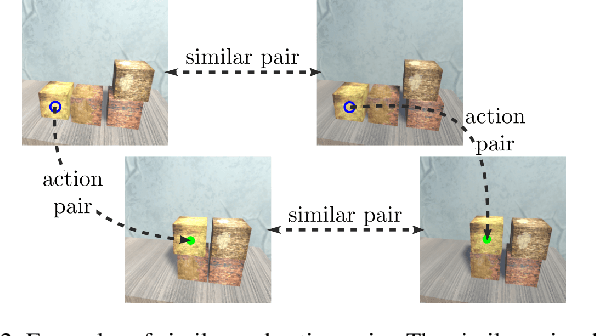
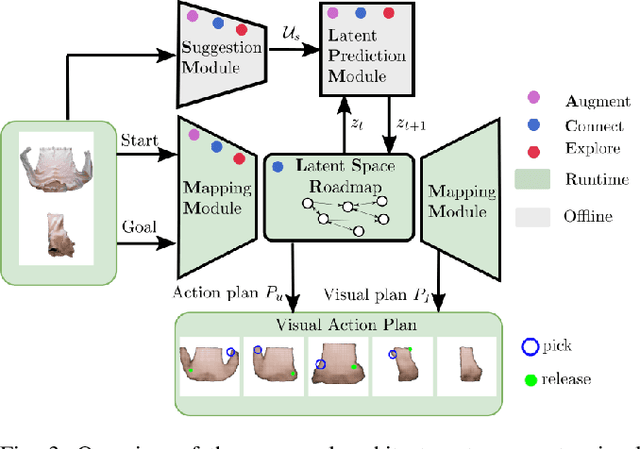
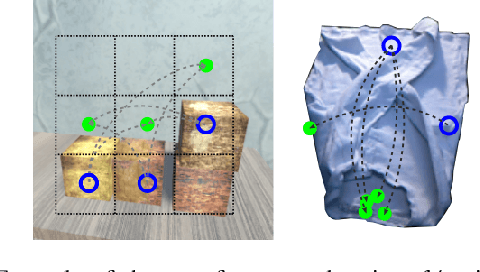
Visual action planning particularly excels in applications where the state of the system cannot be computed explicitly, such as manipulation of deformable objects, as it enables planning directly from raw images. Even though the field has been significantly accelerated by deep learning techniques, a crucial requirement for their success is the availability of a large amount of data. In this work, we propose the Augment-Connect-Explore (ACE) paradigm to enable visual action planning in cases of data scarcity. We build upon the Latent Space Roadmap (LSR) framework which performs planning with a graph built in a low dimensional latent space. In particular, ACE is used to i) Augment the available training dataset by autonomously creating new pairs of datapoints, ii) create new unobserved Connections among representations of states in the latent graph, and iii) Explore new regions of the latent space in a targeted manner. We validate the proposed approach on both simulated box stacking and real-world folding task showing the applicability for rigid and deformable object manipulation tasks, respectively.
Comparing Reconstruction- and Contrastive-based Models for Visual Task Planning
Sep 14, 2021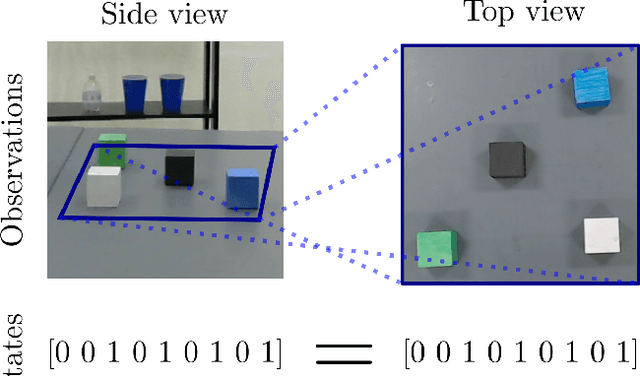

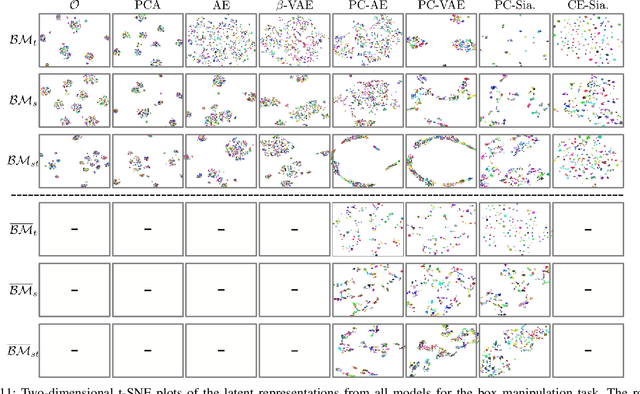
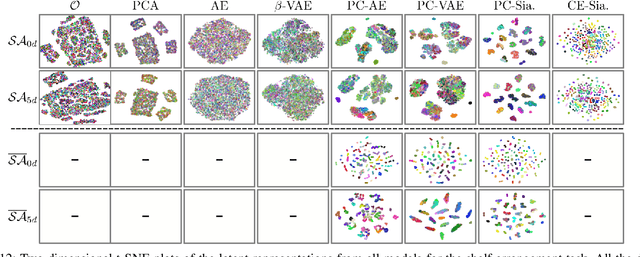
Learning state representations enables robotic planning directly from raw observations such as images. Most methods learn state representations by utilizing losses based on the reconstruction of the raw observations from a lower-dimensional latent space. The similarity between observations in the space of images is often assumed and used as a proxy for estimating similarity between the underlying states of the system. However, observations commonly contain task-irrelevant factors of variation which are nonetheless important for reconstruction, such as varying lighting and different camera viewpoints. In this work, we define relevant evaluation metrics and perform a thorough study of different loss functions for state representation learning. We show that models exploiting task priors, such as Siamese networks with a simple contrastive loss, outperform reconstruction-based representations in visual task planning.
Batch Curation for Unsupervised Contrastive Representation Learning
Aug 19, 2021
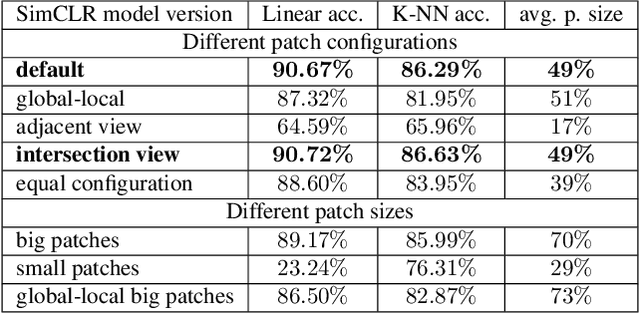
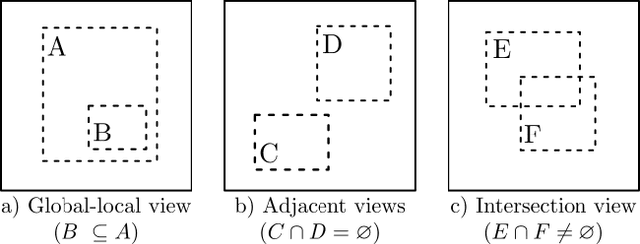

The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images. Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result similar pairs that are \textit{semantically} dissimilar. In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.
Textile Taxonomy and Classification Using Pulling and Twisting
Mar 17, 2021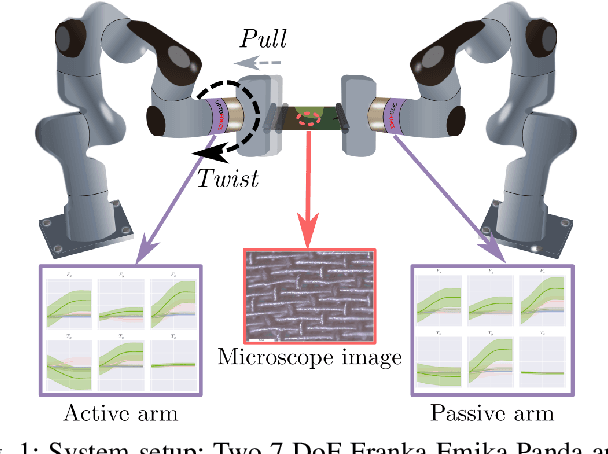

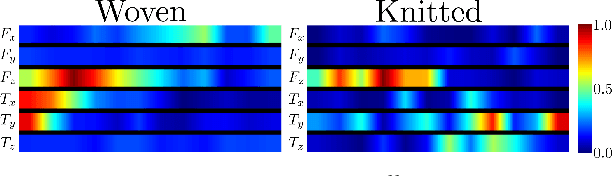
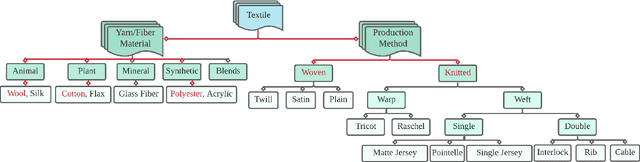
Identification of textile properties is an important milestone toward advanced robotic manipulation tasks that consider interaction with clothing items such as assisted dressing, laundry folding, automated sewing, textile recycling and reusing. Despite the abundance of work considering this class of deformable objects, many open problems remain. These relate to the choice and modelling of the sensory feedback as well as the control and planning of the interaction and manipulation strategies. Most importantly, there is no structured approach for studying and assessing different approaches that may bridge the gap between the robotics community and textile production industry. To this end, we outline a textile taxonomy considering fiber types and production methods, commonly used in textile industry. We devise datasets according to the taxonomy, and study how robotic actions, such as pulling and twisting of the textile samples, can be used for the classification. We also provide important insights from the perspective of visualization and interpretability of the gathered data.