 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Out-of-Equilibrium Phase Transitions can Seed Pattern Formation in Trained Diffusion Models
Mar 20, 2026In this work, we propose a theoretical framework that interprets the generation process in trained diffusion models as an instance of out-of-equilibrium phase transitions. We argue that, rather than evolving smoothly from noise to data, reverse diffusion passes through a critical regime in which small spatial fluctuations are amplified and seed the emergence of large-scale structure. Our central insight is that architectural constraints, such as locality, sparsity, and translation equivariance, transform memorization-driven instabilities into collective spatial modes, enabling the formation of coherent patterns beyond the training data. Using analytically tractable patch score models, we show how classical symmetry-breaking bifurcations generalize into spatially extended critical phenomena described by softening Fourier modes and growing correlation lengths. We further connect these dynamics to effective field theories of the Ginzburg-Landau type and to mechanisms of pattern formation in non-equilibrium physics. Empirical results on trained convolutional diffusion models corroborate the theory, revealing signatures of criticality including mode softening and rapid growth of spatial correlations. Finally, we demonstrate that this critical regime has practical relevance: targeted perturbations, such as classifier-free guidance pulses applied at the estimated critical time, significantly improve generation control. Together, these findings position non-equilibrium critical phenomena as a unifying principle for understanding, and potentially improving, the behavior of modern diffusion models.
Categorical Flow Maps
Feb 12, 2026We introduce Categorical Flow Maps, a flow-matching method for accelerated few-step generation of categorical data via self-distillation. Building on recent variational formulations of flow matching and the broader trend towards accelerated inference in diffusion and flow-based models, we define a flow map towards the simplex that transports probability mass toward a predicted endpoint, yielding a parametrisation that naturally constrains model predictions. Since our trajectories are continuous rather than discrete, Categorical Flow Maps can be trained with existing distillation techniques, as well as a new objective based on endpoint consistency. This continuous formulation also automatically unlocks test-time inference: we can directly reuse existing guidance and reweighting techniques in the categorical setting to steer sampling toward downstream objectives. Empirically, we achieve state-of-the-art few-step results on images, molecular graphs, and text, with strong performance even in single-step generation.
The Entropic Signature of Class Speciation in Diffusion Models
Feb 10, 2026Diffusion models do not recover semantic structure uniformly over time. Instead, samples transition from semantic ambiguity to class commitment within a narrow regime. Recent theoretical work attributes this transition to dynamical instabilities along class-separating directions, but practical methods to detect and exploit these windows in trained models are still limited. We show that tracking the class-conditional entropy of a latent semantic variable given the noisy state provides a reliable signature of these transition regimes. By restricting the entropy to semantic partitions, the entropy can furthermore resolve semantic decisions at different levels of abstraction. We analyze this behavior in high-dimensional Gaussian mixture models and show that the entropy rate concentrates on the same logarithmic time scale as the speciation symmetry-breaking instability previously identified in variance-preserving diffusion. We validate our method on EDM2-XS and Stable Diffusion 1.5, where class-conditional entropy consistently isolates the noise regimes critical for semantic structure formation. Finally, we use our framework to quantify how guidance redistributes semantic information over time. Together, these results connect information-theoretic and statistical physics perspectives on diffusion and provide a principled basis for time-localized control.
Improved Sampling Schedules for Discrete Diffusion Models
Feb 09, 2026Discrete diffusion models have emerged as a powerful paradigm for generative modeling on sequence data; however, the information-theoretic principles governing their reverse processes remain significantly less understood than those of their continuous counterparts. In this work, we bridge this gap by analyzing the reverse process dynamics through the lens of thermodynamic entropy production. We propose the entropy production rate as a rigorous proxy for quantifying information generation, deriving as a byproduct a bound on the Wasserstein distance between intermediate states and the data distribution. Leveraging these insights, we introduce two novel sampling schedules that are uniformly spaced with respect to their corresponding physics-inspired metrics: the Entropic Discrete Schedule (EDS), which is defined by maintaining a constant rate of information gain, and the Wasserstein Discrete Schedule (WDS), which is defined by taking equal steps in terms of the Wasserstein distance. We empirically demonstrate that our proposed schedules significantly outperform state-of-the-art strategies across diverse application domains, including synthetic data, music notation, vision and language modeling, consistently achieving superior performance at a lower computational budget.
Emergence of Distortions in High-Dimensional Guided Diffusion Models
Jan 31, 2026Classifier-free guidance (CFG) is the de facto standard for conditional sampling in diffusion models, yet it often leads to a loss of diversity in generated samples. We formalize this phenomenon as generative distortion, defined as the mismatch between the CFG-induced sampling distribution and the true conditional distribution. Considering Gaussian mixtures and their exact scores, and leveraging tools from statistical physics, we characterize the onset of distortion in a high-dimensional regime as a function of the number of classes. Our analysis reveals that distortions emerge through a phase transition in the effective potential governing the guided dynamics. In particular, our dynamical mean-field analysis shows that distortion persists when the number of modes grows exponentially with dimension, but vanishes in the sub-exponential regime. Consistent with prior finite-dimensional results, we further demonstrate that vanilla CFG shifts the mean and shrinks the variance of the conditional distribution. We show that standard CFG schedules are fundamentally incapable of preventing variance shrinkage. Finally, we propose a theoretically motivated guidance schedule featuring a negative-guidance window, which mitigates loss of diversity while preserving class separability.
The Information Dynamics of Generative Diffusion
Aug 27, 2025Generative diffusion models have emerged as a powerful class of models in machine learning, yet a unified theoretical understanding of their operation is still developing. This perspective paper provides an integrated perspective on generative diffusion by connecting their dynamic, information-theoretic, and thermodynamic properties under a unified mathematical framework. We demonstrate that the rate of conditional entropy production during generation (i.e. the generative bandwidth) is directly governed by the expected divergence of the score function's vector field. This divergence, in turn, is linked to the branching of trajectories and generative bifurcations, which we characterize as symmetry-breaking phase transitions in the energy landscape. This synthesis offers a powerful insight: the process of generation is fundamentally driven by the controlled, noise-induced breaking of (approximate) symmetries, where peaks in information transfer correspond to critical transitions between possible outcomes. The score function acts as a dynamic non-linear filter that regulates the bandwidth of the noise by suppressing fluctuations that are incompatible with the data.
Measuring Semantic Information Production in Generative Diffusion Models
Jun 12, 2025



It is well known that semantic and structural features of the generated images emerge at different times during the reverse dynamics of diffusion, a phenomenon that has been connected to physical phase transitions in magnets and other materials. In this paper, we introduce a general information-theoretic approach to measure when these class-semantic "decisions" are made during the generative process. By using an online formula for the optimal Bayesian classifier, we estimate the conditional entropy of the class label given the noisy state. We then determine the time intervals corresponding to the highest information transfer between noisy states and class labels using the time derivative of the conditional entropy. We demonstrate our method on one-dimensional Gaussian mixture models and on DDPM models trained on the CIFAR10 dataset. As expected, we find that the semantic information transfer is highest in the intermediate stages of diffusion while vanishing during the final stages. However, we found sizable differences between the entropy rate profiles of different classes, suggesting that different "semantic decisions" are located at different intermediate times.
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory
May 27, 2025



Hopfield networks are associative memory (AM) systems, designed for storing and retrieving patterns as local minima of an energy landscape. In the classical Hopfield model, an interesting phenomenon occurs when the amount of training data reaches its critical memory load $- spurious\,\,states$, or unintended stable points, emerge at the end of the retrieval dynamics, leading to incorrect recall. In this work, we examine diffusion models, commonly used in generative modeling, from the perspective of AMs. The training phase of diffusion model is conceptualized as memory encoding (training data is stored in the memory). The generation phase is viewed as an attempt of memory retrieval. In the small data regime the diffusion model exhibits a strong memorization phase, where the network creates distinct basins of attraction around each sample in the training set, akin to the Hopfield model below the critical memory load. In the large data regime, a different phase appears where an increase in the size of the training set fosters the creation of new attractor states that correspond to manifolds of the generated samples. Spurious states appear at the boundary of this transition and correspond to emergent attractor states, which are absent in the training set, but, at the same time, have distinct basins of attraction around them. Our findings provide: a novel perspective on the memorization-generalization phenomenon in diffusion models via the lens of AMs, theoretical prediction of existence of spurious states, empirical validation of this prediction in commonly-used diffusion models.
Entropic Time Schedulers for Generative Diffusion Models
Apr 18, 2025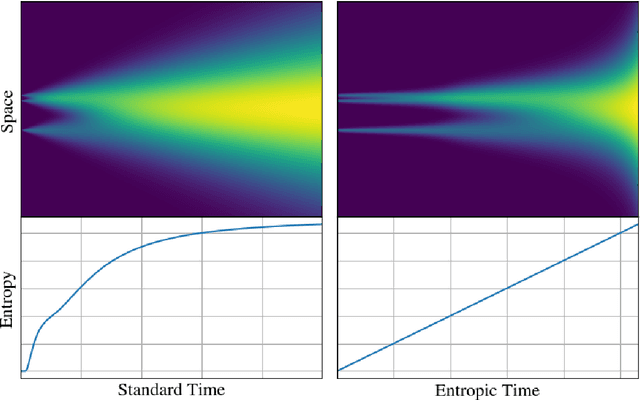



The practical performance of generative diffusion models depends on the appropriate choice of the noise scheduling function, which can also be equivalently expressed as a time reparameterization. In this paper, we present a time scheduler that selects sampling points based on entropy rather than uniform time spacing, ensuring that each point contributes an equal amount of information to the final generation. We prove that this time reparameterization does not depend on the initial choice of time. Furthermore, we provide a tractable exact formula to estimate this \emph{entropic time} for a trained model using the training loss without substantial overhead. Alongside the entropic time, inspired by the optimality results, we introduce a rescaled entropic time. In our experiments with mixtures of Gaussian distributions and ImageNet, we show that using the (rescaled) entropic times greatly improves the inference performance of trained models. In particular, we found that the image quality in pretrained EDM2 models, as evaluated by FID and FD-DINO scores, can be substantially increased by the rescaled entropic time reparameterization without increasing the number of function evaluations, with greater improvements in the few NFEs regime.
Training Consistency Models with Variational Noise Coupling
Feb 25, 2025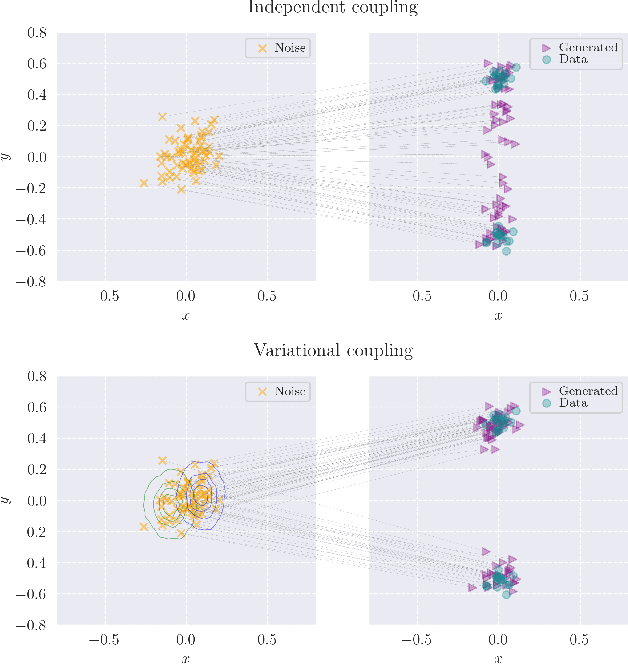


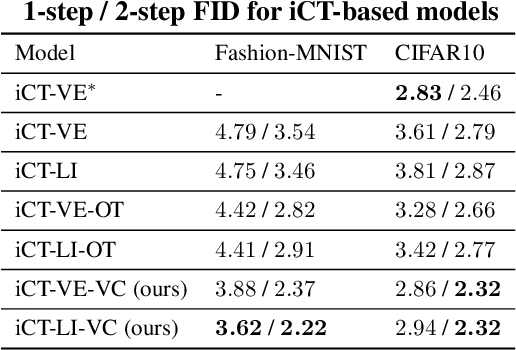
Consistency Training (CT) has recently emerged as a promising alternative to diffusion models, achieving competitive performance in image generation tasks. However, non-distillation consistency training often suffers from high variance and instability, and analyzing and improving its training dynamics is an active area of research. In this work, we propose a novel CT training approach based on the Flow Matching framework. Our main contribution is a trained noise-coupling scheme inspired by the architecture of Variational Autoencoders (VAE). By training a data-dependent noise emission model implemented as an encoder architecture, our method can indirectly learn the geometry of the noise-to-data mapping, which is instead fixed by the choice of the forward process in classical CT. Empirical results across diverse image datasets show significant generative improvements, with our model outperforming baselines and achieving the state-of-the-art (SoTA) non-distillation CT FID on CIFAR-10, and attaining FID on par with SoTA on ImageNet at $64 \times 64$ resolution in 2-step generation. Our code is available at https://github.com/sony/vct .