 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable and Adaptable Driving Behavior Prediction
Feb 13, 2022
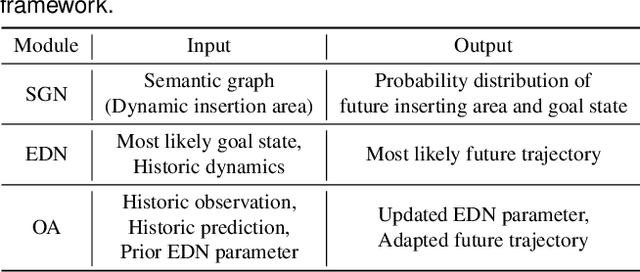
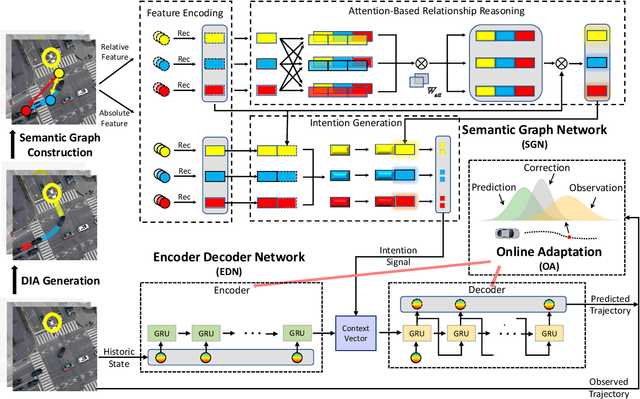

While autonomous vehicles still struggle to solve challenging situations during on-road driving, humans have long mastered the essence of driving with efficient, transferable, and adaptable driving capability. By mimicking humans' cognition model and semantic understanding during driving, we propose HATN, a hierarchical framework to generate high-quality, transferable, and adaptable predictions for driving behaviors in multi-agent dense-traffic environments. Our hierarchical method consists of a high-level intention identification policy and a low-level trajectory generation policy. We introduce a novel semantic sub-task definition and generic state representation for each sub-task. With these techniques, the hierarchical framework is transferable across different driving scenarios. Besides, our model is able to capture variations of driving behaviors among individuals and scenarios by an online adaptation module. We demonstrate our algorithms in the task of trajectory prediction for real traffic data at intersections and roundabouts from the INTERACTION dataset. Through extensive numerical studies, it is evident that our method significantly outperformed other methods in terms of prediction accuracy, transferability, and adaptability. Pushing the state-of-the-art performance by a considerable margin, we also provide a cognitive view of understanding the driving behavior behind such improvement. We highlight that in the future, more research attention and effort are deserved for transferability and adaptability. It is not only due to the promising performance elevation of prediction and planning algorithms, but more fundamentally, they are crucial for the scalable and general deployment of autonomous vehicles.
Learning Differentiable Safety-Critical Control using Control Barrier Functions for Generalization to Novel Environments
Jan 07, 2022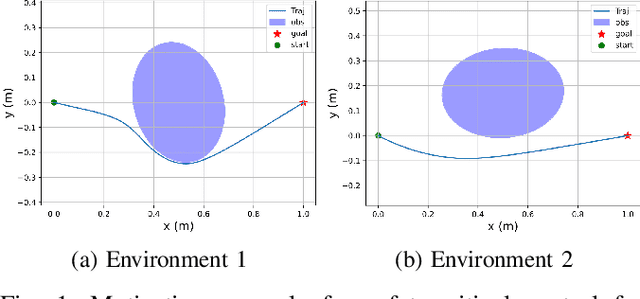
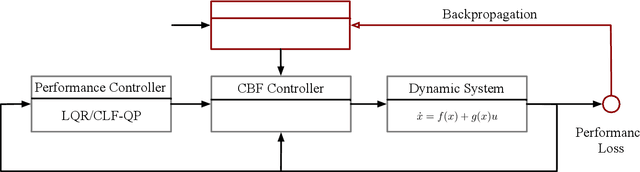
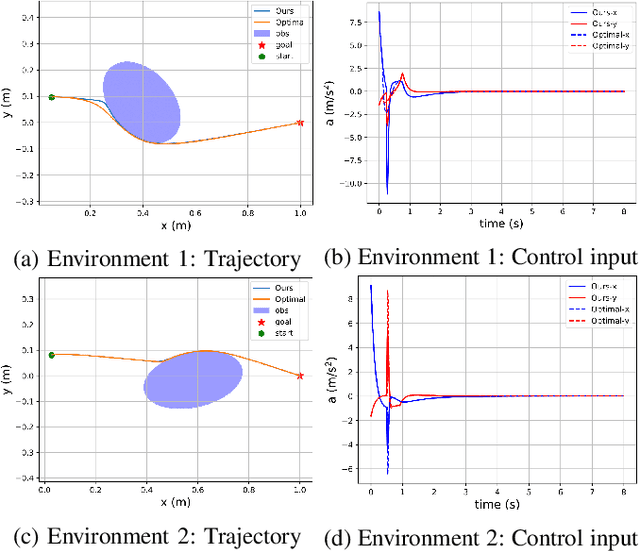
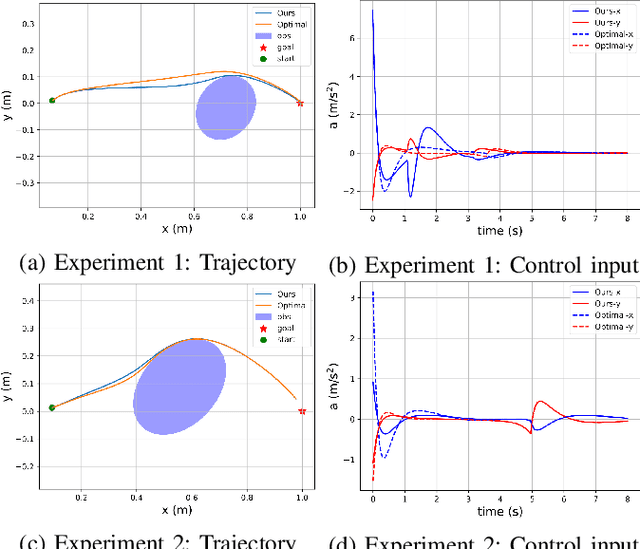
Control barrier functions (CBFs) have become a popular tool to enforce safety of a control system. CBFs are commonly utilized in a quadratic program formulation (CBF-QP) as safety-critical constraints. A class $\mathcal{K}$ function in CBFs usually needs to be tuned manually in order to balance the trade-off between performance and safety for each environment. However, this process is often heuristic and can become intractable for high relative-degree systems. Moreover, it prevents the CBF-QP from generalizing to different environments in the real world. By embedding the optimization procedure of the CBF-QP as a differentiable layer within a deep learning architecture, we propose a differentiable optimization-based safety-critical control framework that enables generalization to new environments with forward invariance guarantees. Finally, we validate the proposed control design with 2D double and quadruple integrator systems in various environments.
Towards General and Efficient Active Learning
Dec 15, 2021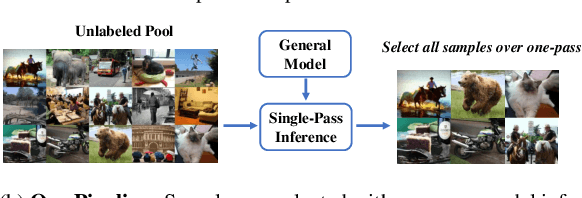
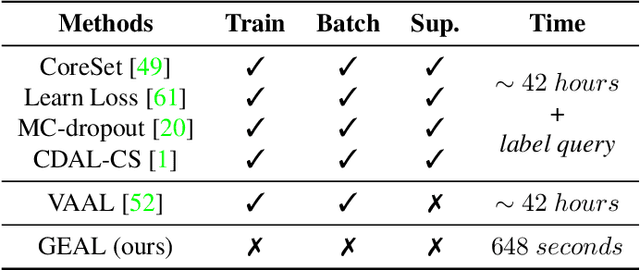
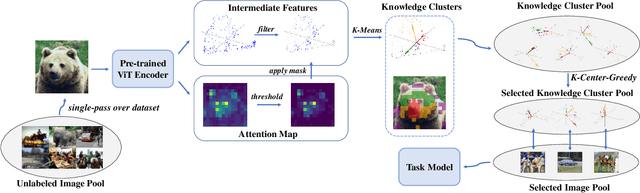
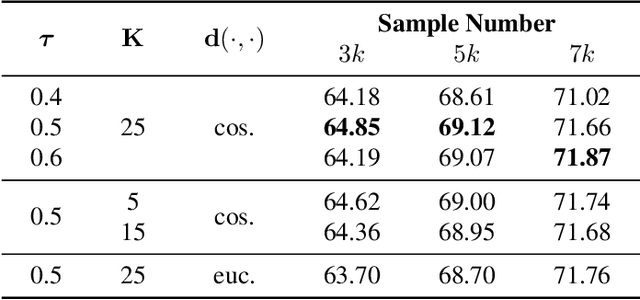
Active learning aims to select the most informative samples to exploit limited annotation budgets. Most existing work follows a cumbersome pipeline by repeating the time-consuming model training and batch data selection multiple times on each dataset separately. We challenge this status quo by proposing a novel general and efficient active learning (GEAL) method in this paper. Utilizing a publicly available model pre-trained on a large dataset, our method can conduct data selection processes on different datasets with a single-pass inference of the same model. To capture the subtle local information inside images, we propose knowledge clusters that are easily extracted from the intermediate features of the pre-trained network. Instead of the troublesome batch selection strategy, all data samples are selected in one go by performing K-Center-Greedy in the fine-grained knowledge cluster level. The entire procedure only requires single-pass model inference without training or supervision, making our method notably superior to prior arts in terms of time complexity by up to hundreds of times. Extensive experiments widely demonstrate the promising performance of our method on object detection, semantic segmentation, depth estimation, and image classification.
Causal-based Time Series Domain Generalization for Vehicle Intention Prediction
Dec 03, 2021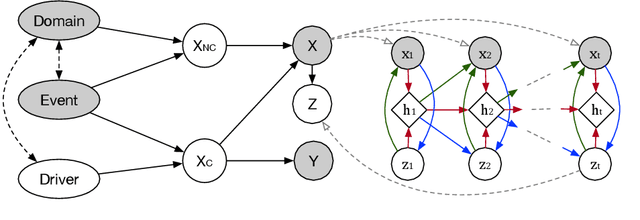



Accurately predicting possible behaviors of traffic participants is an essential capability for autonomous vehicles. Since autonomous vehicles need to navigate in dynamically changing environments, they are expected to make accurate predictions regardless of where they are and what driving circumstances they encountered. Therefore, generalization capability to unseen domains is crucial for prediction models when autonomous vehicles are deployed in the real world. In this paper, we aim to address the domain generalization problem for vehicle intention prediction tasks and a causal-based time series domain generalization (CTSDG) model is proposed. We construct a structural causal model for vehicle intention prediction tasks to learn an invariant representation of input driving data for domain generalization. We further integrate a recurrent latent variable model into our structural causal model to better capture temporal latent dependencies from time-series input data. The effectiveness of our approach is evaluated via real-world driving data. We demonstrate that our proposed method has consistent improvement on prediction accuracy compared to other state-of-the-art domain generalization and behavior prediction methods.
Exploring Social Posterior Collapse in Variational Autoencoder for Interaction Modeling
Dec 01, 2021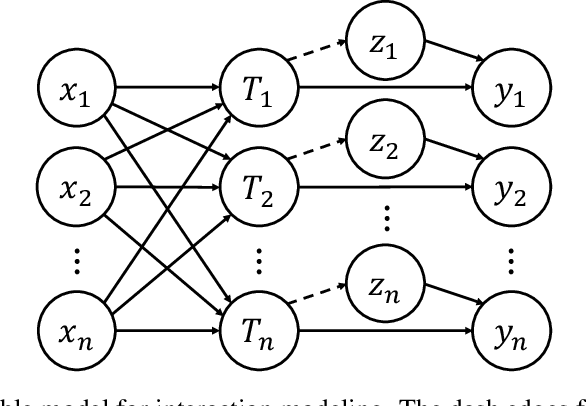
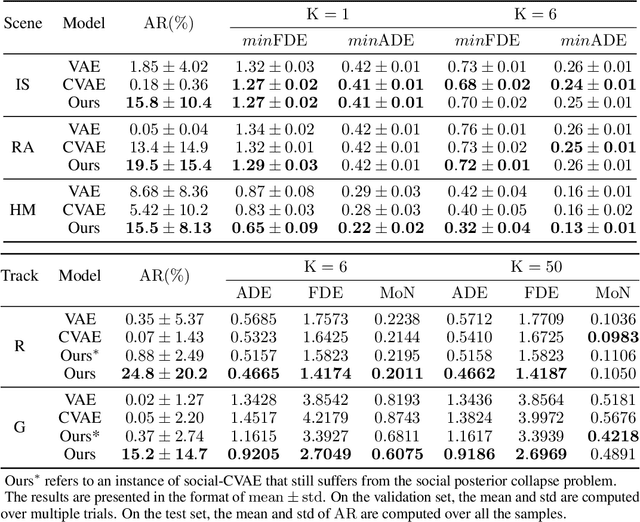
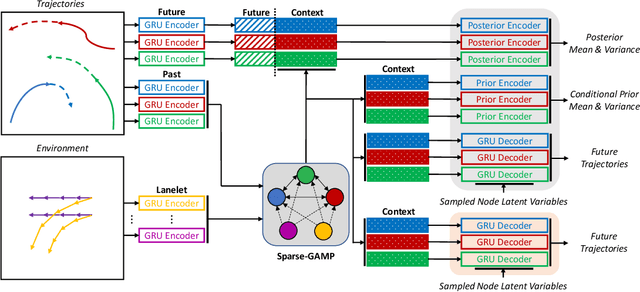
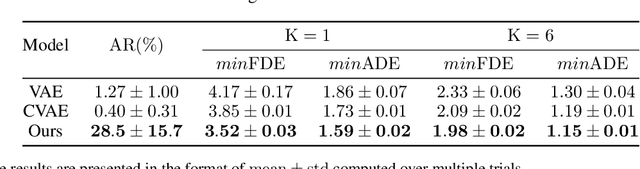
Multi-agent behavior modeling and trajectory forecasting are crucial for the safe navigation of autonomous agents in interactive scenarios. Variational Autoencoder (VAE) has been widely applied in multi-agent interaction modeling to generate diverse behavior and learn a low-dimensional representation for interacting systems. However, existing literature did not formally discuss if a VAE-based model can properly encode interaction into its latent space. In this work, we argue that one of the typical formulations of VAEs in multi-agent modeling suffers from an issue we refer to as social posterior collapse, i.e., the model is prone to ignoring historical social context when predicting the future trajectory of an agent. It could cause significant prediction errors and poor generalization performance. We analyze the reason behind this under-explored phenomenon and propose several measures to tackle it. Afterward, we implement the proposed framework and experiment on real-world datasets for multi-agent trajectory prediction. In particular, we propose a novel sparse graph attention message-passing (sparse-GAMP) layer, which helps us detect social posterior collapse in our experiments. In the experiments, we verify that social posterior collapse indeed occurs. Also, the proposed measures are effective in alleviating the issue. As a result, the model attains better generalization performance when historical social context is informative for prediction.
Dealing with the Unknown: Pessimistic Offline Reinforcement Learning
Nov 09, 2021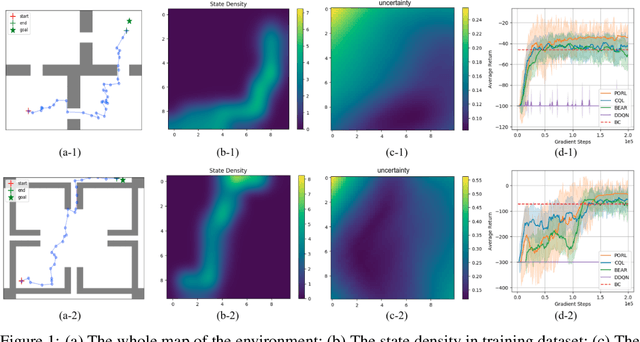
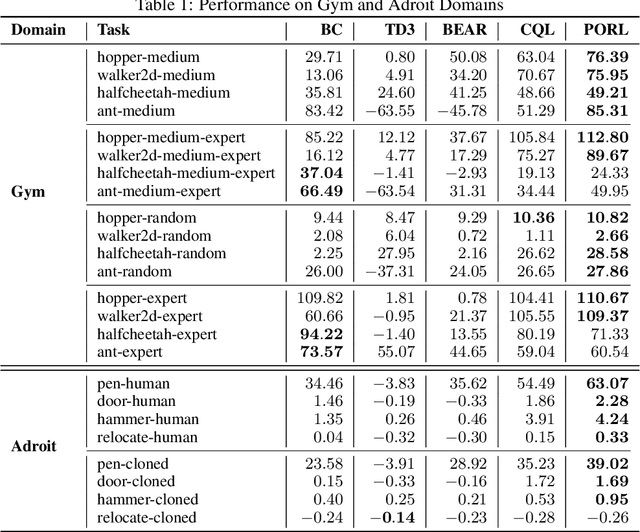
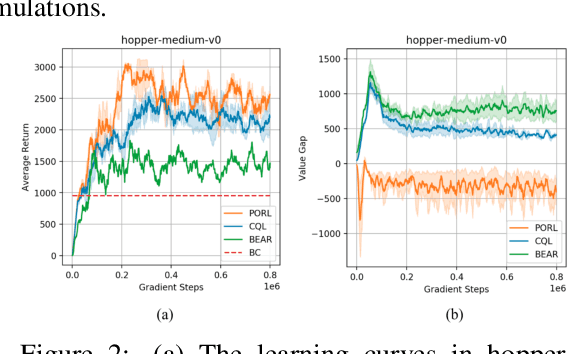
Reinforcement Learning (RL) has been shown effective in domains where the agent can learn policies by actively interacting with its operating environment. However, if we change the RL scheme to offline setting where the agent can only update its policy via static datasets, one of the major issues in offline reinforcement learning emerges, i.e. distributional shift. We propose a Pessimistic Offline Reinforcement Learning (PessORL) algorithm to actively lead the agent back to the area where it is familiar by manipulating the value function. We focus on problems caused by out-of-distribution (OOD) states, and deliberately penalize high values at states that are absent in the training dataset, so that the learned pessimistic value function lower bounds the true value anywhere within the state space. We evaluate the PessORL algorithm on various benchmark tasks, where we show that our method gains better performance by explicitly handling OOD states, when compared to those methods merely considering OOD actions.
Trajectory Splitting: A Distributed Formulation for Collision Avoiding Trajectory Optimization
Nov 02, 2021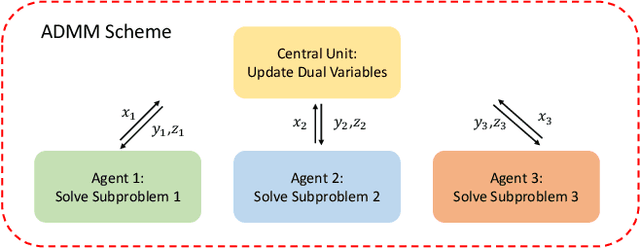
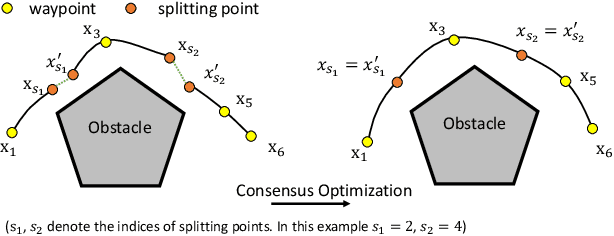
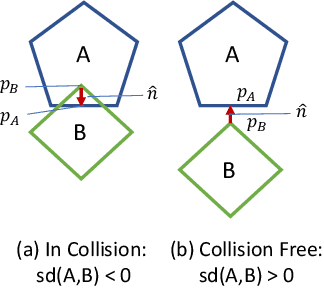
Efficient trajectory optimization is essential for avoiding collisions in unstructured environments, but it remains challenging to have both speed and quality in the solutions. One reason is that second-order optimality requires calculating Hessian matrices that can grow with $O(N^2)$ with the number of waypoints. Decreasing the waypoints can quadratically decrease computation time. Unfortunately, fewer waypoints result in lower quality trajectories that may not avoid the collision. To have both, dense waypoints and reduced computation time, we took inspiration from recent studies on consensus optimization and propose a distributed formulation of collocated trajectory optimization. It breaks a long trajectory into several segments, where each segment becomes a subproblem of a few waypoints. These subproblems are solved classically, but in parallel, and the solutions are fused into a single trajectory with a consensus constraint that enforces continuity of the segments through a consensus update. With this scheme, the quadratic complexity is distributed to each segment and enables solving for higher-quality trajectories with denser waypoints. Furthermore, the proposed formulation is amenable to using any existing trajectory optimizer for solving the subproblems. We compare the performance of our implementation of trajectory splitting against leading motion planning algorithms and demonstrate the improved computational efficiency of our method.
Safe Online Gain Optimization for Variable Impedance Control
Nov 01, 2021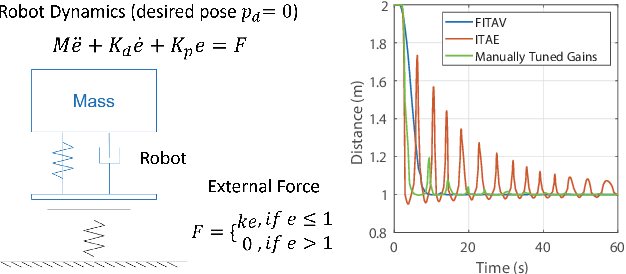
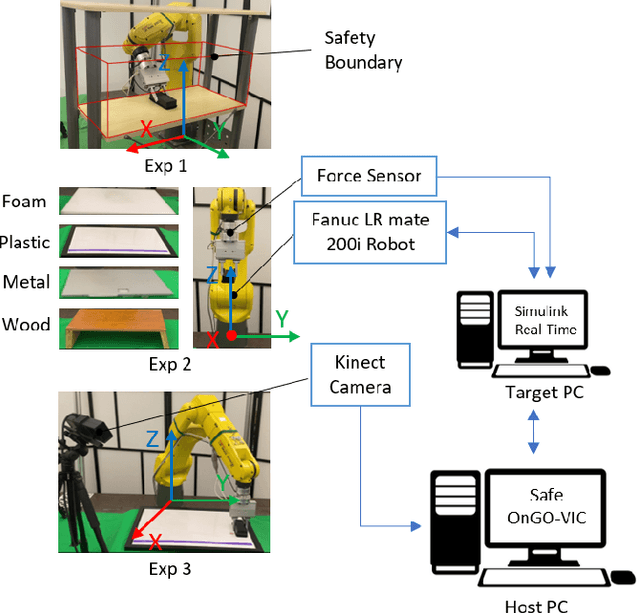
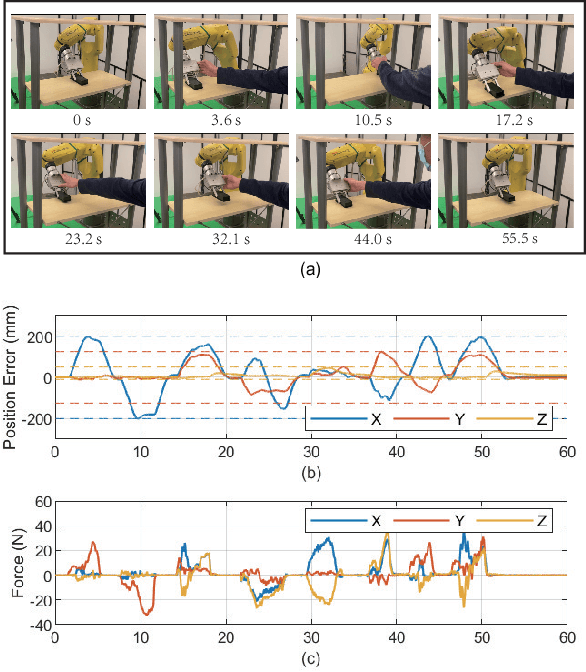
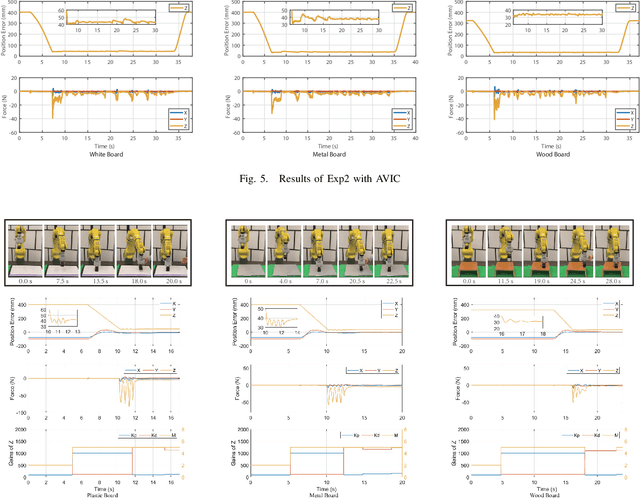
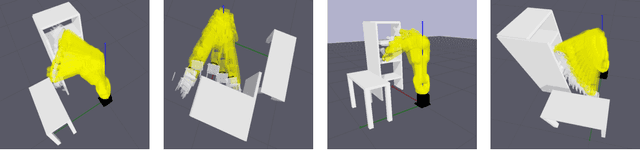
Smooth behaviors are preferable for many contact-rich manipulation tasks. Impedance control arises as an effective way to regulate robot movements by mimicking a mass-spring-damping system. Consequently, the robot behavior can be determined by the impedance gains. However, tuning the impedance gains for different tasks is tricky, especially for unstructured environments. Moreover, online adapting the optimal gains to meet the time-varying performance index is even more challenging. In this paper, we present Safe Online Gain Optimization for Variable Impedance Control (Safe OnGO-VIC). By reformulating the dynamics of impedance control as a control-affine system, in which the impedance gains are the inputs, we provide a novel perspective to understand variable impedance control. Additionally, we innovatively formulate an optimization problem with online collected force information to obtain the optimal impedance gains in real-time. Safety constraints are also embedded in the proposed framework to avoid unwanted collisions. We experimentally validated the proposed algorithm on three manipulation tasks. Comparison results with a constant gain baseline and an adaptive control method prove that the proposed algorithm is effective and generalizable to different scenarios.
Hierarchical Adaptable and Transferable Networks (HATN) for Driving Behavior Prediction
Nov 01, 2021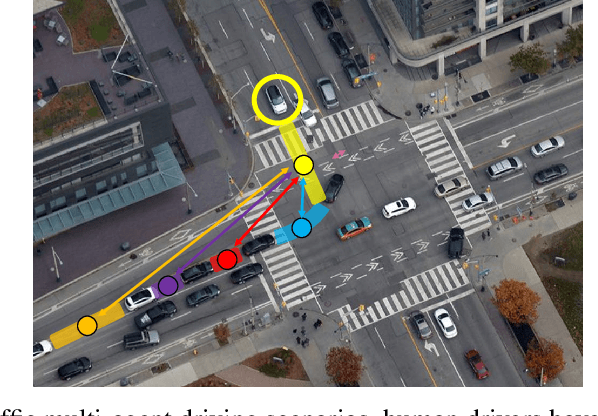
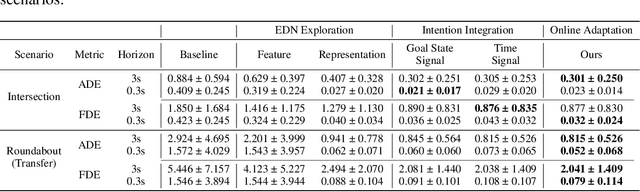
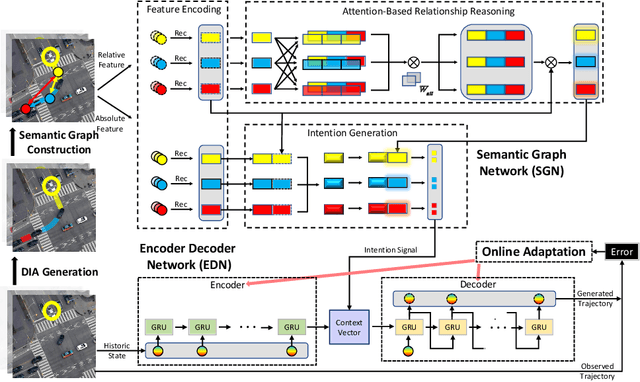
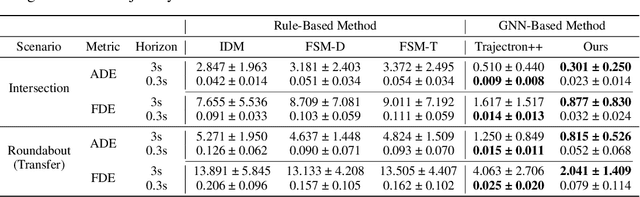
When autonomous vehicles still struggle to solve challenging situations during on-road driving, humans have long mastered the essence of driving with efficient transferable and adaptable driving capability. By mimicking humans' cognition model and semantic understanding during driving, we present HATN, a hierarchical framework to generate high-quality driving behaviors in multi-agent dense-traffic environments. Our method hierarchically consists of a high-level intention identification and low-level action generation policy. With the semantic sub-task definition and generic state representation, the hierarchical framework is transferable across different driving scenarios. Besides, our model is also able to capture variations of driving behaviors among individuals and scenarios by an online adaptation module. We demonstrate our algorithms in the task of trajectory prediction for real traffic data at intersections and roundabouts, where we conducted extensive studies of the proposed method and demonstrated how our method outperformed other methods in terms of prediction accuracy and transferability.
Learning Insertion Primitives with Discrete-Continuous Hybrid Action Space for Robotic Assembly Tasks
Oct 25, 2021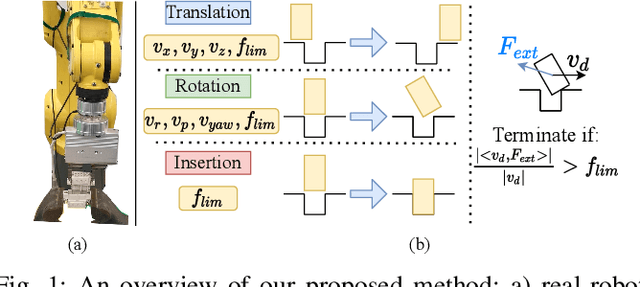
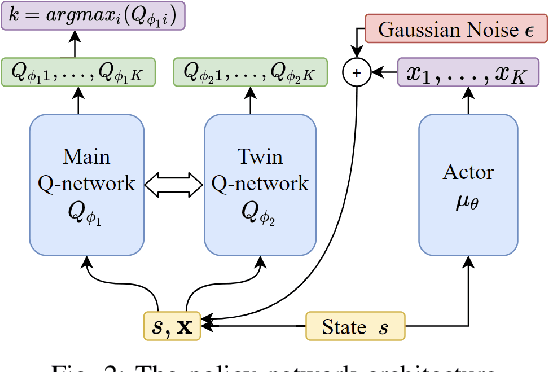

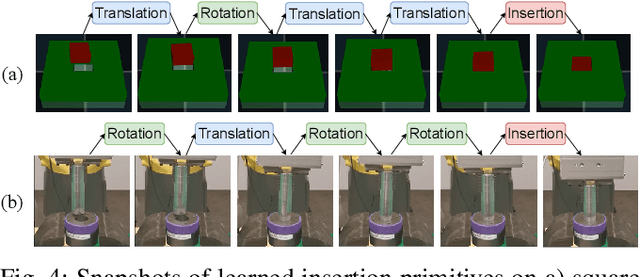
This paper introduces a discrete-continuous action space to learn insertion primitives for robotic assembly tasks. Primitive is a sequence of elementary actions with certain exit conditions, such as "pushing down the peg until contact". Since the primitive is an abstraction of robot control commands and encodes human prior knowledge, it reduces the exploration difficulty and yields better learning efficiency. In this paper, we learn robot assembly skills via primitives. Specifically, we formulate insertion primitives as parameterized actions: hybrid actions consisting of discrete primitive types and continuous primitive parameters. Compared with the previous work using a set of discretized parameters for each primitive, the agent in our method can freely choose primitive parameters from a continuous space, which is more flexible and efficient. To learn these insertion primitives, we propose Twin-Smoothed Multi-pass Deep Q-Network (TS-MP-DQN), an advanced version of MP-DQN with twin Q-network to reduce the Q-value over-estimation. Extensive experiments are conducted in the simulation and real world for validation. From experiment results, our approach achieves higher success rates than three baselines: MP-DQN with parameterized actions, primitives with discrete parameters, and continuous velocity control. Furthermore, learned primitives are robust to sim-to-real transfer and can generalize to challenging assembly tasks such as tight round peg-hole and complex shaped electric connectors with promising success rates. Experiment videos are available at https://msc.berkeley.edu/research/insertion-primitives.html.