 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Class Classification from Single-Class Data with Confidences
Jun 16, 2021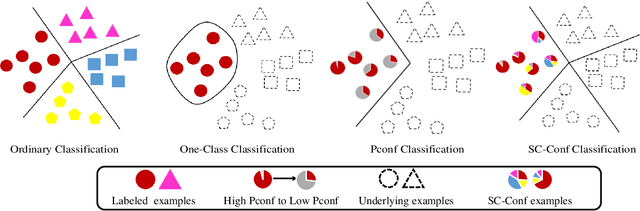
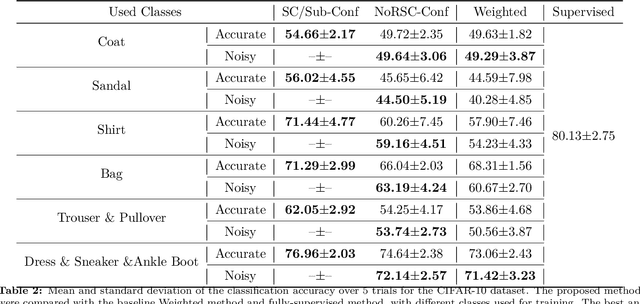
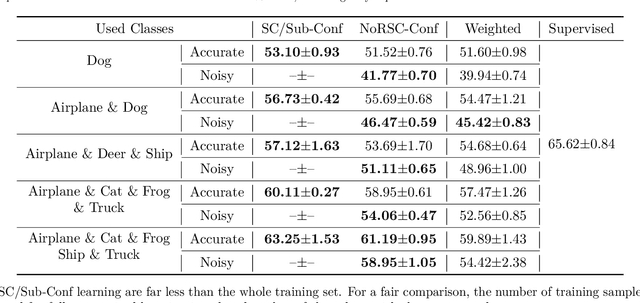
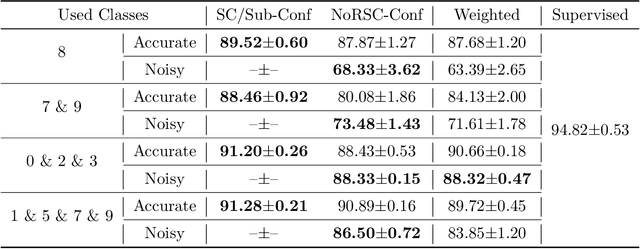
Can we learn a multi-class classifier from only data of a single class? We show that without any assumptions on the loss functions, models, and optimizers, we can successfully learn a multi-class classifier from only data of a single class with a rigorous consistency guarantee when confidences (i.e., the class-posterior probabilities for all the classes) are available. Specifically, we propose an empirical risk minimization framework that is loss-/model-/optimizer-independent. Instead of constructing a boundary between the given class and other classes, our method can conduct discriminative classification between all the classes even if no data from the other classes are provided. We further theoretically and experimentally show that our method can be Bayes-consistent with a simple modification even if the provided confidences are highly noisy. Then, we provide an extension of our method for the case where data from a subset of all the classes are available. Experimental results demonstrate the effectiveness of our methods.
Probabilistic Margins for Instance Reweighting in Adversarial Training
Jun 15, 2021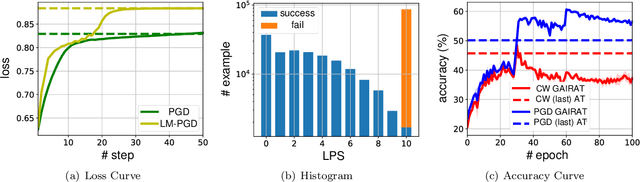
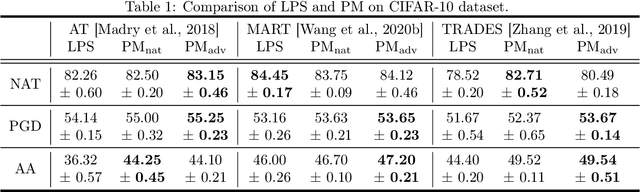
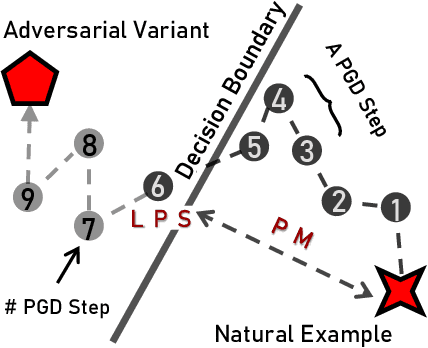
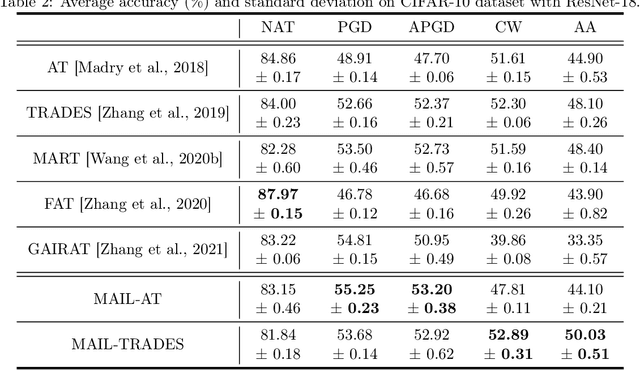
Reweighting adversarial data during training has been recently shown to improve adversarial robustness, where data closer to the current decision boundaries are regarded as more critical and given larger weights. However, existing methods measuring the closeness are not very reliable: they are discrete and can take only a few values, and they are path-dependent, i.e., they may change given the same start and end points with different attack paths. In this paper, we propose three types of probabilistic margin (PM), which are continuous and path-independent, for measuring the aforementioned closeness and reweighting adversarial data. Specifically, a PM is defined as the difference between two estimated class-posterior probabilities, e.g., such the probability of the true label minus the probability of the most confusing label given some natural data. Though different PMs capture different geometric properties, all three PMs share a negative correlation with the vulnerability of data: data with larger/smaller PMs are safer/riskier and should have smaller/larger weights. Experiments demonstrate that PMs are reliable measurements and PM-based reweighting methods outperform state-of-the-art methods.
On the Robustness of Average Losses for Partial-Label Learning
Jun 11, 2021
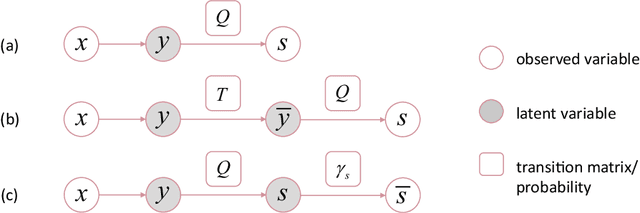
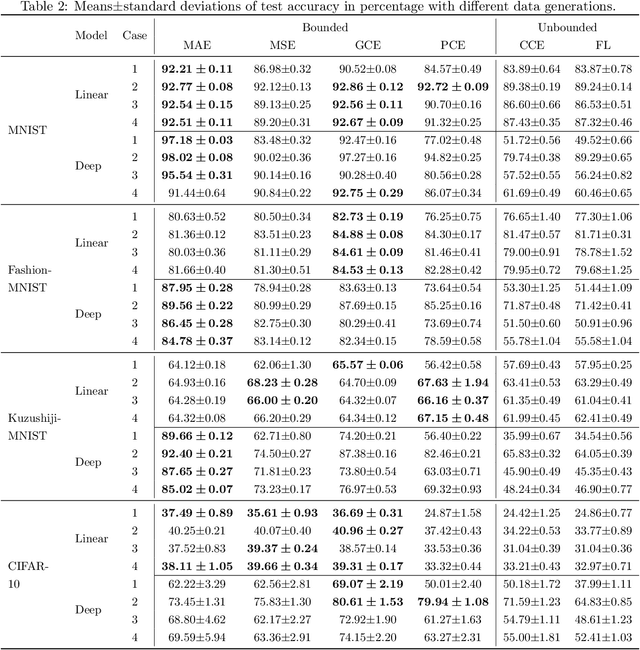
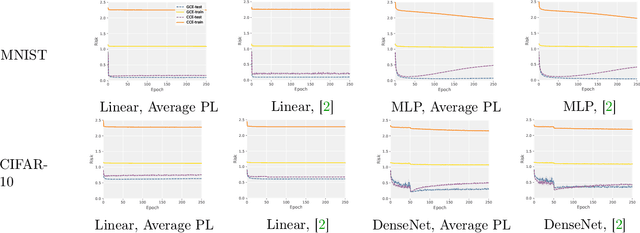
Partial-label (PL) learning is a typical weakly supervised classification problem, where a PL of an instance is a set of candidate labels such that a fixed but unknown candidate is the true label. For PL learning, there are two lines of research: (a) the identification-based strategy (IBS) purifies each label set and extracts the true label; (b) the average-based strategy (ABS) treats all candidates equally for training. In the past two decades, IBS was a much hotter topic than ABS, since it was believed that IBS is more promising. In this paper, we theoretically analyze ABS and find it also promising in the sense of the robustness of its loss functions. Specifically, we consider five problem settings for the generation of clean or noisy PLs, and we prove that average PL losses with bounded multi-class losses are always robust under mild assumptions on the domination of true labels, while average PL losses with unbounded multi-class losses (e.g., the cross-entropy loss) may not be robust. We also conduct experiments to validate our theoretical findings. Note that IBS is heuristic, and we cannot prove its robustness by a similar proof technique; hence, ABS is more advantageous from a theoretical point of view, and it is worth paying attention to the design of more advanced PL learning methods following ABS.
Loss function based second-order Jensen inequality and its application to particle variational inference
Jun 10, 2021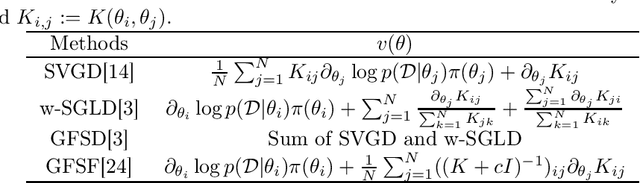
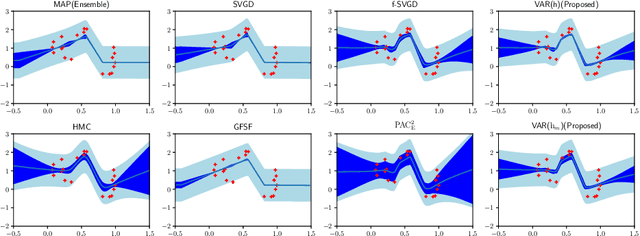
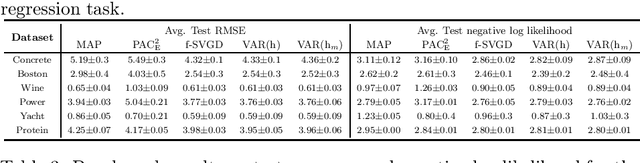
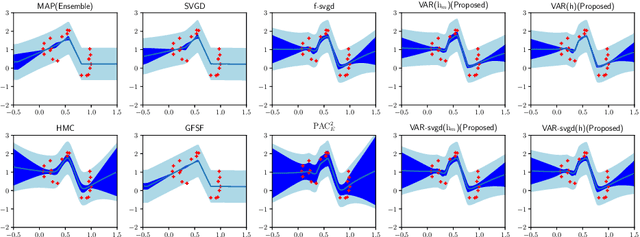
Bayesian model averaging, obtained as the expectation of a likelihood function by a posterior distribution, has been widely used for prediction, evaluation of uncertainty, and model selection. Various approaches have been developed to efficiently capture the information in the posterior distribution; one such approach is the optimization of a set of models simultaneously with interaction to ensure the diversity of the individual models in the same way as ensemble learning. A representative approach is particle variational inference (PVI), which uses an ensemble of models as an empirical approximation for the posterior distribution. PVI iteratively updates each model with a repulsion force to ensure the diversity of the optimized models. However, despite its promising performance, a theoretical understanding of this repulsion and its association with the generalization ability remains unclear. In this paper, we tackle this problem in light of PAC-Bayesian analysis. First, we provide a new second-order Jensen inequality, which has the repulsion term based on the loss function. Thanks to the repulsion term, it is tighter than the standard Jensen inequality. Then, we derive a novel generalization error bound and show that it can be reduced by enhancing the diversity of models. Finally, we derive a new PVI that optimizes the generalization error bound directly. Numerical experiments demonstrate that the performance of the proposed PVI compares favorably with existing methods in the experiment.
Instance Correction for Learning with Open-set Noisy Labels
Jun 01, 2021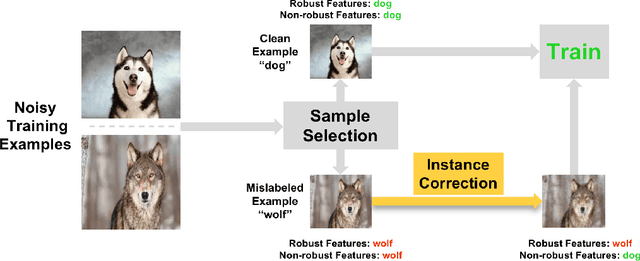
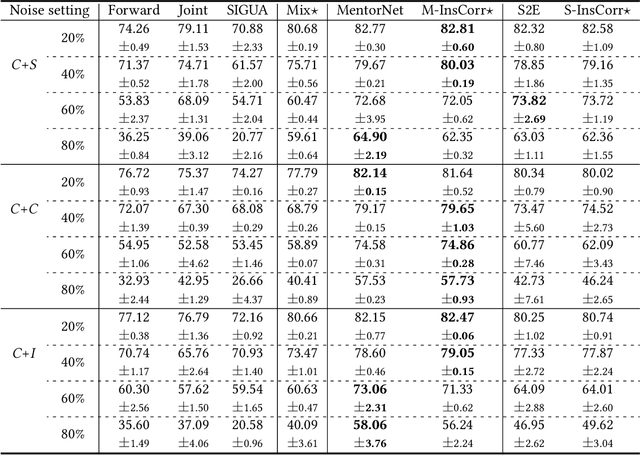

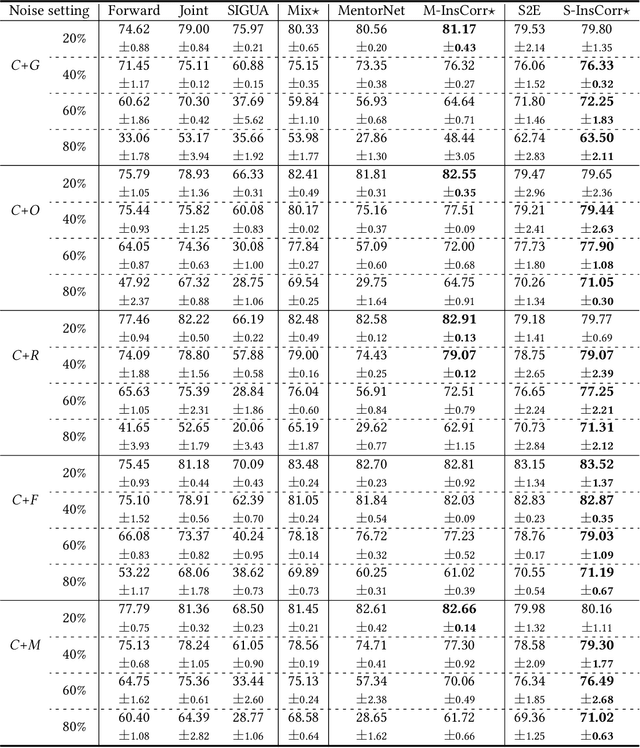
The problem of open-set noisy labels denotes that part of training data have a different label space that does not contain the true class. Lots of approaches, e.g., loss correction and label correction, cannot handle such open-set noisy labels well, since they need training data and test data to share the same label space, which does not hold for learning with open-set noisy labels. The state-of-the-art methods thus employ the sample selection approach to handle open-set noisy labels, which tries to select clean data from noisy data for network parameters updates. The discarded data are seen to be mislabeled and do not participate in training. Such an approach is intuitive and reasonable at first glance. However, a natural question could be raised "can such data only be discarded during training?". In this paper, we show that the answer is no. Specifically, we discuss that the instances of discarded data could consist of some meaningful information for generalization. For this reason, we do not abandon such data, but use instance correction to modify the instances of the discarded data, which makes the predictions for the discarded data consistent with given labels. Instance correction are performed by targeted adversarial attacks. The corrected data are then exploited for training to help generalization. In addition to the analytical results, a series of empirical evidences are provided to justify our claims.
Sample Selection with Uncertainty of Losses for Learning with Noisy Labels
Jun 01, 2021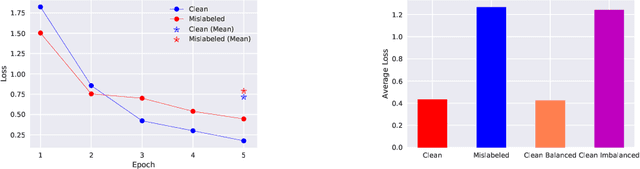
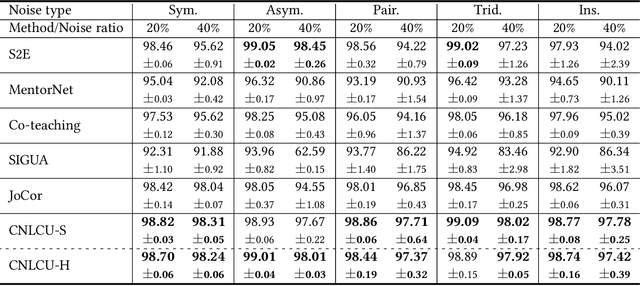
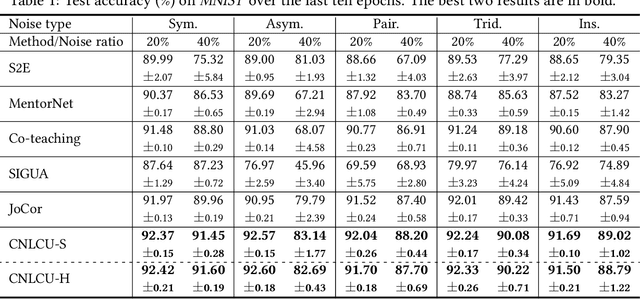
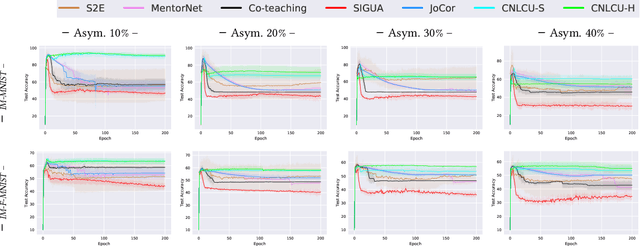
In learning with noisy labels, the sample selection approach is very popular, which regards small-loss data as correctly labeled during training. However, losses are generated on-the-fly based on the model being trained with noisy labels, and thus large-loss data are likely but not certainly to be incorrect. There are actually two possibilities of a large-loss data point: (a) it is mislabeled, and then its loss decreases slower than other data, since deep neural networks "learn patterns first"; (b) it belongs to an underrepresented group of data and has not been selected yet. In this paper, we incorporate the uncertainty of losses by adopting interval estimation instead of point estimation of losses, where lower bounds of the confidence intervals of losses derived from distribution-free concentration inequalities, but not losses themselves, are used for sample selection. In this way, we also give large-loss but less selected data a try; then, we can better distinguish between the cases (a) and (b) by seeing if the losses effectively decrease with the uncertainty after the try. As a result, we can better explore underrepresented data that are correctly labeled but seem to be mislabeled at first glance. Experiments demonstrate that the proposed method is superior to baselines and robust to a broad range of label noise types.
A unified view of likelihood ratio and reparameterization gradients
May 31, 2021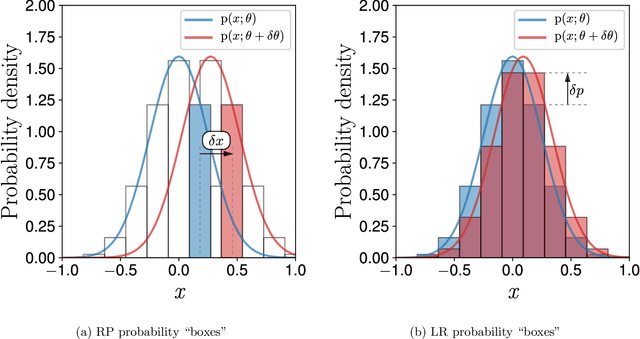
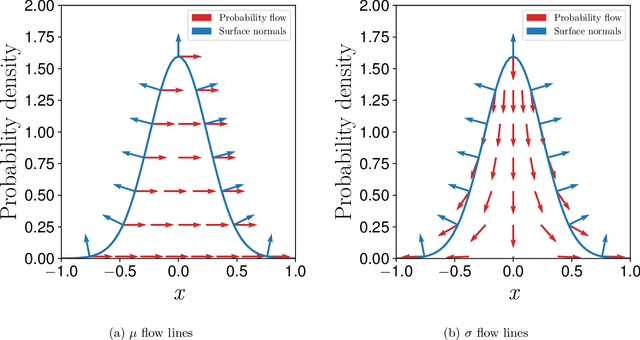


Reparameterization (RP) and likelihood ratio (LR) gradient estimators are used to estimate gradients of expectations throughout machine learning and reinforcement learning; however, they are usually explained as simple mathematical tricks, with no insight into their nature. We use a first principles approach to explain that LR and RP are alternative methods of keeping track of the movement of probability mass, and the two are connected via the divergence theorem. Moreover, we show that the space of all possible estimators combining LR and RP can be completely parameterized by a flow field $u(x)$ and an importance sampling distribution $q(x)$. We prove that there cannot exist a single-sample estimator of this type outside our characterized space, thus, clarifying where we should be searching for better Monte Carlo gradient estimators.
* AISTATS2021; Earlier paper was split in two (arXiv:1910.06419). Refer to the current paper for the unified view, but see the earlier paper for discussion on an importance sampling technique
NoiLIn: Do Noisy Labels Always Hurt Adversarial Training?
May 31, 2021

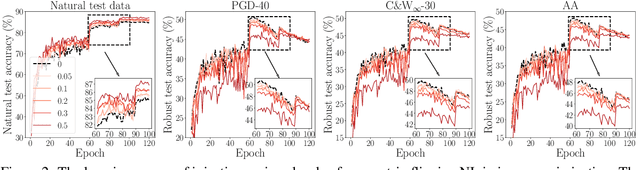

Adversarial training (AT) based on minimax optimization is a popular learning style that enhances the model's adversarial robustness. Noisy labels (NL) commonly undermine the learning and hurt the model's performance. Interestingly, both research directions hardly crossover and hit sparks. In this paper, we raise an intriguing question -- Does NL always hurt AT? Firstly, we find that NL injection in inner maximization for generating adversarial data augments natural data implicitly, which benefits AT's generalization. Secondly, we find NL injection in outer minimization for the learning serves as regularization that alleviates robust overfitting, which benefits AT's robustness. To enhance AT's adversarial robustness, we propose "NoiLIn" that gradually increases \underline{Noi}sy \underline{L}abels \underline{In}jection over the AT's training process. Empirically, NoiLIn answers the previous question negatively -- the adversarial robustness can be indeed enhanced by NL injection. Philosophically, we provide a new perspective of the learning with NL: NL should not always be deemed detrimental, and even in the absence of NL in the training set, we may consider injecting it deliberately.
Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization
Mar 31, 2021
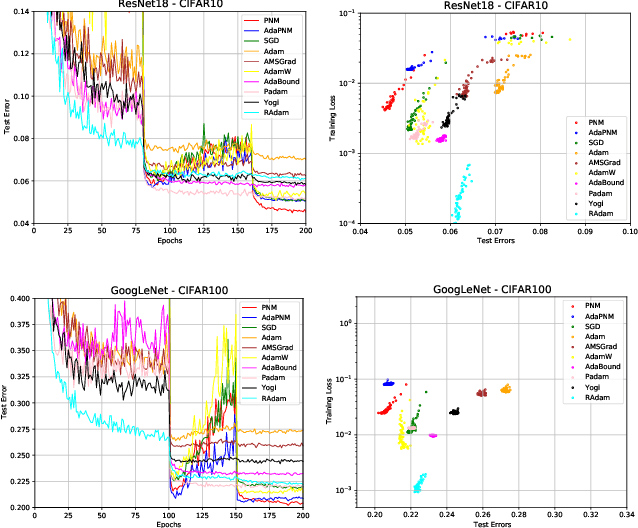
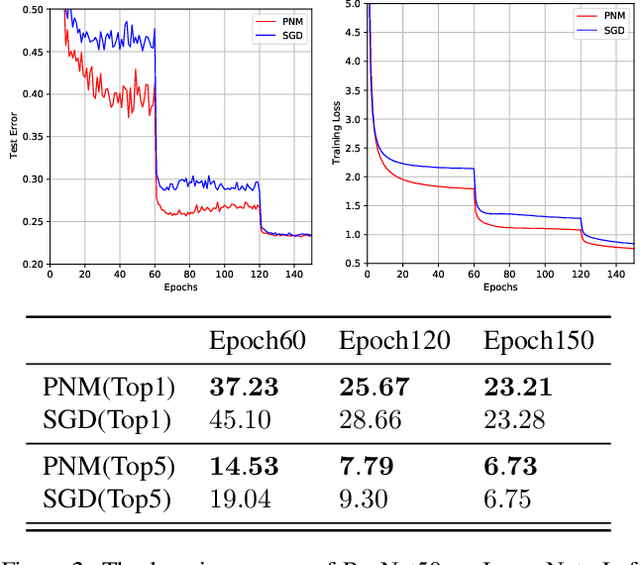
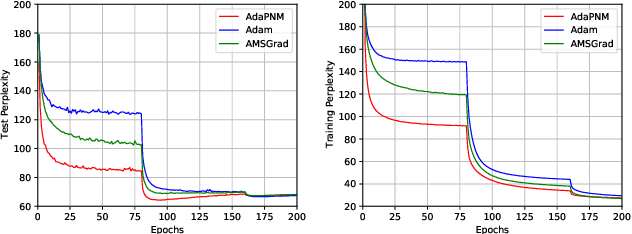
It is well-known that stochastic gradient noise (SGN) acts as implicit regularization for deep learning and is essentially important for both optimization and generalization of deep networks. Some works attempted to artificially simulate SGN by injecting random noise to improve deep learning. However, it turned out that the injected simple random noise cannot work as well as SGN, which is anisotropic and parameter-dependent. For simulating SGN at low computational costs and without changing the learning rate or batch size, we propose the Positive-Negative Momentum (PNM) approach that is a powerful alternative to conventional Momentum in classic optimizers. The introduced PNM method maintains two approximate independent momentum terms. Then, we can control the magnitude of SGN explicitly by adjusting the momentum difference. We theoretically prove the convergence guarantee and the generalization advantage of PNM over Stochastic Gradient Descent (SGD). By incorporating PNM into the two conventional optimizers, SGD with Momentum and Adam, our extensive experiments empirically verified the significant advantage of the PNM-based variants over the corresponding conventional Momentum-based optimizers. Code: \url{https://github.com/zeke-xie/Positive-Negative-Momentum}.
Approximating Instance-Dependent Noise via Instance-Confidence Embedding
Mar 25, 2021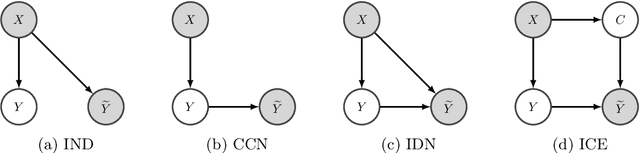
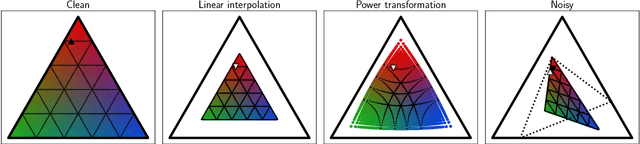


Label noise in multiclass classification is a major obstacle to the deployment of learning systems. However, unlike the widely used class-conditional noise (CCN) assumption that the noisy label is independent of the input feature given the true label, label noise in real-world datasets can be aleatory and heavily dependent on individual instances. In this work, we investigate the instance-dependent noise (IDN) model and propose an efficient approximation of IDN to capture the instance-specific label corruption. Concretely, noting the fact that most columns of the IDN transition matrix have only limited influence on the class-posterior estimation, we propose a variational approximation that uses a single-scalar confidence parameter. To cope with the situation where the mapping from the instance to its confidence value could vary significantly for two adjacent instances, we suggest using instance embedding that assigns a trainable parameter to each instance. The resulting instance-confidence embedding (ICE) method not only performs well under label noise but also can effectively detect ambiguous or mislabeled instances. We validate its utility on various image and text classification tasks.