 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields
Dec 09, 2021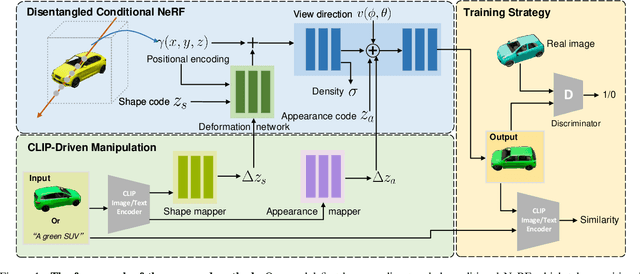
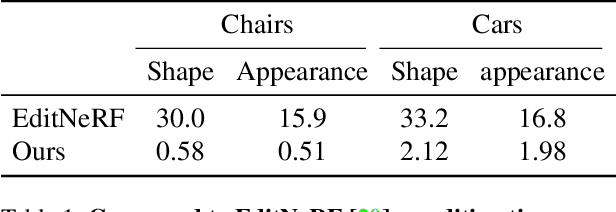
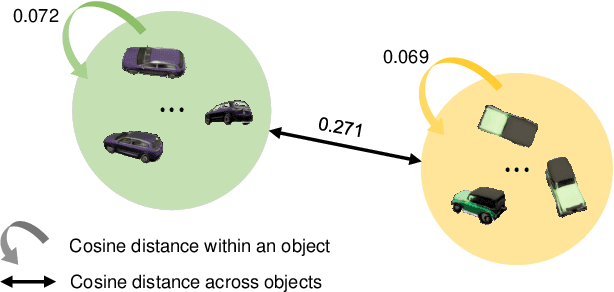
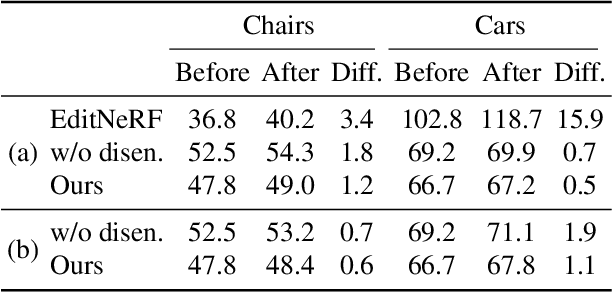
We present CLIP-NeRF, a multi-modal 3D object manipulation method for neural radiance fields (NeRF). By leveraging the joint language-image embedding space of the recent Contrastive Language-Image Pre-Training (CLIP) model, we propose a unified framework that allows manipulating NeRF in a user-friendly way, using either a short text prompt or an exemplar image. Specifically, to combine the novel view synthesis capability of NeRF and the controllable manipulation ability of latent representations from generative models, we introduce a disentangled conditional NeRF architecture that allows individual control over both shape and appearance. This is achieved by performing the shape conditioning via applying a learned deformation field to the positional encoding and deferring color conditioning to the volumetric rendering stage. To bridge this disentangled latent representation to the CLIP embedding, we design two code mappers that take a CLIP embedding as input and update the latent codes to reflect the targeted editing. The mappers are trained with a CLIP-based matching loss to ensure the manipulation accuracy. Furthermore, we propose an inverse optimization method that accurately projects an input image to the latent codes for manipulation to enable editing on real images. We evaluate our approach by extensive experiments on a variety of text prompts and exemplar images and also provide an intuitive interface for interactive editing. Our implementation is available at https://cassiepython.github.io/clipnerf/
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
Sep 16, 2021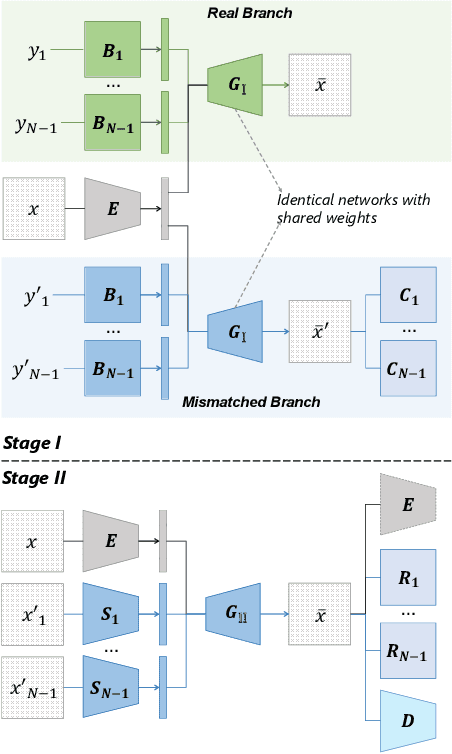
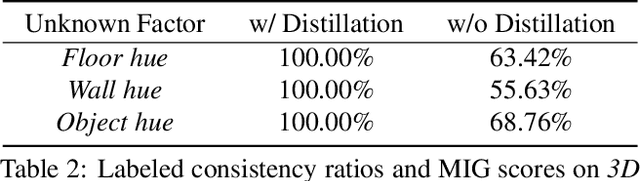
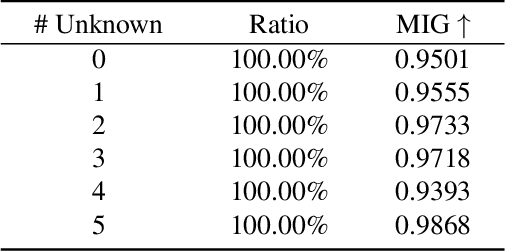

Disentangling data into interpretable and independent factors is critical for controllable generation tasks. With the availability of labeled data, supervision can help enforce the separation of specific factors as expected. However, it is often expensive or even impossible to label every single factor to achieve fully-supervised disentanglement. In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. Under this setting, we propose a flexible weakly-supervised multi-factor disentanglement framework DisUnknown, which Distills Unknown factors for enabling multi-conditional generation regarding both labeled and unknown factors. Specifically, a two-stage training approach is adopted to first disentangle the unknown factor with an effective and robust training method, and then train the final generator with the proper disentanglement of all labeled factors utilizing the unknown distillation. To demonstrate the generalization capacity and scalability of our method, we evaluate it on multiple benchmark datasets qualitatively and quantitatively and further apply it to various real-world applications on complicated datasets.
Flow Guided Transformable Bottleneck Networks for Motion Retargeting
Jun 14, 2021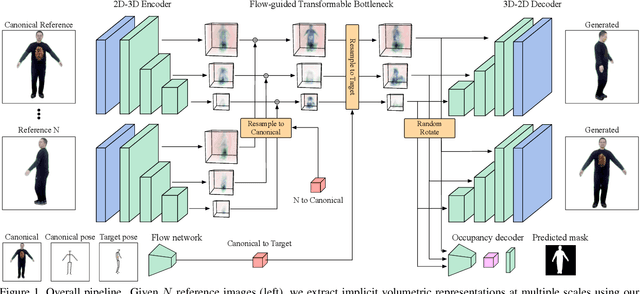
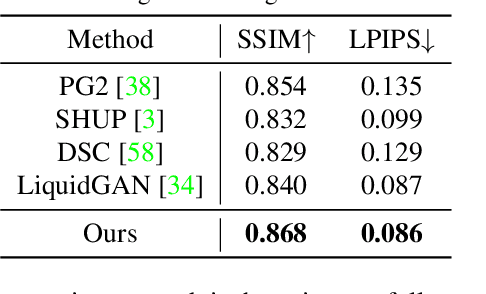

Human motion retargeting aims to transfer the motion of one person in a "driving" video or set of images to another person. Existing efforts leverage a long training video from each target person to train a subject-specific motion transfer model. However, the scalability of such methods is limited, as each model can only generate videos for the given target subject, and such training videos are labor-intensive to acquire and process. Few-shot motion transfer techniques, which only require one or a few images from a target, have recently drawn considerable attention. Methods addressing this task generally use either 2D or explicit 3D representations to transfer motion, and in doing so, sacrifice either accurate geometric modeling or the flexibility of an end-to-end learned representation. Inspired by the Transformable Bottleneck Network, which renders novel views and manipulations of rigid objects, we propose an approach based on an implicit volumetric representation of the image content, which can then be spatially manipulated using volumetric flow fields. We address the challenging question of how to aggregate information across different body poses, learning flow fields that allow for combining content from the appropriate regions of input images of highly non-rigid human subjects performing complex motions into a single implicit volumetric representation. This allows us to learn our 3D representation solely from videos of moving people. Armed with both 3D object understanding and end-to-end learned rendering, this categorically novel representation delivers state-of-the-art image generation quality, as shown by our quantitative and qualitative evaluations.
A Good Image Generator Is What You Need for High-Resolution Video Synthesis
Apr 30, 2021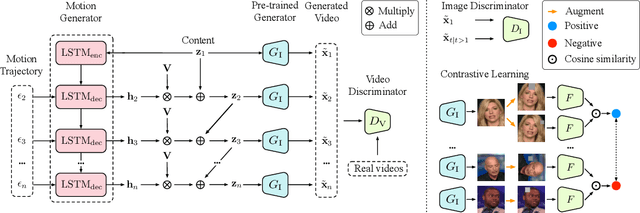



Image and video synthesis are closely related areas aiming at generating content from noise. While rapid progress has been demonstrated in improving image-based models to handle large resolutions, high-quality renderings, and wide variations in image content, achieving comparable video generation results remains problematic. We present a framework that leverages contemporary image generators to render high-resolution videos. We frame the video synthesis problem as discovering a trajectory in the latent space of a pre-trained and fixed image generator. Not only does such a framework render high-resolution videos, but it also is an order of magnitude more computationally efficient. We introduce a motion generator that discovers the desired trajectory, in which content and motion are disentangled. With such a representation, our framework allows for a broad range of applications, including content and motion manipulation. Furthermore, we introduce a new task, which we call cross-domain video synthesis, in which the image and motion generators are trained on disjoint datasets belonging to different domains. This allows for generating moving objects for which the desired video data is not available. Extensive experiments on various datasets demonstrate the advantages of our methods over existing video generation techniques. Code will be released at https://github.com/snap-research/MoCoGAN-HD.
Exemplar-Based 3D Portrait Stylization
Apr 29, 2021

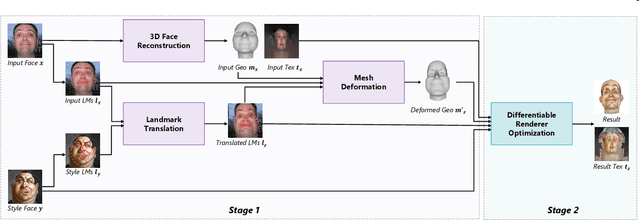

Exemplar-based portrait stylization is widely attractive and highly desired. Despite recent successes, it remains challenging, especially when considering both texture and geometric styles. In this paper, we present the first framework for one-shot 3D portrait style transfer, which can generate 3D face models with both the geometry exaggerated and the texture stylized while preserving the identity from the original content. It requires only one arbitrary style image instead of a large set of training examples for a particular style, provides geometry and texture outputs that are fully parameterized and disentangled, and enables further graphics applications with the 3D representations. The framework consists of two stages. In the first geometric style transfer stage, we use facial landmark translation to capture the coarse geometry style and guide the deformation of the dense 3D face geometry. In the second texture style transfer stage, we focus on performing style transfer on the canonical texture by adopting a differentiable renderer to optimize the texture in a multi-view framework. Experiments show that our method achieves robustly good results on different artistic styles and outperforms existing methods. We also demonstrate the advantages of our method via various 2D and 3D graphics applications. Project page is https://halfjoe.github.io/projs/3DPS/index.html.
Motion Representations for Articulated Animation
Apr 22, 2021

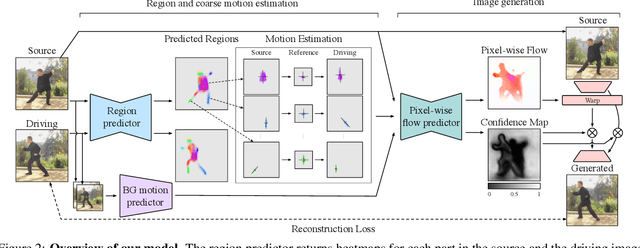

We propose novel motion representations for animating articulated objects consisting of distinct parts. In a completely unsupervised manner, our method identifies object parts, tracks them in a driving video, and infers their motions by considering their principal axes. In contrast to the previous keypoint-based works, our method extracts meaningful and consistent regions, describing locations, shape, and pose. The regions correspond to semantically relevant and distinct object parts, that are more easily detected in frames of the driving video. To force decoupling of foreground from background, we model non-object related global motion with an additional affine transformation. To facilitate animation and prevent the leakage of the shape of the driving object, we disentangle shape and pose of objects in the region space. Our model can animate a variety of objects, surpassing previous methods by a large margin on existing benchmarks. We present a challenging new benchmark with high-resolution videos and show that the improvement is particularly pronounced when articulated objects are considered, reaching 96.6% user preference vs. the state of the art.
Cross-Domain and Disentangled Face Manipulation with 3D Guidance
Apr 22, 2021
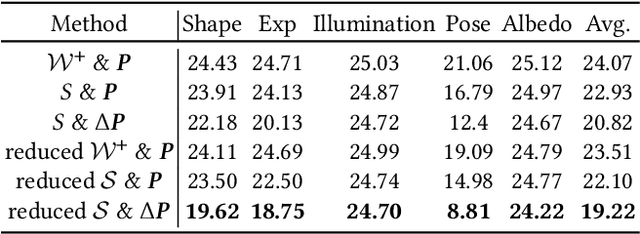
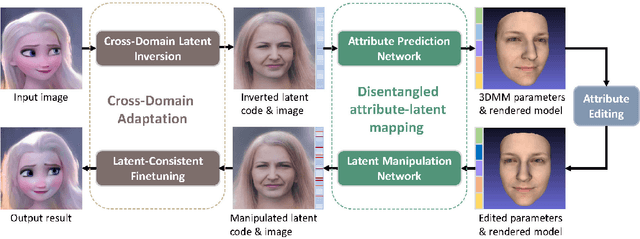
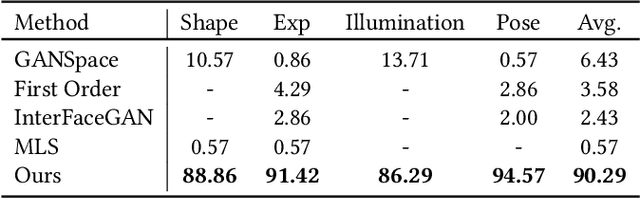
Face image manipulation via three-dimensional guidance has been widely applied in various interactive scenarios due to its semantically-meaningful understanding and user-friendly controllability. However, existing 3D-morphable-model-based manipulation methods are not directly applicable to out-of-domain faces, such as non-photorealistic paintings, cartoon portraits, or even animals, mainly due to the formidable difficulties in building the model for each specific face domain. To overcome this challenge, we propose, as far as we know, the first method to manipulate faces in arbitrary domains using human 3DMM. This is achieved through two major steps: 1) disentangled mapping from 3DMM parameters to the latent space embedding of a pre-trained StyleGAN2 that guarantees disentangled and precise controls for each semantic attribute; and 2) cross-domain adaptation that bridges domain discrepancies and makes human 3DMM applicable to out-of-domain faces by enforcing a consistent latent space embedding. Experiments and comparisons demonstrate the superiority of our high-quality semantic manipulation method on a variety of face domains with all major 3D facial attributes controllable: pose, expression, shape, albedo, and illumination. Moreover, we develop an intuitive editing interface to support user-friendly control and instant feedback. Our project page is https://cassiepython.github.io/sigasia/cddfm3d.html.
Diverse Semantic Image Synthesis via Probability Distribution Modeling
Mar 11, 2021
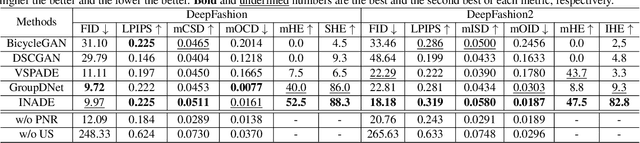
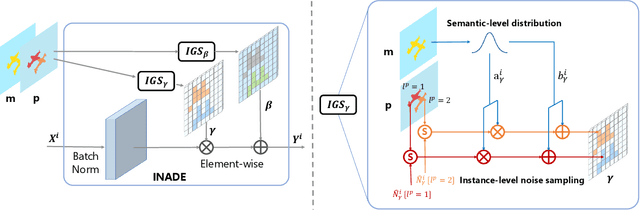
Semantic image synthesis, translating semantic layouts to photo-realistic images, is a one-to-many mapping problem. Though impressive progress has been recently made, diverse semantic synthesis that can efficiently produce semantic-level multimodal results, still remains a challenge. In this paper, we propose a novel diverse semantic image synthesis framework from the perspective of semantic class distributions, which naturally supports diverse generation at semantic or even instance level. We achieve this by modeling class-level conditional modulation parameters as continuous probability distributions instead of discrete values, and sampling per-instance modulation parameters through instance-adaptive stochastic sampling that is consistent across the network. Moreover, we propose prior noise remapping, through linear perturbation parameters encoded from paired references, to facilitate supervised training and exemplar-based instance style control at test time. Extensive experiments on multiple datasets show that our method can achieve superior diversity and comparable quality compared to state-of-the-art methods. Code will be available at \url{https://github.com/tzt101/INADE.git}
Semantic Image Synthesis via Efficient Class-Adaptive Normalization
Dec 08, 2020

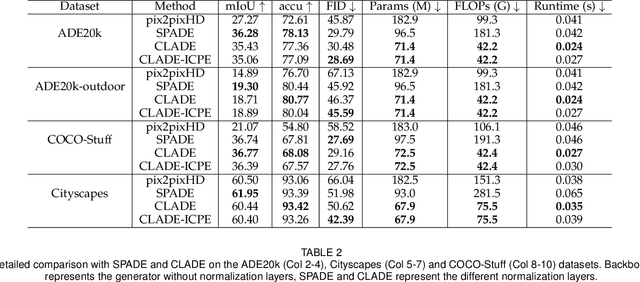
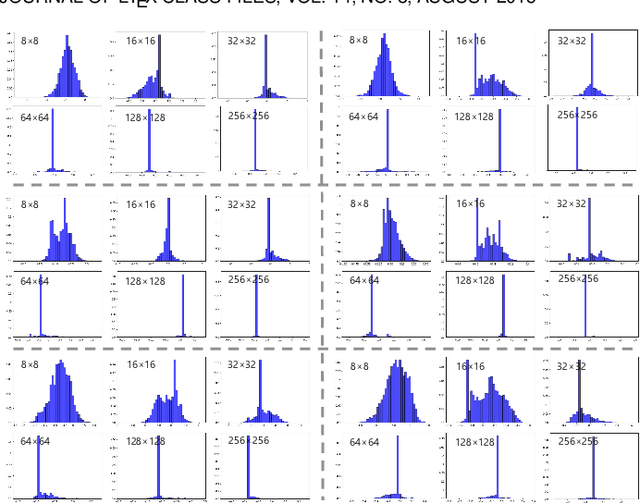
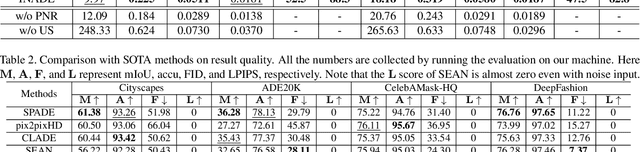
Spatially-adaptive normalization (SPADE) is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to prevent the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the advantages inside the box is still highly demanded to help reduce the significant computation and parameter overhead introduced by this novel structure. In this paper, from a return-on-investment point of view, we conduct an in-depth analysis of the effectiveness of this spatially-adaptive normalization and observe that its modulation parameters benefit more from semantic-awareness rather than spatial-adaptiveness, especially for high-resolution input masks. Inspired by this observation, we propose class-adaptive normalization (CLADE), a lightweight but equally-effective variant that is only adaptive to semantic class. In order to further improve spatial-adaptiveness, we introduce intra-class positional map encoding calculated from semantic layouts to modulate the normalization parameters of CLADE and propose a truly spatially-adaptive variant of CLADE, namely CLADE-ICPE. %Benefiting from this design, CLADE greatly reduces the computation cost while being able to preserve the semantic information in the generation. Through extensive experiments on multiple challenging datasets, we demonstrate that the proposed CLADE can be generalized to different SPADE-based methods while achieving comparable generation quality compared to SPADE, but it is much more efficient with fewer extra parameters and lower computational cost. The code is available at https://github.com/tzt101/CLADE.git
MichiGAN: Multi-Input-Conditioned Hair Image Generation for Portrait Editing
Oct 30, 2020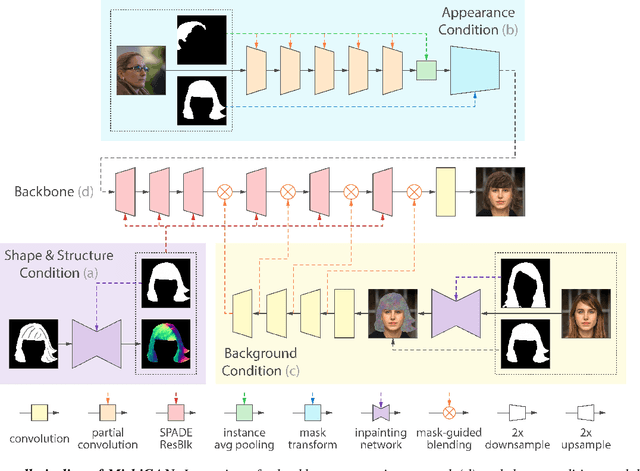
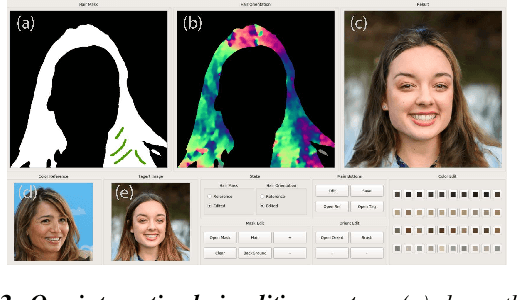
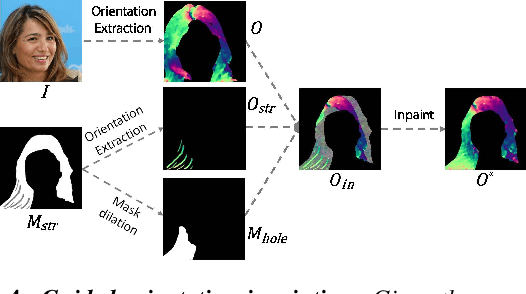

Despite the recent success of face image generation with GANs, conditional hair editing remains challenging due to the under-explored complexity of its geometry and appearance. In this paper, we present MichiGAN (Multi-Input-Conditioned Hair Image GAN), a novel conditional image generation method for interactive portrait hair manipulation. To provide user control over every major hair visual factor, we explicitly disentangle hair into four orthogonal attributes, including shape, structure, appearance, and background. For each of them, we design a corresponding condition module to represent, process, and convert user inputs, and modulate the image generation pipeline in ways that respect the natures of different visual attributes. All these condition modules are integrated with the backbone generator to form the final end-to-end network, which allows fully-conditioned hair generation from multiple user inputs. Upon it, we also build an interactive portrait hair editing system that enables straightforward manipulation of hair by projecting intuitive and high-level user inputs such as painted masks, guiding strokes, or reference photos to well-defined condition representations. Through extensive experiments and evaluations, we demonstrate the superiority of our method regarding both result quality and user controllability. The code is available at https://github.com/tzt101/MichiGAN.