 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.
Convolutional-LSTM for Multi-Image to Single Output Medical Prediction
Oct 20, 2020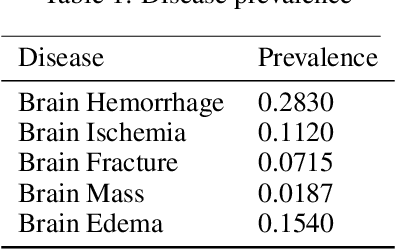
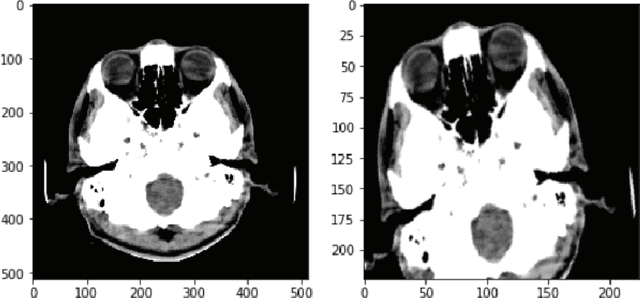
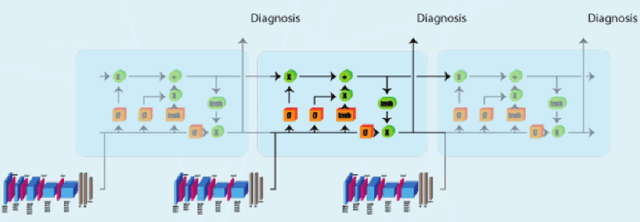
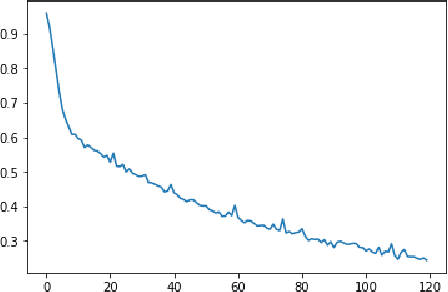
Medical head CT-scan imaging has been successfully combined with deep learning for medical diagnostics of head diseases and lesions[1]. State of the art classification models and algorithms for this task usually are based on 3d convolution layers for volumetric data on a supervised learning setting (1 input volume, 1 prediction per patient) or 2d convolution layers in a supervised setting (1 input image, 1 prediction per image). However a very common scenario in developing countries is to have the volume metadata lost due multiple reasons for example formatting conversion in images (for example .dicom to jpg), in this scenario the doctor analyses the collection of images and then emits a single diagnostic for the patient (with possibly an unfixed and variable number of images per patient) , this prevents it from being possible to use state of the art 3d models, but also is not possible to convert it to a supervised problem in a (1 image,1 diagnostic) setting because different angles or positions of the images for a single patient may not contain the disease or lesion. In this study we propose a solution for this scenario by combining 2d convolutional[2] models with sequence models which generate a prediction only after all images have been processed by the model for a given patient \(i\), this creates a multi-image to single-diagnostic setting \(y^i=f(x_1,x_2,..,x_n)\) where \(n\) may be different between patients. The experimental results demonstrate that it is possible to get a multi-image to single diagnostic model which mimics human doctor diagnostic process: evaluate the collection of patient images and then use important information in memory to decide a single diagnostic for the patient.