 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Acquisition Function Evaluations and Decouple Optimizer Updates for Faster Bayesian Optimization
Nov 18, 2025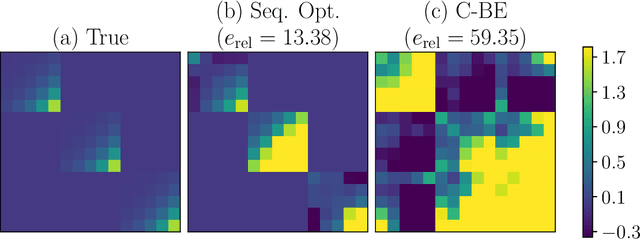

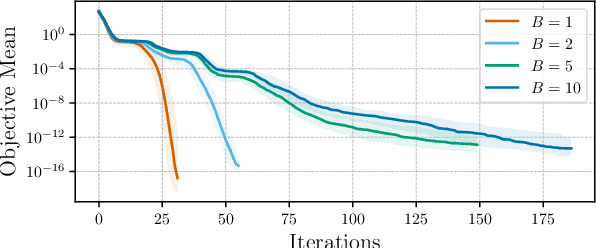

Bayesian optimization (BO) efficiently finds high-performing parameters by maximizing an acquisition function, which models the promise of parameters. A major computational bottleneck arises in acquisition function optimization, where multi-start optimization (MSO) with quasi-Newton (QN) methods is required due to the non-convexity of the acquisition function. BoTorch, a widely used BO library, currently optimizes the summed acquisition function over multiple points, leading to the speedup of MSO owing to PyTorch batching. Nevertheless, this paper empirically demonstrates the suboptimality of this approach in terms of off-diagonal approximation errors in the inverse Hessian of a QN method, slowing down its convergence. To address this problem, we propose to decouple QN updates using a coroutine while batching the acquisition function calls. Our approach not only yields the theoretically identical convergence to the sequential MSO but also drastically reduces the wall-clock time compared to the previous approaches. Our approach is available in GPSampler in Optuna, effectively reducing its computational overhead.
AgroBench: Vision-Language Model Benchmark in Agriculture
Jul 28, 2025



Precise automated understanding of agricultural tasks such as disease identification is essential for sustainable crop production. Recent advances in vision-language models (VLMs) are expected to further expand the range of agricultural tasks by facilitating human-model interaction through easy, text-based communication. Here, we introduce AgroBench (Agronomist AI Benchmark), a benchmark for evaluating VLM models across seven agricultural topics, covering key areas in agricultural engineering and relevant to real-world farming. Unlike recent agricultural VLM benchmarks, AgroBench is annotated by expert agronomists. Our AgroBench covers a state-of-the-art range of categories, including 203 crop categories and 682 disease categories, to thoroughly evaluate VLM capabilities. In our evaluation on AgroBench, we reveal that VLMs have room for improvement in fine-grained identification tasks. Notably, in weed identification, most open-source VLMs perform close to random. With our wide range of topics and expert-annotated categories, we analyze the types of errors made by VLMs and suggest potential pathways for future VLM development. Our dataset and code are available at https://dahlian00.github.io/AgroBenchPage/ .
DOA-Aware Audio-Visual Self-Supervised Learning for Sound Event Localization and Detection
Oct 30, 2024This paper describes sound event localization and detection (SELD) for spatial audio recordings captured by firstorder ambisonics (FOA) microphones. In this task, one may train a deep neural network (DNN) using FOA data annotated with the classes and directions of arrival (DOAs) of sound events. However, the performance of this approach is severely bounded by the amount of annotated data. To overcome this limitation, we propose a novel method of pretraining the feature extraction part of the DNN in a self-supervised manner. We use spatial audio-visual recordings abundantly available as virtual reality contents. Assuming that sound objects are concurrently observed by the FOA microphones and the omni-directional camera, we jointly train audio and visual encoders with contrastive learning such that the audio and visual embeddings of the same recording and DOA are made close. A key feature of our method is that the DOA-wise audio embeddings are jointly extracted from the raw audio data, while the DOA-wise visual embeddings are separately extracted from the local visual crops centered on the corresponding DOA. This encourages the latent features of the audio encoder to represent both the classes and DOAs of sound events. The experiment using the DCASE2022 Task 3 dataset of 20 hours shows non-annotated audio-visual recordings of 100 hours reduced the error score of SELD from 36.4 pts to 34.9 pts.
TeamTrack: A Dataset for Multi-Sport Multi-Object Tracking in Full-pitch Videos
Apr 22, 2024



Multi-object tracking (MOT) is a critical and challenging task in computer vision, particularly in situations involving objects with similar appearances but diverse movements, as seen in team sports. Current methods, largely reliant on object detection and appearance, often fail to track targets in such complex scenarios accurately. This limitation is further exacerbated by the lack of comprehensive and diverse datasets covering the full view of sports pitches. Addressing these issues, we introduce TeamTrack, a pioneering benchmark dataset specifically designed for MOT in sports. TeamTrack is an extensive collection of full-pitch video data from various sports, including soccer, basketball, and handball. Furthermore, we perform a comprehensive analysis and benchmarking effort to underscore TeamTrack's utility and potential impact. Our work signifies a crucial step forward, promising to elevate the precision and effectiveness of MOT in complex, dynamic settings such as team sports. The dataset, project code and competition is released at: https://atomscott.github.io/TeamTrack/.
INF: Implicit Neural Fusion for LiDAR and Camera
Aug 28, 2023



Sensor fusion has become a popular topic in robotics. However, conventional fusion methods encounter many difficulties, such as data representation differences, sensor variations, and extrinsic calibration. For example, the calibration methods used for LiDAR-camera fusion often require manual operation and auxiliary calibration targets. Implicit neural representations (INRs) have been developed for 3D scenes, and the volume density distribution involved in an INR unifies the scene information obtained by different types of sensors. Therefore, we propose implicit neural fusion (INF) for LiDAR and camera. INF first trains a neural density field of the target scene using LiDAR frames. Then, a separate neural color field is trained using camera images and the trained neural density field. Along with the training process, INF both estimates LiDAR poses and optimizes extrinsic parameters. Our experiments demonstrate the high accuracy and stable performance of the proposed method.
Hierarchical Neural Memory Network for Low Latency Event Processing
May 29, 2023



This paper proposes a low latency neural network architecture for event-based dense prediction tasks. Conventional architectures encode entire scene contents at a fixed rate regardless of their temporal characteristics. Instead, the proposed network encodes contents at a proper temporal scale depending on its movement speed. We achieve this by constructing temporal hierarchy using stacked latent memories that operate at different rates. Given low latency event steams, the multi-level memories gradually extract dynamic to static scene contents by propagating information from the fast to the slow memory modules. The architecture not only reduces the redundancy of conventional architectures but also exploits long-term dependencies. Furthermore, an attention-based event representation efficiently encodes sparse event streams into the memory cells. We conduct extensive evaluations on three event-based dense prediction tasks, where the proposed approach outperforms the existing methods on accuracy and latency, while demonstrating effective event and image fusion capabilities. The code is available at https://hamarh.github.io/hmnet/
Multi-objective Tree-structured Parzen Estimator Meets Meta-learning
Dec 13, 2022Hyperparameter optimization (HPO) is essential for the better performance of deep learning, and practitioners often need to consider the trade-off between multiple metrics, such as error rate, latency, memory requirements, robustness, and algorithmic fairness. Due to this demand and the heavy computation of deep learning, the acceleration of multi-objective (MO) optimization becomes ever more important. Although meta-learning has been extensively studied to speedup HPO, existing methods are not applicable to the MO tree-structured parzen estimator (MO-TPE), a simple yet powerful MO-HPO algorithm. In this paper, we extend TPE's acquisition function to the meta-learning setting, using a task similarity defined by the overlap in promising domains of each task. In a comprehensive set of experiments, we demonstrate that our method accelerates MO-TPE on tabular HPO benchmarks and yields state-of-the-art performance. Our method was also validated externally by winning the AutoML 2022 competition on "Multiobjective Hyperparameter Optimization for Transformers".
Efficient stereo matching on embedded GPUs with zero-means cross correlation
Dec 01, 2022



Mobile stereo-matching systems have become an important part of many applications, such as automated-driving vehicles and autonomous robots. Accurate stereo-matching methods usually lead to high computational complexity; however, mobile platforms have only limited hardware resources to keep their power consumption low; this makes it difficult to maintain both an acceptable processing speed and accuracy on mobile platforms. To resolve this trade-off, we herein propose a novel acceleration approach for the well-known zero-means normalized cross correlation (ZNCC) matching cost calculation algorithm on a Jetson Tx2 embedded GPU. In our method for accelerating ZNCC, target images are scanned in a zigzag fashion to efficiently reuse one pixel's computation for its neighboring pixels; this reduces the amount of data transmission and increases the utilization of on-chip registers, thus increasing the processing speed. As a result, our method is 2X faster than the traditional image scanning method, and 26% faster than the latest NCC method. By combining this technique with the domain transformation (DT) algorithm, our system show real-time processing speed of 32 fps, on a Jetson Tx2 GPU for 1,280x384 pixel images with a maximum disparity of 128. Additionally, the evaluation results on the KITTI 2015 benchmark show that our combined system is more accurate than the same algorithm combined with census by 7.26%, while maintaining almost the same processing speed.
How does AI play football? An analysis of RL and real-world football strategies
Nov 24, 2021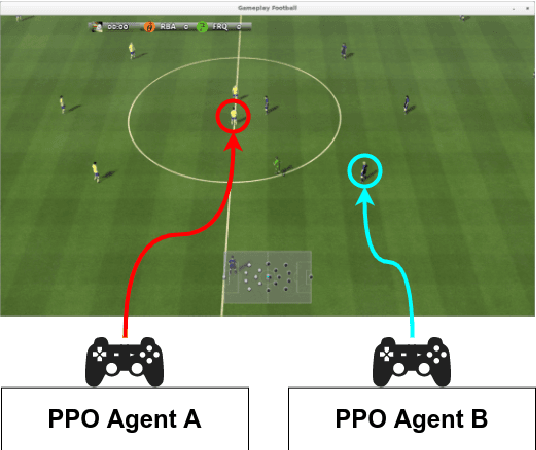

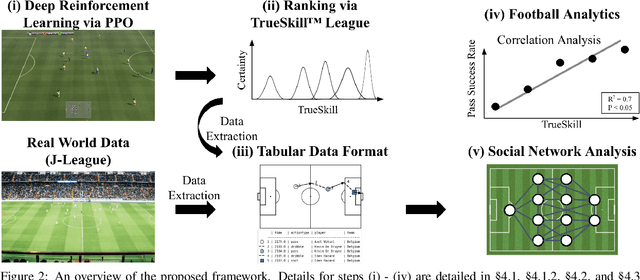
Recent advances in reinforcement learning (RL) have made it possible to develop sophisticated agents that excel in a wide range of applications. Simulations using such agents can provide valuable information in scenarios that are difficult to scientifically experiment in the real world. In this paper, we examine the play-style characteristics of football RL agents and uncover how strategies may develop during training. The learnt strategies are then compared with those of real football players. We explore what can be learnt from the use of simulated environments by using aggregated statistics and social network analysis (SNA). As a result, we found that (1) there are strong correlations between the competitiveness of an agent and various SNA metrics and (2) aspects of the RL agents play style become similar to real world footballers as the agent becomes more competitive. We discuss further advances that may be necessary to improve our understanding necessary to fully utilise RL for the analysis of football.
Heterogeneous Grid Convolution for Adaptive, Efficient, and Controllable Computation
Apr 22, 2021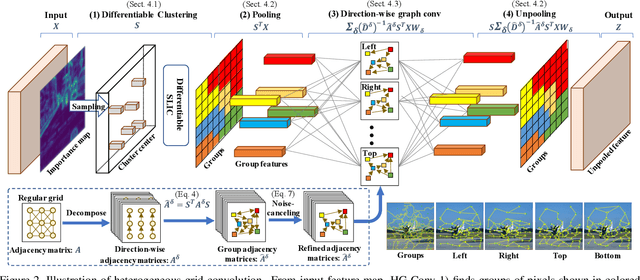
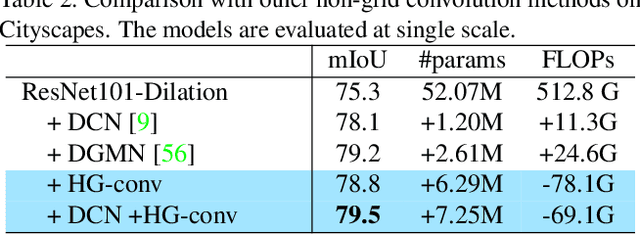

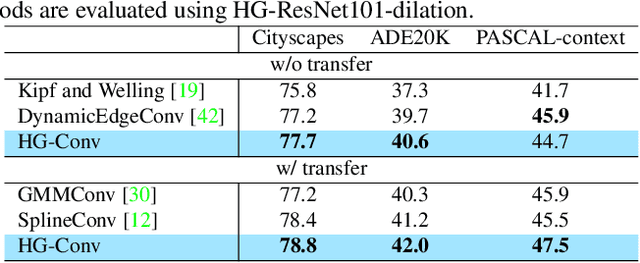
This paper proposes a novel heterogeneous grid convolution that builds a graph-based image representation by exploiting heterogeneity in the image content, enabling adaptive, efficient, and controllable computations in a convolutional architecture. More concretely, the approach builds a data-adaptive graph structure from a convolutional layer by a differentiable clustering method, pools features to the graph, performs a novel direction-aware graph convolution, and unpool features back to the convolutional layer. By using the developed module, the paper proposes heterogeneous grid convolutional networks, highly efficient yet strong extension of existing architectures. We have evaluated the proposed approach on four image understanding tasks, semantic segmentation, object localization, road extraction, and salient object detection. The proposed method is effective on three of the four tasks. Especially, the method outperforms a strong baseline with more than 90% reduction in floating-point operations for semantic segmentation, and achieves the state-of-the-art result for road extraction. We will share our code, model, and data.