 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Interpretable Subspaces in Image Representations
Jul 20, 2023We propose Automatic Feature Explanation using Contrasting Concepts (FALCON), an interpretability framework to explain features of image representations. For a target feature, FALCON captions its highly activating cropped images using a large captioning dataset (like LAION-400m) and a pre-trained vision-language model like CLIP. Each word among the captions is scored and ranked leading to a small number of shared, human-understandable concepts that closely describe the target feature. FALCON also applies contrastive interpretation using lowly activating (counterfactual) images, to eliminate spurious concepts. Although many existing approaches interpret features independently, we observe in state-of-the-art self-supervised and supervised models, that less than 20% of the representation space can be explained by individual features. We show that features in larger spaces become more interpretable when studied in groups and can be explained with high-order scoring concepts through FALCON. We discuss how extracted concepts can be used to explain and debug failures in downstream tasks. Finally, we present a technique to transfer concepts from one (explainable) representation space to another unseen representation space by learning a simple linear transformation.
ViP: A Differentially Private Foundation Model for Computer Vision
Jun 28, 2023Artificial intelligence (AI) has seen a tremendous surge in capabilities thanks to the use of foundation models trained on internet-scale data. On the flip side, the uncurated nature of internet-scale data also poses significant privacy and legal risks, as they often contain personal information or copyrighted material that should not be trained on without permission. In this work, we propose as a mitigation measure a recipe to train foundation vision models with differential privacy (DP) guarantee. We identify masked autoencoders as a suitable learning algorithm that aligns well with DP-SGD, and train ViP -- a Vision transformer with differential Privacy -- under a strict privacy budget of $\epsilon=8$ on the LAION400M dataset. We evaluate the quality of representation learned by ViP using standard downstream vision tasks; in particular, ViP achieves a (non-private) linear probing accuracy of $55.7\%$ on ImageNet, comparable to that of end-to-end trained AlexNet (trained and evaluated on ImageNet). Our result suggests that scaling to internet-scale data can be practical for private learning. Code is available at \url{https://github.com/facebookresearch/ViP-MAE}.
Text-To-Concept via Cross-Model Alignment
May 10, 2023



We observe that the mapping between an image's representation in one model to its representation in another can be learned surprisingly well with just a linear layer, even across diverse models. Building on this observation, we propose $\textit{text-to-concept}$, where features from a fixed pretrained model are aligned linearly to the CLIP space, so that text embeddings from CLIP's text encoder become directly comparable to the aligned features. With text-to-concept, we convert fixed off-the-shelf vision encoders to surprisingly strong zero-shot classifiers for free, with accuracy at times even surpassing that of CLIP, despite being much smaller models and trained on a small fraction of the data compared to CLIP. We show other immediate use-cases of text-to-concept, like building concept bottleneck models with no concept supervision, diagnosing distribution shifts in terms of human concepts, and retrieving images satisfying a set of text-based constraints. Lastly, we demonstrate the feasibility of $\textit{concept-to-text}$, where vectors in a model's feature space are decoded by first aligning to the CLIP before being fed to a GPT-based generative model. Our work suggests existing deep models, with presumably diverse architectures and training, represent input samples relatively similarly, and a two-way communication across model representation spaces and to humans (through language) is viable.
Defending Against Patch-based Backdoor Attacks on Self-Supervised Learning
Apr 04, 2023



Recently, self-supervised learning (SSL) was shown to be vulnerable to patch-based data poisoning backdoor attacks. It was shown that an adversary can poison a small part of the unlabeled data so that when a victim trains an SSL model on it, the final model will have a backdoor that the adversary can exploit. This work aims to defend self-supervised learning against such attacks. We use a three-step defense pipeline, where we first train a model on the poisoned data. In the second step, our proposed defense algorithm (PatchSearch) uses the trained model to search the training data for poisoned samples and removes them from the training set. In the third step, a final model is trained on the cleaned-up training set. Our results show that PatchSearch is an effective defense. As an example, it improves a model's accuracy on images containing the trigger from 38.2% to 63.7% which is very close to the clean model's accuracy, 64.6%. Moreover, we show that PatchSearch outperforms baselines and state-of-the-art defense approaches including those using additional clean, trusted data. Our code is available at https://github.com/UCDvision/PatchSearch
Analyzing Privacy Leakage in Machine Learning via Multiple Hypothesis Testing: A Lesson From Fano
Oct 24, 2022



Differential privacy (DP) is by far the most widely accepted framework for mitigating privacy risks in machine learning. However, exactly how small the privacy parameter $\epsilon$ needs to be to protect against certain privacy risks in practice is still not well-understood. In this work, we study data reconstruction attacks for discrete data and analyze it under the framework of multiple hypothesis testing. We utilize different variants of the celebrated Fano's inequality to derive upper bounds on the inferential power of a data reconstruction adversary when the model is trained differentially privately. Importantly, we show that if the underlying private data takes values from a set of size $M$, then the target privacy parameter $\epsilon$ can be $O(\log M)$ before the adversary gains significant inferential power. Our analysis offers theoretical evidence for the empirical effectiveness of DP against data reconstruction attacks even at relatively large values of $\epsilon$.
Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning
Oct 14, 2022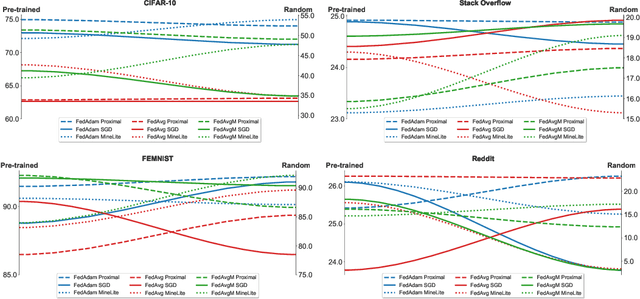

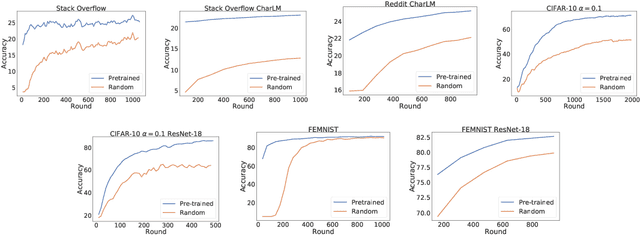
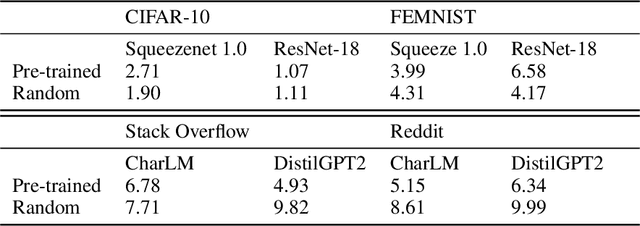
An oft-cited challenge of federated learning is the presence of heterogeneity. \emph{Data heterogeneity} refers to the fact that data from different clients may follow very different distributions. \emph{System heterogeneity} refers to the fact that client devices have different system capabilities. A considerable number of federated optimization methods address this challenge. In the literature, empirical evaluations usually start federated training from random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task that can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four standard federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables the training of more accurate models (up to 40\%) than is possible when starting from random initialization. Surprisingly, we also find that starting federated learning from a pre-trained initialization reduces the effect of both data and system heterogeneity. We recommend that future work proposing and evaluating federated optimization methods evaluate the performance when starting from random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
FRAME: Evaluating Simulatability Metrics for Free-Text Rationales
Jul 02, 2022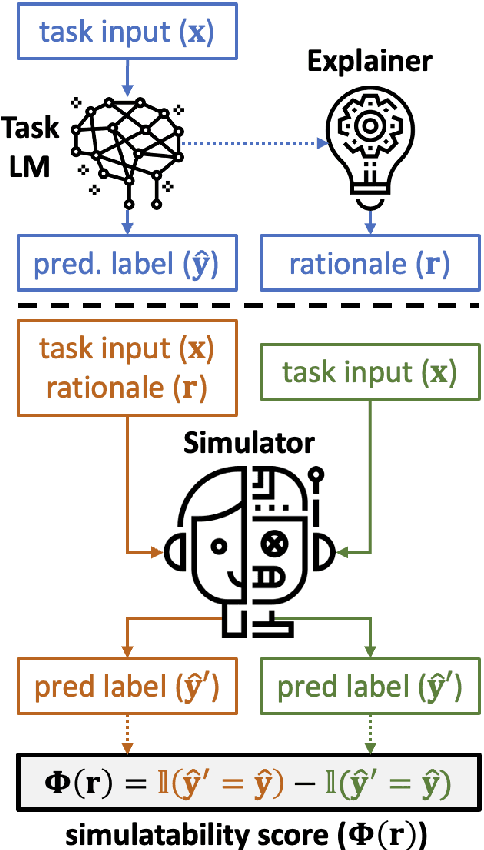
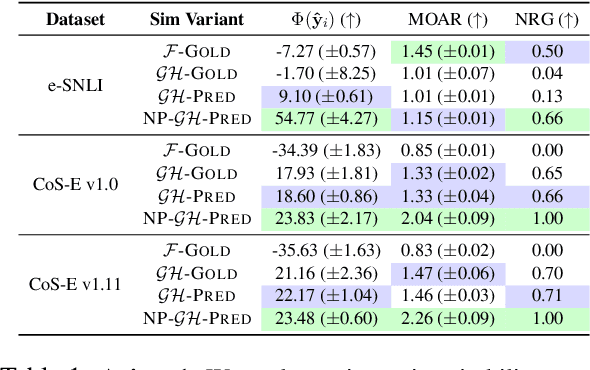

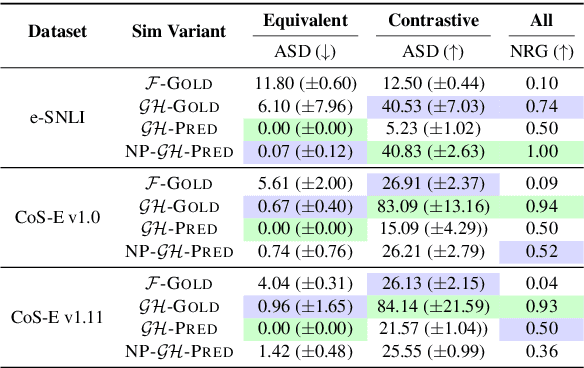
Free-text rationales aim to explain neural language model (LM) behavior more flexibly and intuitively via natural language. To ensure rationale quality, it is important to have metrics for measuring rationales' faithfulness (reflects LM's actual behavior) and plausibility (convincing to humans). All existing free-text rationale metrics are based on simulatability (association between rationale and LM's predicted label), but there is no protocol for assessing such metrics' reliability. To investigate this, we propose FRAME, a framework for evaluating free-text rationale simulatability metrics. FRAME is based on three axioms: (1) good metrics should yield highest scores for reference rationales, which maximize rationale-label association by construction; (2) good metrics should be appropriately sensitive to semantic perturbation of rationales; and (3) good metrics should be robust to variation in the LM's task performance. Across three text classification datasets, we show that existing simulatability metrics cannot satisfy all three FRAME axioms, since they are implemented via model pretraining which muddles the metric's signal. We introduce a non-pretraining simulatability variant that improves performance on (1) and (3) by an average of 41.7% and 42.9%, respectively, while performing competitively on (2).
Where to Begin? Exploring the Impact of Pre-Training and Initialization in Federated Learning
Jun 30, 2022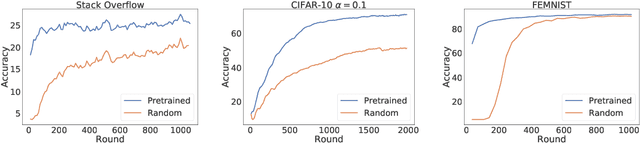



An oft-cited challenge of federated learning is the presence of data heterogeneity -- the data at different clients may follow very different distributions. Several federated optimization methods have been proposed to address these challenges. In the literature, empirical evaluations usually start federated training from a random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task which can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four common federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables training more accurate models (by up to 40\%) than is possible than when starting from a random initialization. Surprisingly, we also find that the effect of data heterogeneity is much less significant when starting federated training from a pre-trained initialization. Rather, when starting from a pre-trained model, using an adaptive optimizer at the server, such as \textsc{FedAdam}, consistently leads to the best accuracy. We recommend that future work proposing and evaluating federated optimization methods consider the performance when starting both random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
ER-TEST: Evaluating Explanation Regularization Methods for NLP Models
May 25, 2022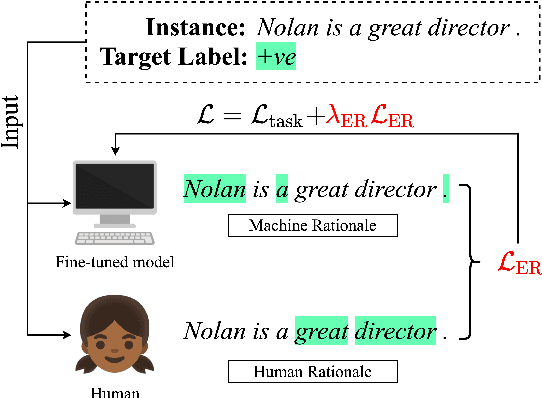
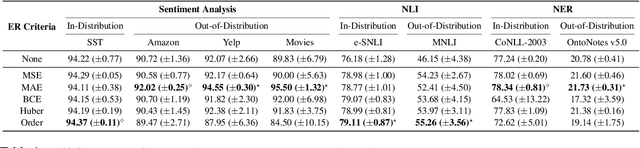
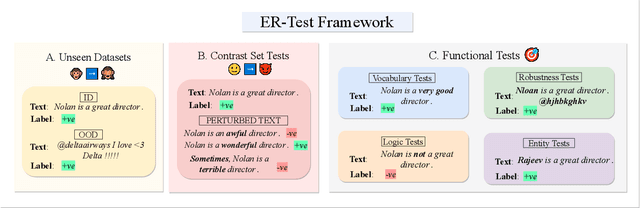
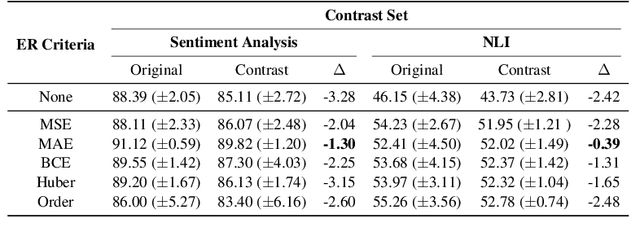
Neural language models' (NLMs') reasoning processes are notoriously hard to explain. Recently, there has been much progress in automatically generating machine rationales of NLM behavior, but less in utilizing the rationales to improve NLM behavior. For the latter, explanation regularization (ER) aims to improve NLM generalization by pushing the machine rationales to align with human rationales. Whereas prior works primarily evaluate such ER models via in-distribution (ID) generalization, ER's impact on out-of-distribution (OOD) is largely underexplored. Plus, little is understood about how ER model performance is affected by the choice of ER criteria or by the number/choice of training instances with human rationales. In light of this, we propose ER-TEST, a protocol for evaluating ER models' OOD generalization along three dimensions: (1) unseen datasets, (2) contrast set tests, and (3) functional tests. Using ER-TEST, we study three key questions: (A) Which ER criteria are most effective for the given OOD setting? (B) How is ER affected by the number/choice of training instances with human rationales? (C) Is ER effective with distantly supervised human rationales? ER-TEST enables comprehensive analysis of these questions by considering a diverse range of tasks and datasets. Through ER-TEST, we show that ER has little impact on ID performance, but can yield large gains on OOD performance w.r.t. (1)-(3). Also, we find that the best ER criterion is task-dependent, while ER can improve OOD performance even with limited and distantly-supervised human rationales.
FedShuffle: Recipes for Better Use of Local Work in Federated Learning
Apr 27, 2022

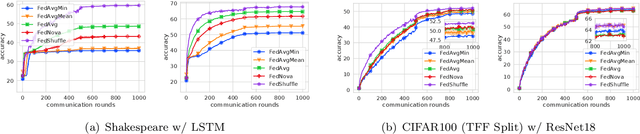

The practice of applying several local updates before aggregation across clients has been empirically shown to be a successful approach to overcoming the communication bottleneck in Federated Learning (FL). In this work, we propose a general recipe, FedShuffle, that better utilizes the local updates in FL, especially in the heterogeneous regime. Unlike many prior works, FedShuffle does not assume any uniformity in the number of updates per device. Our FedShuffle recipe comprises four simple-yet-powerful ingredients: 1) local shuffling of the data, 2) adjustment of the local learning rates, 3) update weighting, and 4) momentum variance reduction (Cutkosky and Orabona, 2019). We present a comprehensive theoretical analysis of FedShuffle and show that both theoretically and empirically, our approach does not suffer from the objective function mismatch that is present in FL methods which assume homogeneous updates in heterogeneous FL setups, e.g., FedAvg (McMahan et al., 2017). In addition, by combining the ingredients above, FedShuffle improves upon FedNova (Wang et al., 2020), which was previously proposed to solve this mismatch. We also show that FedShuffle with momentum variance reduction can improve upon non-local methods under a Hessian similarity assumption. Finally, through experiments on synthetic and real-world datasets, we illustrate how each of the four ingredients used in FedShuffle helps improve the use of local updates in FL.