 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effects of Sparse Attention on Cross-Encoders
Dec 29, 2023Cross-encoders are effective passage and document re-rankers but less efficient than other neural or classic retrieval models. A few previous studies have applied windowed self-attention to make cross-encoders more efficient. However, these studies did not investigate the potential and limits of different attention patterns or window sizes. We close this gap and systematically analyze how token interactions can be reduced without harming the re-ranking effectiveness. Experimenting with asymmetric attention and different window sizes, we find that the query tokens do not need to attend to the passage or document tokens for effective re-ranking and that very small window sizes suffice. In our experiments, even windows of 4 tokens still yield effectiveness on par with previous cross-encoders while reducing the memory requirements to at most 78% / 41% and being 1% / 43% faster at inference time for passages / documents.
Evaluating Generative Ad Hoc Information Retrieval
Nov 08, 2023



Recent advances in large language models have enabled the development of viable generative information retrieval systems. A generative retrieval system returns a grounded generated text in response to an information need instead of the traditional document ranking. Quantifying the utility of these types of responses is essential for evaluating generative retrieval systems. As the established evaluation methodology for ranking-based ad hoc retrieval may seem unsuitable for generative retrieval, new approaches for reliable, repeatable, and reproducible experimentation are required. In this paper, we survey the relevant information retrieval and natural language processing literature, identify search tasks and system architectures in generative retrieval, develop a corresponding user model, and study its operationalization. This theoretical analysis provides a foundation and new insights for the evaluation of generative ad hoc retrieval systems.
Commercialized Generative AI: A Critical Study of the Feasibility and Ethics of Generating Native Advertising Using Large Language Models in Conversational Web Search
Oct 07, 2023How will generative AI pay for itself? Unless charging users for access, selling advertising is the only alternative. Especially in the multi-billion dollar web search market with ads as the main source of revenue, the introduction of a subscription model seems unlikely. The recent disruption of search by generative large language models could thus ultimately be accompanied by generated ads. Our concern is that the commercialization of generative AI in general and large language models in particular could lead to native advertising in the form of quite subtle brand or product placements. In web search, the evolution of search engine results pages (SERPs) from traditional lists of ``ten blue links'' (lists SERPs) to generated text with web page references (text SERPs) may further blur the line between advertising-based and organic search results, making it difficult for users to distinguish between the two, depending on how advertising is integrated and disclosed. To raise awareness of this potential development, we conduct a pilot study analyzing the capabilities of current large language models to blend ads with organic search results. Although the models still struggle to subtly frame ads in an unrelated context, their potential is evident when integrating ads into related topics which calls for further investigation.
The Information Retrieval Experiment Platform
May 30, 2023We integrate ir_datasets, ir_measures, and PyTerrier with TIRA in the Information Retrieval Experiment Platform (TIREx) to promote more standardized, reproducible, scalable, and even blinded retrieval experiments. Standardization is achieved when a retrieval approach implements PyTerrier's interfaces and the input and output of an experiment are compatible with ir_datasets and ir_measures. However, none of this is a must for reproducibility and scalability, as TIRA can run any dockerized software locally or remotely in a cloud-native execution environment. Version control and caching ensure efficient (re)execution. TIRA allows for blind evaluation when an experiment runs on a remote server or cloud not under the control of the experimenter. The test data and ground truth are then hidden from public access, and the retrieval software has to process them in a sandbox that prevents data leaks. We currently host an instance of TIREx with 15 corpora (1.9 billion documents) on which 32 shared retrieval tasks are based. Using Docker images of 50 standard retrieval approaches, we automatically evaluated all approaches on all tasks (50 $\cdot$ 32 = 1,600~runs) in less than a week on a midsize cluster (1,620 CPU cores and 24 GPUs). This instance of TIREx is open for submissions and will be integrated with the IR Anthology, as well as released open source.
Perspectives on Large Language Models for Relevance Judgment
Apr 13, 2023



When asked, current large language models (LLMs) like ChatGPT claim that they can assist us with relevance judgments. Many researchers think this would not lead to credible IR research. In this perspective paper, we discuss possible ways for LLMs to assist human experts along with concerns and issues that arise. We devise a human-machine collaboration spectrum that allows categorizing different relevance judgment strategies, based on how much the human relies on the machine. For the extreme point of "fully automated assessment", we further include a pilot experiment on whether LLM-based relevance judgments correlate with judgments from trained human assessors. We conclude the paper by providing two opposing perspectives - for and against the use of LLMs for automatic relevance judgments - and a compromise perspective, informed by our analyses of the literature, our preliminary experimental evidence, and our experience as IR researchers. We hope to start a constructive discussion within the community to avoid a stale-mate during review, where work is dammed if is uses LLMs for evaluation and dammed if it doesn't.
The Archive Query Log: Mining Millions of Search Result Pages of Hundreds of Search Engines from 25 Years of Web Archives
Apr 02, 2023



The Archive Query Log (AQL) is a previously unused, comprehensive query log collected at the Internet Archive over the last 25 years. Its first version includes 356 million queries, 166 million search result pages, and 1.7 billion search results across 550 search providers. Although many query logs have been studied in the literature, the search providers that own them generally do not publish their logs to protect user privacy and vital business data. Of the few query logs publicly available, none combines size, scope, and diversity. The AQL is the first to do so, enabling research on new retrieval models and (diachronic) search engine analyses. Provided in a privacy-preserving manner, it promotes open research as well as more transparency and accountability in the search industry.
Paraphrase Acquisition from Image Captions
Jan 26, 2023



We propose to use captions from the Web as a previously underutilized resource for paraphrases (i.e., texts with the same "message") and to create and analyze a corresponding dataset. When an image is reused on the Web, an original caption is often assigned. We hypothesize that different captions for the same image naturally form a set of mutual paraphrases. To demonstrate the suitability of this idea, we analyze captions in the English Wikipedia, where editors frequently relabel the same image for different articles. The paper introduces the underlying mining technology and compares known paraphrase corpora with respect to their syntactic and semantic paraphrase similarity to our new resource. In this context, we introduce characteristic maps along the two similarity dimensions to identify the style of paraphrases coming from different sources. An annotation study demonstrates the high reliability of the algorithmically determined characteristic maps.
Sparse Pairwise Re-ranking with Pre-trained Transformers
Jul 10, 2022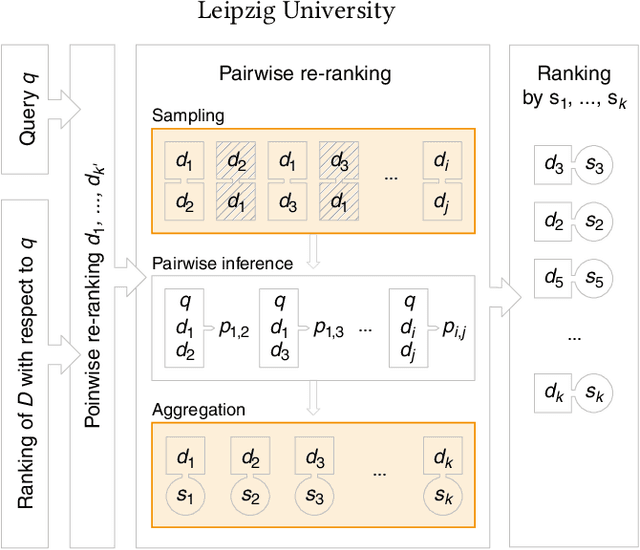
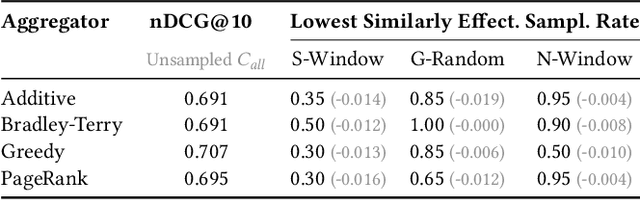

Pairwise re-ranking models predict which of two documents is more relevant to a query and then aggregate a final ranking from such preferences. This is often more effective than pointwise re-ranking models that directly predict a relevance value for each document. However, the high inference overhead of pairwise models limits their practical application: usually, for a set of $k$ documents to be re-ranked, preferences for all $k^2-k$ comparison pairs excluding self-comparisons are aggregated. We investigate whether the efficiency of pairwise re-ranking can be improved by sampling from all pairs. In an exploratory study, we evaluate three sampling methods and five preference aggregation methods. The best combination allows for an order of magnitude fewer comparisons at an acceptable loss of retrieval effectiveness, while competitive effectiveness is already achieved with about one third of the comparisons.
How Train-Test Leakage Affects Zero-shot Retrieval
Jun 29, 2022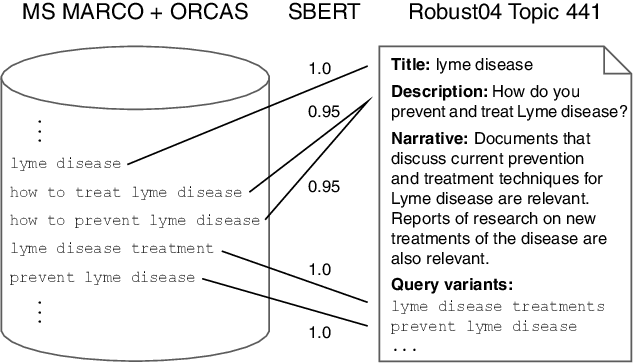
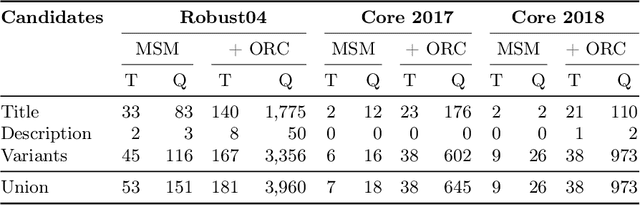

Neural retrieval models are often trained on (subsets of) the millions of queries of the MS MARCO / ORCAS datasets and then tested on the 250 Robust04 queries or other TREC benchmarks with often only 50 queries. In such setups, many of the few test queries can be very similar to queries from the huge training data -- in fact, 69% of the Robust04 queries have near-duplicates in MS MARCO / ORCAS. We investigate the impact of this unintended train-test leakage by training neural retrieval models on combinations of a fixed number of MS MARCO / ORCAS queries that are highly similar to the actual test queries and an increasing number of other queries. We find that leakage can improve effectiveness and even change the ranking of systems. However, these effects diminish as the amount of leakage among all training instances decreases and thus becomes more realistic.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.