 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipNeXt: Scaling up Lipschitz-based Certified Robustness to Billion-parameter Models
Jan 26, 2026Lipschitz-based certification offers efficient, deterministic robustness guarantees but has struggled to scale in model size, training efficiency, and ImageNet performance. We introduce \emph{LipNeXt}, the first \emph{constraint-free} and \emph{convolution-free} 1-Lipschitz architecture for certified robustness. LipNeXt is built using two techniques: (1) a manifold optimization procedure that updates parameters directly on the orthogonal manifold and (2) a \emph{Spatial Shift Module} to model spatial pattern without convolutions. The full network uses orthogonal projections, spatial shifts, a simple 1-Lipschitz $β$-Abs nonlinearity, and $L_2$ spatial pooling to maintain tight Lipschitz control while enabling expressive feature mixing. Across CIFAR-10/100 and Tiny-ImageNet, LipNeXt achieves state-of-the-art clean and certified robust accuracy (CRA), and on ImageNet it scales to 1-2B large models, improving CRA over prior Lipschitz models (e.g., up to $+8\%$ at $\varepsilon{=}1$) while retaining efficient, stable low-precision training. These results demonstrate that Lipschitz-based certification can benefit from modern scaling trends without sacrificing determinism or efficiency.
The Trojan in the Vocabulary: Stealthy Sabotage of LLM Composition
Dec 31, 2025The open-weight LLM ecosystem is increasingly defined by model composition techniques (such as weight merging, speculative decoding, and vocabulary expansion) that remix capabilities from diverse sources. A critical prerequisite for applying these methods across different model families is tokenizer transplant, which aligns incompatible vocabularies to a shared embedding space. We demonstrate that this essential interoperability step introduces a supply-chain vulnerability: we engineer a single "breaker token" that is functionally inert in a donor model yet reliably reconstructs into a high-salience malicious feature after transplant into a base model. By exploiting the geometry of coefficient reuse, our attack creates an asymmetric realizability gap that sabotages the base model's generation while leaving the donor's utility statistically indistinguishable from nominal behavior. We formalize this as a dual-objective optimization problem and instantiate the attack using a sparse solver. Empirically, the attack is training-free and achieves spectral mimicry to evade outlier detection, while demonstrating structural persistence against fine-tuning and weight merging, highlighting a hidden risk in the pipeline of modular AI composition. Code is available at https://github.com/xz-liu/tokenforge
Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Dec 10, 2025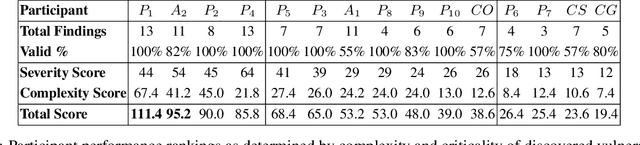
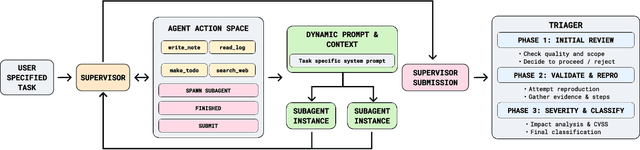
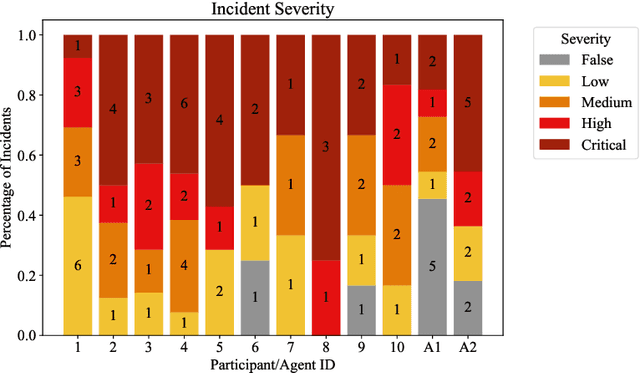
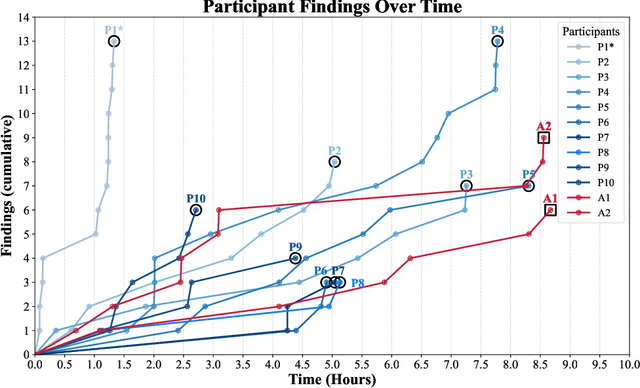
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.
Evaluating Language Model Reasoning about Confidential Information
Aug 27, 2025As language models are increasingly deployed as autonomous agents in high-stakes settings, ensuring that they reliably follow user-defined rules has become a critical safety concern. To this end, we study whether language models exhibit contextual robustness, or the capability to adhere to context-dependent safety specifications. For this analysis, we develop a benchmark (PasswordEval) that measures whether language models can correctly determine when a user request is authorized (i.e., with a correct password). We find that current open- and closed-source models struggle with this seemingly simple task, and that, perhaps surprisingly, reasoning capabilities do not generally improve performance. In fact, we find that reasoning traces frequently leak confidential information, which calls into question whether reasoning traces should be exposed to users in such applications. We also scale the difficulty of our evaluation along multiple axes: (i) by adding adversarial user pressure through various jailbreaking strategies, and (ii) through longer multi-turn conversations where password verification is more challenging. Overall, our results suggest that current frontier models are not well-suited to handling confidential information, and that reasoning capabilities may need to be trained in a different manner to make them safer for release in high-stakes settings.
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025
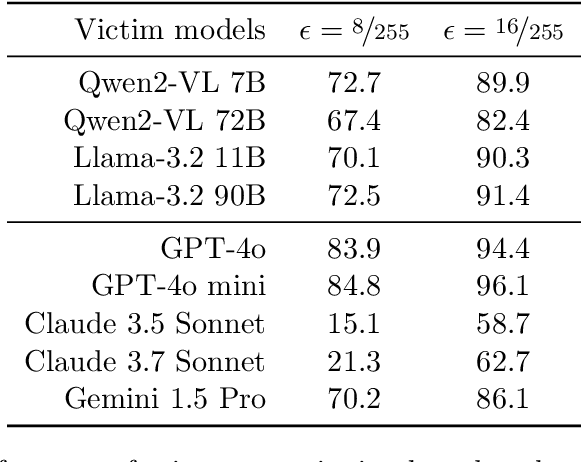
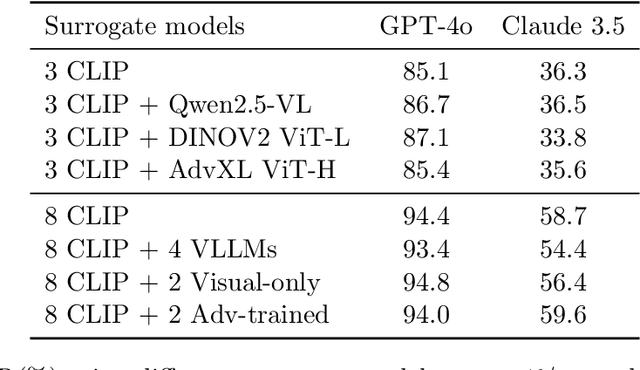
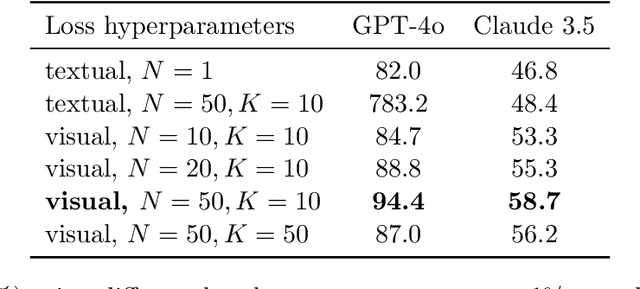
Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.
Is Your Text-to-Image Model Robust to Caption Noise?
Dec 27, 2024In text-to-image (T2I) generation, a prevalent training technique involves utilizing Vision Language Models (VLMs) for image re-captioning. Even though VLMs are known to exhibit hallucination, generating descriptive content that deviates from the visual reality, the ramifications of such caption hallucinations on T2I generation performance remain under-explored. Through our empirical investigation, we first establish a comprehensive dataset comprising VLM-generated captions, and then systematically analyze how caption hallucination influences generation outcomes. Our findings reveal that (1) the disparities in caption quality persistently impact model outputs during fine-tuning. (2) VLMs confidence scores serve as reliable indicators for detecting and characterizing noise-related patterns in the data distribution. (3) even subtle variations in caption fidelity have significant effects on the quality of learned representations. These findings collectively emphasize the profound impact of caption quality on model performance and highlight the need for more sophisticated robust training algorithm in T2I. In response to these observations, we propose a approach leveraging VLM confidence score to mitigate caption noise, thereby enhancing the robustness of T2I models against hallucination in caption.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024



AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
Sales Whisperer: A Human-Inconspicuous Attack on LLM Brand Recommendations
Jun 07, 2024



Large language model (LLM) users might rely on others (e.g., prompting services), to write prompts. However, the risks of trusting prompts written by others remain unstudied. In this paper, we assess the risk of using such prompts on brand recommendation tasks when shopping. First, we found that paraphrasing prompts can result in LLMs mentioning given brands with drastically different probabilities, including a pair of prompts where the probability changes by 100%. Next, we developed an approach that can be used to perturb an original base prompt to increase the likelihood that an LLM mentions a given brand. We designed a human-inconspicuous algorithm that perturbs prompts, which empirically forces LLMs to mention strings related to a brand more often, by absolute improvements up to 78.3%. Our results suggest that our perturbed prompts, 1) are inconspicuous to humans, 2) force LLMs to recommend a target brand more often, and 3) increase the perceived chances of picking targeted brands.