 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation
Nov 13, 2025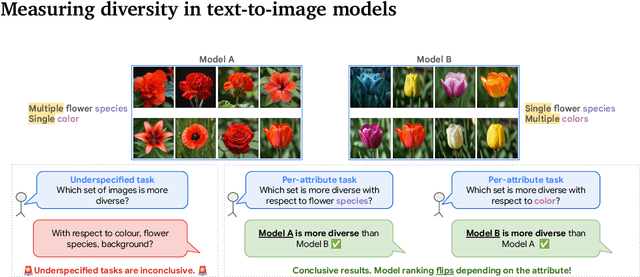
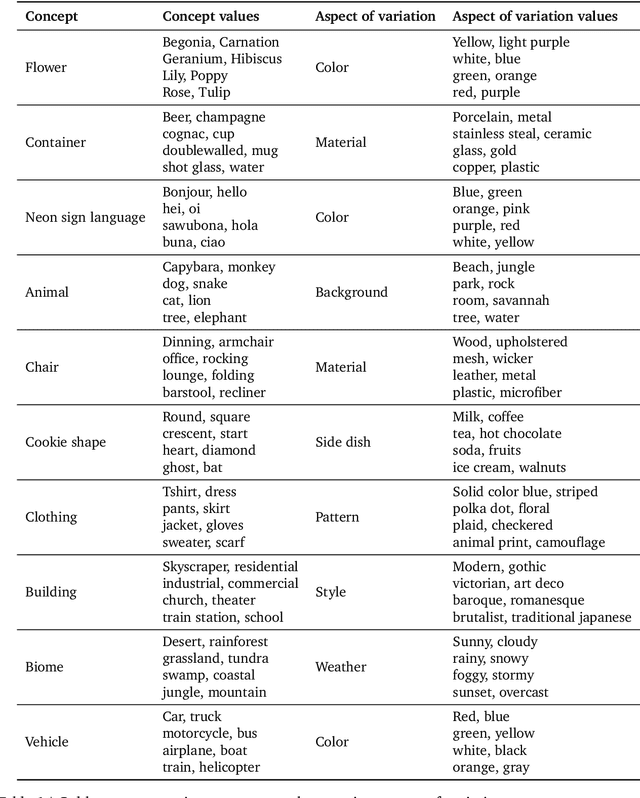
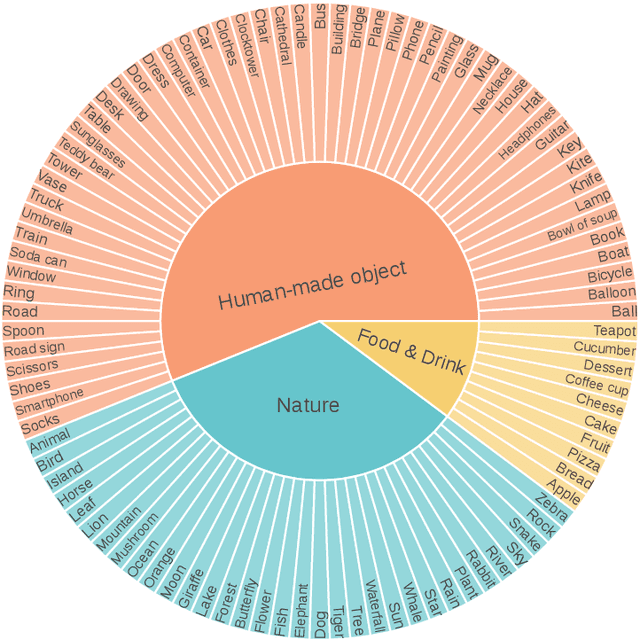
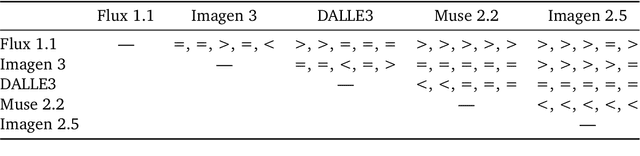
Despite advances in generation quality, current text-to-image (T2I) models often lack diversity, generating homogeneous outputs. This work introduces a framework to address the need for robust diversity evaluation in T2I models. Our framework systematically assesses diversity by evaluating individual concepts and their relevant factors of variation. Key contributions include: (1) a novel human evaluation template for nuanced diversity assessment; (2) a curated prompt set covering diverse concepts with their identified factors of variation (e.g. prompt: An image of an apple, factor of variation: color); and (3) a methodology for comparing models in terms of human annotations via binomial tests. Furthermore, we rigorously compare various image embeddings for diversity measurement. Notably, our principled approach enables ranking of T2I models by diversity, identifying categories where they particularly struggle. This research offers a robust methodology and insights, paving the way for improvements in T2I model diversity and metric development.
Evaluating Numerical Reasoning in Text-to-Image Models
Jun 20, 2024



Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as "a few" or "as many as"), the concept of zero, and struggle with more advanced concepts such as partial quantities and fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Evaluating Visual Number Discrimination in Deep Neural Networks
Mar 13, 2023



The ability to discriminate between large and small quantities is a core aspect of basic numerical competence in both humans and animals. In this work, we examine the extent to which the state-of-the-art neural networks designed for vision exhibit this basic ability. Motivated by studies in animal and infant numerical cognition, we use the numerical bisection procedure to test number discrimination in different families of neural architectures. Our results suggest that vision-specific inductive biases are helpful in numerosity discrimination, as models with such biases have lowest test errors on the task, and often have psychometric curves that qualitatively resemble those of humans and animals performing the task. However, even the strongest models, as measured on standard metrics of performance, fail to discriminate quantities in transfer experiments with differing training and testing conditions, indicating that such inductive biases might not be sufficient.
Rethinking Evaluation Practices in Visual Question Answering: A Case Study on Out-of-Distribution Generalization
May 24, 2022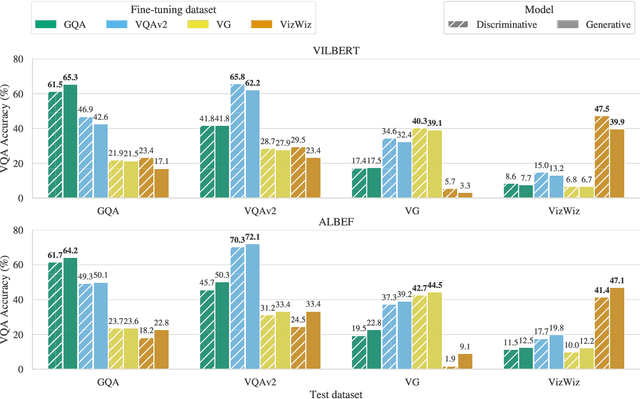
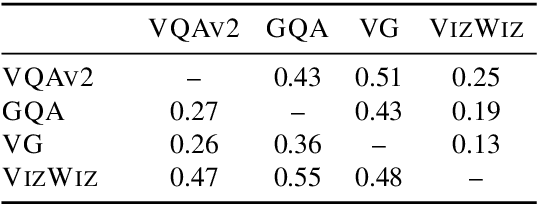
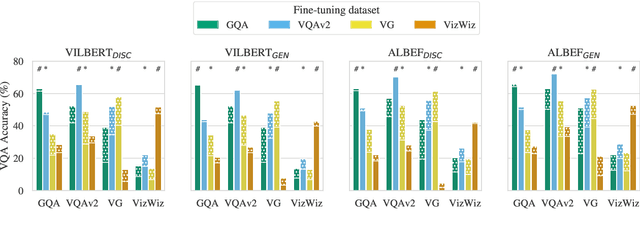
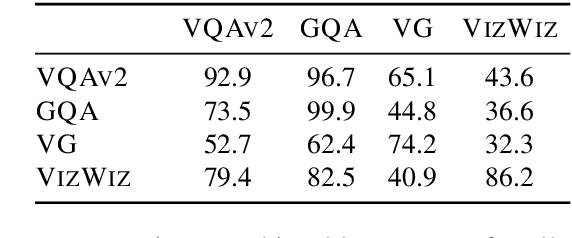
Vision-and-language (V&L) models pretrained on large-scale multimodal data have demonstrated strong performance on various tasks such as image captioning and visual question answering (VQA). The quality of such models is commonly assessed by measuring their performance on unseen data that typically comes from the same distribution as the training data. However, we observe that these models exhibit poor out-of-distribution (OOD) generalization on the task of VQA. To better understand the underlying causes of poor generalization, we comprehensively investigate performance of two pretrained V&L models under different settings (i.e. classification and open-ended text generation) by conducting cross-dataset evaluations. We find that these models tend to learn to solve the benchmark, rather than learning the high-level skills required by the VQA task. We also argue that in most cases generative models are less susceptible to shifts in data distribution, while frequently performing better on our tested benchmarks. Moreover, we find that multimodal pretraining improves OOD performance in most settings. Finally, we revisit assumptions underlying the use of automatic VQA evaluation metrics, and empirically show that their stringent nature repeatedly penalizes models for correct responses.
Learning to cooperate: Emergent communication in multi-agent navigation
Apr 02, 2020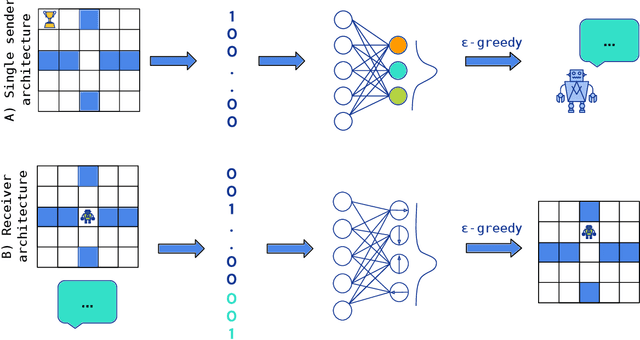

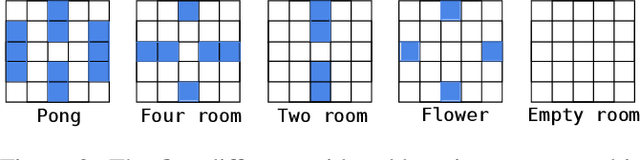
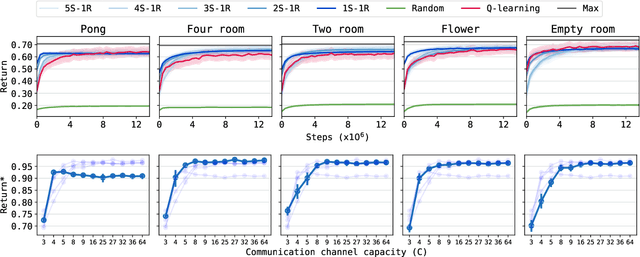
Emergent communication in artificial agents has been studied to understand language evolution, as well as to develop artificial systems that learn to communicate with humans. We show that agents performing a cooperative navigation task in various gridworld environments learn an interpretable communication protocol that enables them to efficiently, and in many cases, optimally, solve the task. An analysis of the agents' policies reveals that emergent signals spatially cluster the state space, with signals referring to specific locations and spatial directions such as "left", "up", or "upper left room". Using populations of agents, we show that the emergent protocol has basic compositional structure, thus exhibiting a core property of natural language.