 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation
Nov 27, 2022



Few-shot (FS) and zero-shot (ZS) learning are two different approaches for scaling temporal action detection (TAD) to new classes. The former adapts a pretrained vision model to a new task represented by as few as a single video per class, whilst the latter requires no training examples by exploiting a semantic description of the new class. In this work, we introduce a new multi-modality few-shot (MMFS) TAD problem, which can be considered as a marriage of FS-TAD and ZS-TAD by leveraging few-shot support videos and new class names jointly. To tackle this problem, we further introduce a novel MUlti-modality PromPt mETa-learning (MUPPET) method. This is enabled by efficiently bridging pretrained vision and language models whilst maximally reusing already learned capacity. Concretely, we construct multi-modal prompts by mapping support videos into the textual token space of a vision-language model using a meta-learned adapter-equipped visual semantics tokenizer. To tackle large intra-class variation, we further design a query feature regulation scheme. Extensive experiments on ActivityNetv1.3 and THUMOS14 demonstrate that our MUPPET outperforms state-of-the-art alternative methods, often by a large margin. We also show that our MUPPET can be easily extended to tackle the few-shot object detection problem and again achieves the state-of-the-art performance on MS-COCO dataset. The code will be available in https://github.com/sauradip/MUPPET
Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization
Nov 18, 2022



This paper deals with the problem of localizing objects in image and video datasets from visual exemplars. In particular, we focus on the challenging problem of egocentric visual query localization. We first identify grave implicit biases in current query-conditioned model design and visual query datasets. Then, we directly tackle such biases at both frame and object set levels. Concretely, our method solves these issues by expanding limited annotations and dynamically dropping object proposals during training. Additionally, we propose a novel transformer-based module that allows for object-proposal set context to be considered while incorporating query information. We name our module Conditioned Contextual Transformer or CocoFormer. Our experiments show the proposed adaptations improve egocentric query detection, leading to a better visual query localization system in both 2D and 3D configurations. Thus, we are able to improve frame-level detection performance from 26.28% to 31.26 in AP, which correspondingly improves the VQ2D and VQ3D localization scores by significant margins. Our improved context-aware query object detector ranked first and second in the VQ2D and VQ3D tasks in the 2nd Ego4D challenge. In addition to this, we showcase the relevance of our proposed model in the Few-Shot Detection (FSD) task, where we also achieve SOTA results. Our code is available at https://github.com/facebookresearch/vq2d_cvpr.
Negative Frames Matter in Egocentric Visual Query 2D Localization
Aug 03, 2022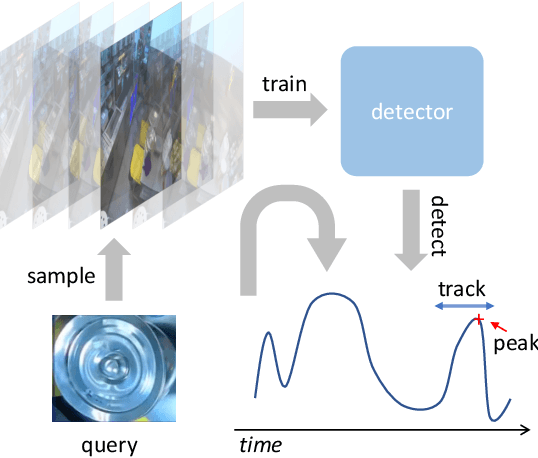
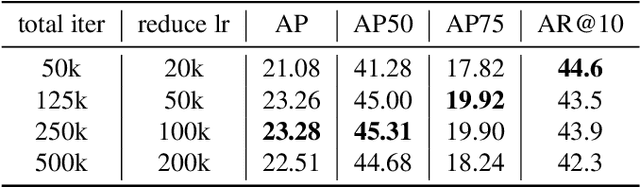

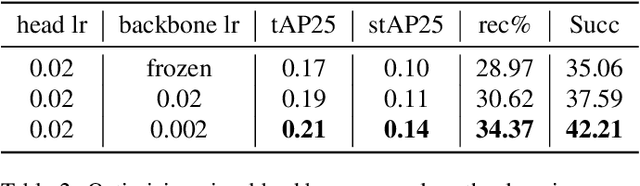
The recently released Ego4D dataset and benchmark significantly scales and diversifies the first-person visual perception data. In Ego4D, the Visual Queries 2D Localization task aims to retrieve objects appeared in the past from the recording in the first-person view. This task requires a system to spatially and temporally localize the most recent appearance of a given object query, where query is registered by a single tight visual crop of the object in a different scene. Our study is based on the three-stage baseline introduced in the Episodic Memory benchmark. The baseline solves the problem by detection and tracking: detect the similar objects in all the frames, then run a tracker from the most confident detection result. In the VQ2D challenge, we identified two limitations of the current baseline. (1) The training configuration has redundant computation. Although the training set has millions of instances, most of them are repetitive and the number of unique object is only around 14.6k. The repeated gradient computation of the same object lead to an inefficient training; (2) The false positive rate is high on background frames. This is due to the distribution gap between training and evaluation. During training, the model is only able to see the clean, stable, and labeled frames, but the egocentric videos also have noisy, blurry, or unlabeled background frames. To this end, we developed a more efficient and effective solution. Concretely, we bring the training loop from ~15 days to less than 24 hours, and we achieve 0.17% spatial-temporal AP, which is 31% higher than the baseline. Our solution got the first ranking on the public leaderboard. Our code is publicly available at https://github.com/facebookresearch/vq2d_cvpr.
ETAD: A Unified Framework for Efficient Temporal Action Detection
May 14, 2022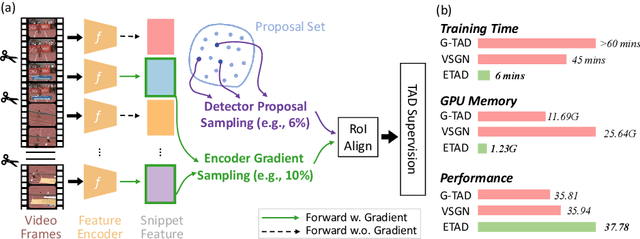
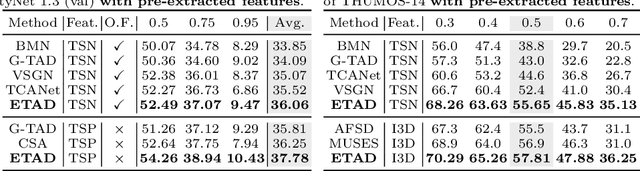
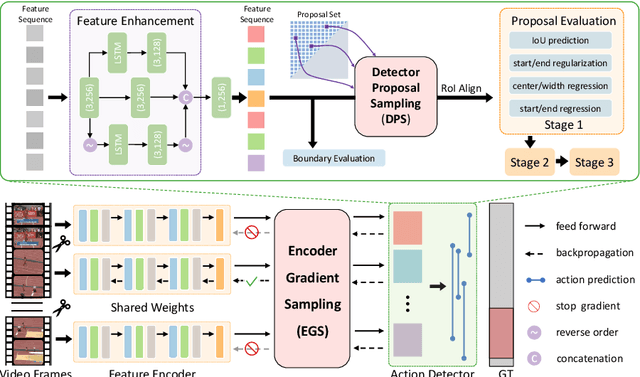
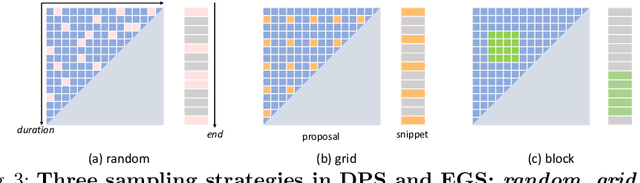
Untrimmed video understanding such as temporal action detection (TAD) often suffers from the pain of huge demand for computing resources. Because of long video durations and limited GPU memory, most action detectors can only operate on pre-extracted features rather than the original videos, and they still require a lot of computation to achieve high detection performance. To alleviate the heavy computation problem in TAD, in this work, we first propose an efficient action detector with detector proposal sampling, based on the observation that performance saturates at a small number of proposals. This detector is designed with several important techniques, such as LSTM-boosted temporal aggregation and cascaded proposal refinement to achieve high detection quality as well as low computational cost. To enable joint optimization of this action detector and the feature encoder, we also propose encoder gradient sampling, which selectively back-propagates through video snippets and tremendously reduces GPU memory consumption. With the two sampling strategies and the effective detector, we build a unified framework for efficient end-to-end temporal action detection (ETAD), making real-world untrimmed video understanding tractable. ETAD achieves state-of-the-art performance on both THUMOS-14 and ActivityNet-1.3. Interestingly, on ActivityNet-1.3, it reaches 37.78% average mAP, while only requiring 6 mins of training time and 1.23 GB memory based on pre-extracted features. With end-to-end training, it reduces the GPU memory footprint by more than 70% with even higher performance (38.21% average mAP), as compared with traditional end-to-end methods. The code is available at https://github.com/sming256/ETAD.
Contrastive Language-Action Pre-training for Temporal Localization
Apr 26, 2022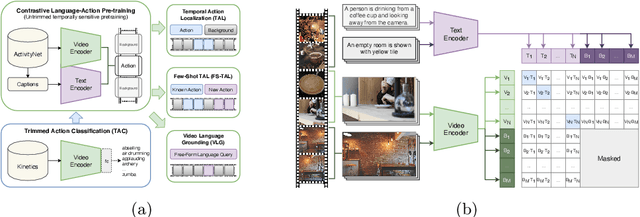
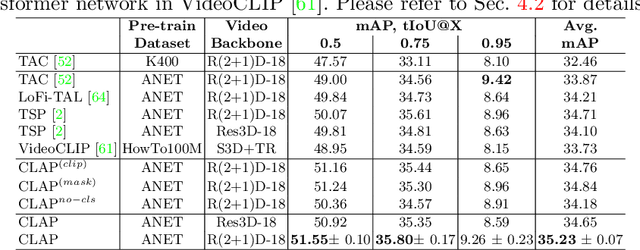
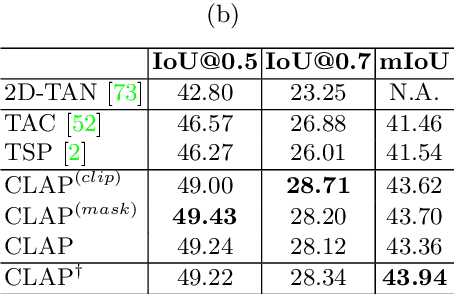
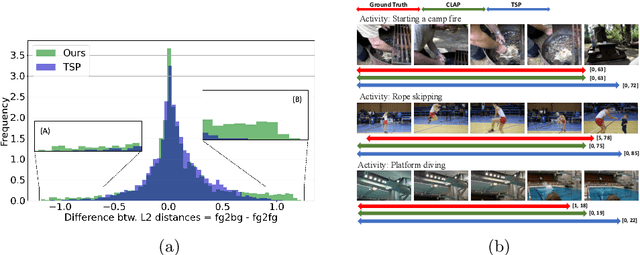
Long-form video understanding requires designing approaches that are able to temporally localize activities or language. End-to-end training for such tasks is limited by the compute device memory constraints and lack of temporal annotations at large-scale. These limitations can be addressed by pre-training on large datasets of temporally trimmed videos supervised by class annotations. Once the video encoder is pre-trained, it is common practice to freeze it during fine-tuning. Therefore, the video encoder does not learn temporal boundaries and unseen classes, causing a domain gap with respect to the downstream tasks. Moreover, using temporally trimmed videos prevents to capture the relations between different action categories and the background context in a video clip which results in limited generalization capacity. To address these limitations, we propose a novel post-pre-training approach without freezing the video encoder which leverages language. We introduce a masked contrastive learning loss to capture visio-linguistic relations between activities, background video clips and language in the form of captions. Our experiments show that the proposed approach improves the state-of-the-art on temporal action localization, few-shot temporal action localization, and video language grounding tasks.
SegTAD: Precise Temporal Action Detection via Semantic Segmentation
Mar 03, 2022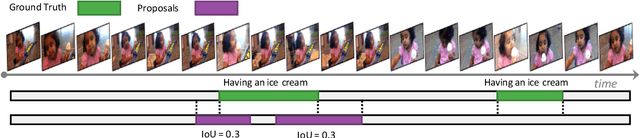
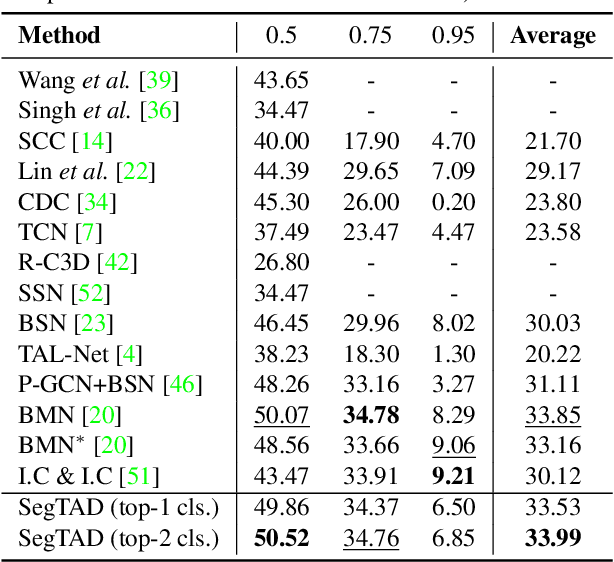
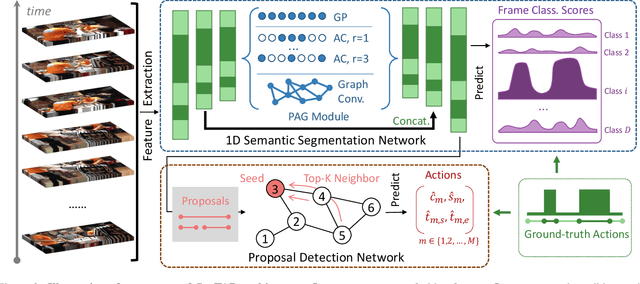
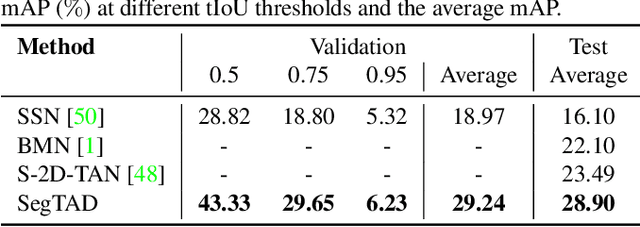
Temporal action detection (TAD) is an important yet challenging task in video analysis. Most existing works draw inspiration from image object detection and tend to reformulate it as a proposal generation - classification problem. However, there are two caveats with this paradigm. First, proposals are not equipped with annotated labels, which have to be empirically compiled, thus the information in the annotations is not necessarily precisely employed in the model training process. Second, there are large variations in the temporal scale of actions, and neglecting this fact may lead to deficient representation in the video features. To address these issues and precisely model temporal action detection, we formulate the task of temporal action detection in a novel perspective of semantic segmentation. Owing to the 1-dimensional property of TAD, we are able to convert the coarse-grained detection annotations to fine-grained semantic segmentation annotations for free. We take advantage of them to provide precise supervision so as to mitigate the impact induced by the imprecise proposal labels. We propose an end-to-end framework SegTAD composed of a 1D semantic segmentation network (1D-SSN) and a proposal detection network (PDN).
Relation-aware Video Reading Comprehension for Temporal Language Grounding
Oct 18, 2021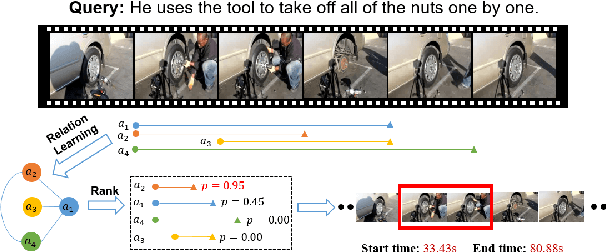
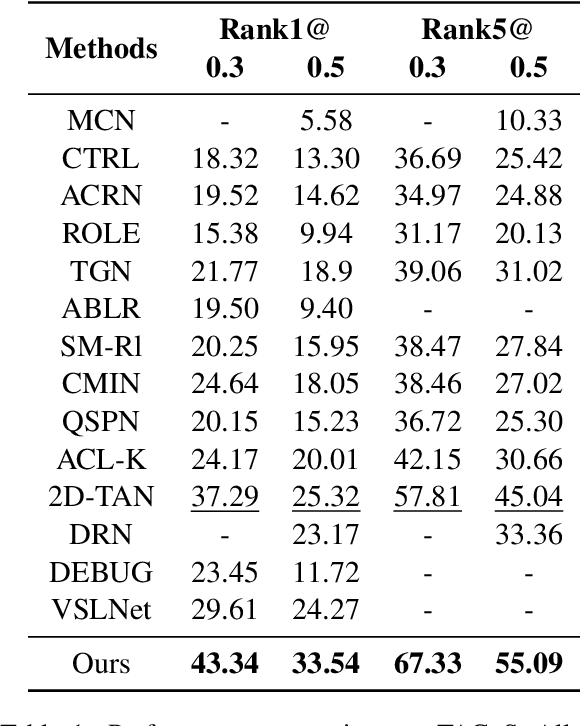
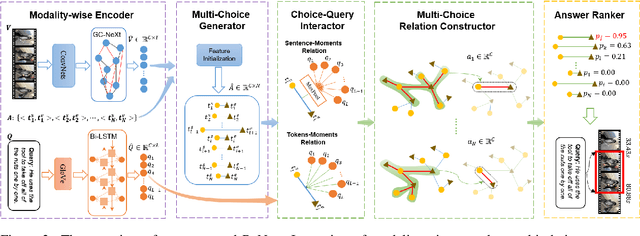
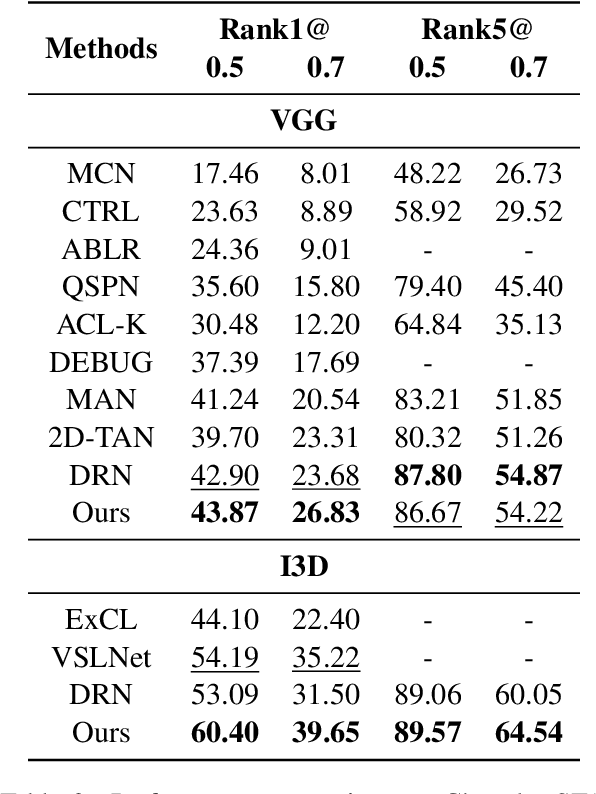
Temporal language grounding in videos aims to localize the temporal span relevant to the given query sentence. Previous methods treat it either as a boundary regression task or a span extraction task. This paper will formulate temporal language grounding into video reading comprehension and propose a Relation-aware Network (RaNet) to address it. This framework aims to select a video moment choice from the predefined answer set with the aid of coarse-and-fine choice-query interaction and choice-choice relation construction. A choice-query interactor is proposed to match the visual and textual information simultaneously in sentence-moment and token-moment levels, leading to a coarse-and-fine cross-modal interaction. Moreover, a novel multi-choice relation constructor is introduced by leveraging graph convolution to capture the dependencies among video moment choices for the best choice selection. Extensive experiments on ActivityNet-Captions, TACoS, and Charades-STA demonstrate the effectiveness of our solution. Codes will be released soon.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Low-Fidelity End-to-End Video Encoder Pre-training for Temporal Action Localization
Mar 30, 2021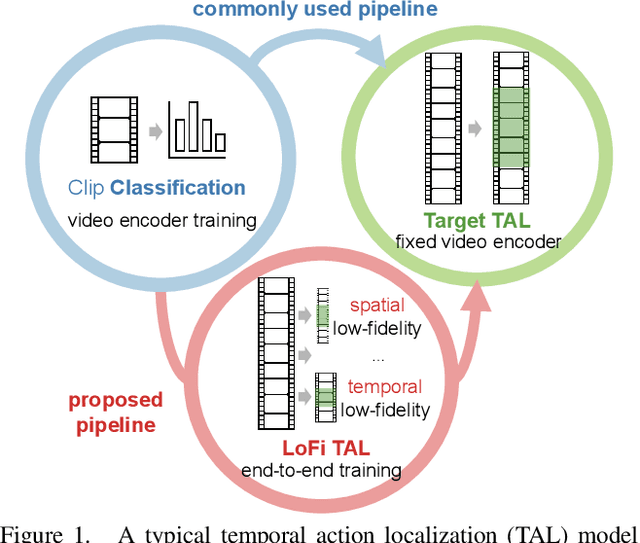
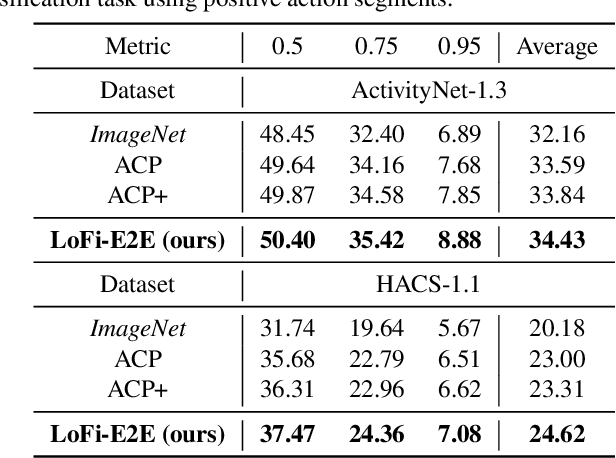
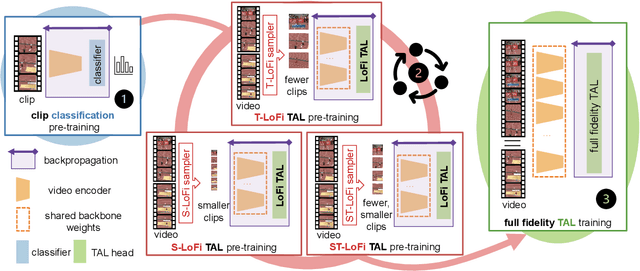
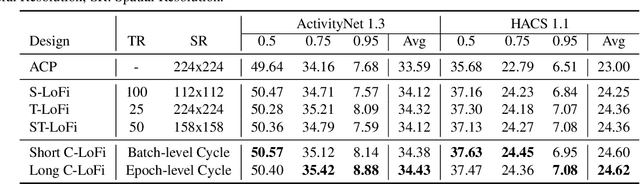
Temporal action localization (TAL) is a fundamental yet challenging task in video understanding. Existing TAL methods rely on pre-training a video encoder through action classification supervision. This results in a task discrepancy problem for the video encoder -- trained for action classification, but used for TAL. Intuitively, end-to-end model optimization is a good solution. However, this is not operable for TAL subject to the GPU memory constraints, due to the prohibitive computational cost in processing long untrimmed videos. In this paper, we resolve this challenge by introducing a novel low-fidelity end-to-end (LoFi) video encoder pre-training method. Instead of always using the full training configurations for TAL learning, we propose to reduce the mini-batch composition in terms of temporal, spatial or spatio-temporal resolution so that end-to-end optimization for the video encoder becomes operable under the memory conditions of a mid-range hardware budget. Crucially, this enables the gradient to flow backward through the video encoder from a TAL loss supervision, favourably solving the task discrepancy problem and providing more effective feature representations. Extensive experiments show that the proposed LoFi pre-training approach can significantly enhance the performance of existing TAL methods. Encouragingly, even with a lightweight ResNet18 based video encoder in a single RGB stream, our method surpasses two-stream ResNet50 based alternatives with expensive optical flow, often by a good margin.
Boundary-sensitive Pre-training for Temporal Localization in Videos
Nov 24, 2020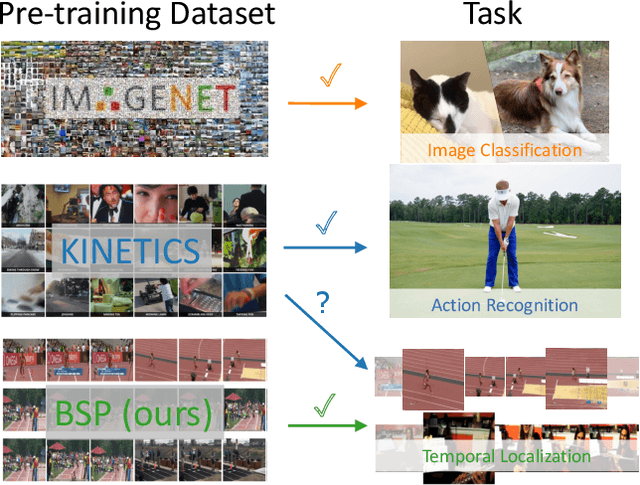
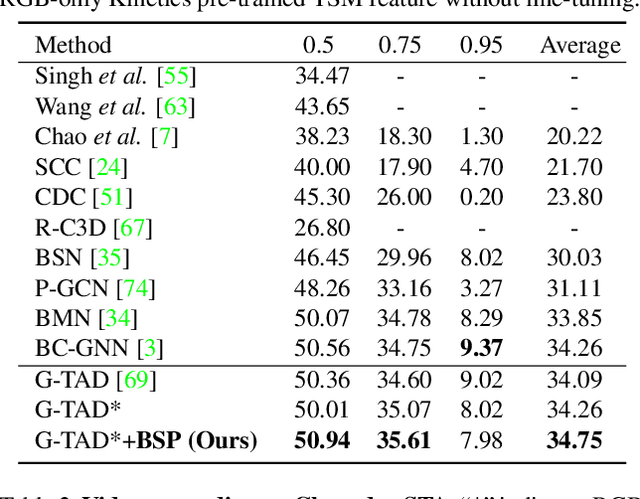

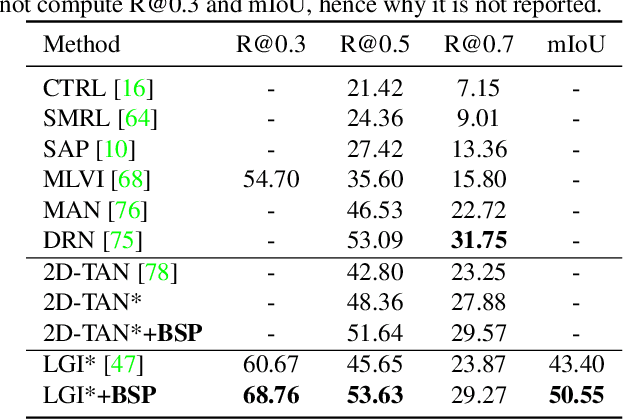
Many video analysis tasks require temporal localization thus detection of content changes. However, most existing models developed for these tasks are pre-trained on general video action classification tasks. This is because large scale annotation of temporal boundaries in untrimmed videos is expensive. Therefore no suitable datasets exist for temporal boundary-sensitive pre-training. In this paper for the first time, we investigate model pre-training for temporal localization by introducing a novel boundary-sensitive pretext (BSP) task. Instead of relying on costly manual annotations of temporal boundaries, we propose to synthesize temporal boundaries in existing video action classification datasets. With the synthesized boundaries, BSP can be simply conducted via classifying the boundary types. This enables the learning of video representations that are much more transferable to downstream temporal localization tasks. Extensive experiments show that the proposed BSP is superior and complementary to the existing action classification based pre-training counterpart, and achieves new state-of-the-art performance on several temporal localization tasks.