 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Locomotion on Complex Terrain for Quadrupedal Robots with Foot Position Maps and Stability Rewards
Apr 03, 2026Quadrupedal locomotion over complex terrain has been a long-standing research topic in robotics. While recent reinforcement learning-based locomotion methods improve generalizability and foot-placement precision, they rely on implicit inference of foot positions from joint angles, lacking the explicit precision and stability guarantees of optimization-based approaches. To address this, we introduce a foot position map integrated into the heightmap, and a dynamic locomotion-stability reward within an attention-based framework to achieve locomotion on complex terrain. We validate our method extensively on terrains seen during training as well as out-of-domain (OOD) terrains. Our results demonstrate that the proposed method enables precise and stable movement, resulting in improved locomotion success rates on both in-domain and OOD terrains.
ScanDP: Generalizable 3D Scanning with Diffusion Policy
Mar 11, 2026Learning-based 3D Scanning plays a crucial role in enabling efficient and accurate scanning of target objects. However, recent reinforcement learning-based methods often require large-scale training data and still struggle to generalize to unseen object categories.In this work, we propose a data-efficient 3D scanning framework that uses Diffusion Policy to imitate human-like scanning strategies. To enhance robustness and generalization, we adopt the Occupancy Grid Mapping instead of direct point cloud processing, offering improved noise resilience and handling of diverse object geometries. We also introduce a hybrid approach combining a sphere-based space representation with a path optimization procedure that ensures path safety and scanning efficiency. This approach addresses limitations in conventional imitation learning, such as redundant or unpredictable behavior. We evaluate our method on diverse unseen objects in both shape and scale. Ours achieves higher coverage and shorter paths than baselines, while remaining robust to sensor noise. We further confirm practical feasibility and stable operation in real-world execution.
FrameVGGT: Frame Evidence Rolling Memory for streaming VGGT
Mar 08, 2026Streaming Visual Geometry Transformers such as StreamVGGT enable strong online 3D perception but suffer from unbounded KV-cache growth, which limits deployment over long streams. We revisit bounded-memory streaming from the perspective of geometric support. In geometry-driven reasoning, memory quality depends not only on how many tokens are retained, but also on whether the retained memory still preserves sufficiently coherent local support. This suggests that token-level retention may become less suitable under fixed budgets, as it can thin the evidence available within each contributing frame and make subsequent fusion more sensitive to weakly aligned history. Motivated by this observation, we propose FrameVGGT, a frame-driven rolling explicit-memory framework that treats each frame's incremental KV contribution as a coherent evidence block. FrameVGGT summarizes each block into a compact prototype and maintains a fixed-capacity mid-term bank of complementary frame blocks under strict budgets, with an optional lightweight anchor tier for rare prolonged degradation. Across long-sequence 3D reconstruction, video depth estimation, and camera pose benchmarks, FrameVGGT achieves favorable accuracy--memory trade-offs under bounded memory, while maintaining more stable geometry over long streams.
Stereo-LiDAR Fusion by Semi-Global Matching With Discrete Disparity-Matching Cost and Semidensification
Apr 07, 2025We present a real-time, non-learning depth estimation method that fuses Light Detection and Ranging (LiDAR) data with stereo camera input. Our approach comprises three key techniques: Semi-Global Matching (SGM) stereo with Discrete Disparity-matching Cost (DDC), semidensification of LiDAR disparity, and a consistency check that combines stereo images and LiDAR data. Each of these components is designed for parallelization on a GPU to realize real-time performance. When it was evaluated on the KITTI dataset, the proposed method achieved an error rate of 2.79\%, outperforming the previous state-of-the-art real-time stereo-LiDAR fusion method, which had an error rate of 3.05\%. Furthermore, we tested the proposed method in various scenarios, including different LiDAR point densities, varying weather conditions, and indoor environments, to demonstrate its high adaptability. We believe that the real-time and non-learning nature of our method makes it highly practical for applications in robotics and automation.
* 8 pages, 8 figures, 7 tables
Robust LiDAR-Camera Calibration with 2D Gaussian Splatting
Apr 01, 2025



LiDAR-camera systems have become increasingly popular in robotics recently. A critical and initial step in integrating the LiDAR and camera data is the calibration of the LiDAR-camera system. Most existing calibration methods rely on auxiliary target objects, which often involve complex manual operations, whereas targetless methods have yet to achieve practical effectiveness. Recognizing that 2D Gaussian Splatting (2DGS) can reconstruct geometric information from camera image sequences, we propose a calibration method that estimates LiDAR-camera extrinsic parameters using geometric constraints. The proposed method begins by reconstructing colorless 2DGS using LiDAR point clouds. Subsequently, we update the colors of the Gaussian splats by minimizing the photometric loss. The extrinsic parameters are optimized during this process. Additionally, we address the limitations of the photometric loss by incorporating the reprojection and triangulation losses, thereby enhancing the calibration robustness and accuracy.
* Accepted in IEEE Robotics and Automation Letters. Code available at: https://github.com/ShuyiZhou495/RobustCalibration
NeAS: 3D Reconstruction from X-ray Images using Neural Attenuation Surface
Mar 10, 2025Reconstructing three-dimensional (3D) structures from two-dimensional (2D) X-ray images is a valuable and efficient technique in medical applications that requires less radiation exposure than computed tomography scans. Recent approaches that use implicit neural representations have enabled the synthesis of novel views from sparse X-ray images. However, although image synthesis has improved the accuracy, the accuracy of surface shape estimation remains insufficient. Therefore, we propose a novel approach for reconstructing 3D scenes using a Neural Attenuation Surface (NeAS) that simultaneously captures the surface geometry and attenuation coefficient fields. NeAS incorporates a signed distance function (SDF), which defines the attenuation field and aids in extracting the 3D surface within the scene. We conducted experiments using simulated and authentic X-ray images, and the results demonstrated that NeAS could accurately extract 3D surfaces within a scene using only 2D X-ray images.
CAPT: Category-level Articulation Estimation from a Single Point Cloud Using Transformer
Feb 27, 2024



The ability to estimate joint parameters is essential for various applications in robotics and computer vision. In this paper, we propose CAPT: category-level articulation estimation from a point cloud using Transformer. CAPT uses an end-to-end transformer-based architecture for joint parameter and state estimation of articulated objects from a single point cloud. The proposed CAPT methods accurately estimate joint parameters and states for various articulated objects with high precision and robustness. The paper also introduces a motion loss approach, which improves articulation estimation performance by emphasizing the dynamic features of articulated objects. Additionally, the paper presents a double voting strategy to provide the framework with coarse-to-fine parameter estimation. Experimental results on several category datasets demonstrate that our methods outperform existing alternatives for articulation estimation. Our research provides a promising solution for applying Transformer-based architectures in articulated object analysis.
REF$^2$-NeRF: Reflection and Refraction aware Neural Radiance Field
Nov 30, 2023



Recently, significant progress has been made in the study of methods for 3D reconstruction from multiple images using implicit neural representations, exemplified by the neural radiance field (NeRF) method. Such methods, which are based on volume rendering, can model various light phenomena, and various extended methods have been proposed to accommodate different scenes and situations. However, when handling scenes with multiple glass objects, e.g., objects in a glass showcase, modeling the target scene accurately has been challenging due to the presence of multiple reflection and refraction effects. Thus, this paper proposes a NeRF-based modeling method for scenes containing a glass case. In the proposed method, refraction and reflection are modeled using elements that are dependent and independent of the viewer's perspective. This approach allows us to estimate the surfaces where refraction occurs, i.e., glass surfaces, and enables the separation and modeling of both direct and reflected light components. Compared to existing methods, the proposed method enables more accurate modeling of both glass refraction and the overall scene.
INF: Implicit Neural Fusion for LiDAR and Camera
Aug 28, 2023



Sensor fusion has become a popular topic in robotics. However, conventional fusion methods encounter many difficulties, such as data representation differences, sensor variations, and extrinsic calibration. For example, the calibration methods used for LiDAR-camera fusion often require manual operation and auxiliary calibration targets. Implicit neural representations (INRs) have been developed for 3D scenes, and the volume density distribution involved in an INR unifies the scene information obtained by different types of sensors. Therefore, we propose implicit neural fusion (INF) for LiDAR and camera. INF first trains a neural density field of the target scene using LiDAR frames. Then, a separate neural color field is trained using camera images and the trained neural density field. Along with the training process, INF both estimates LiDAR poses and optimizes extrinsic parameters. Our experiments demonstrate the high accuracy and stable performance of the proposed method.
Non-learning Stereo-aided Depth Completion under Mis-projection via Selective Stereo Matching
Oct 04, 2022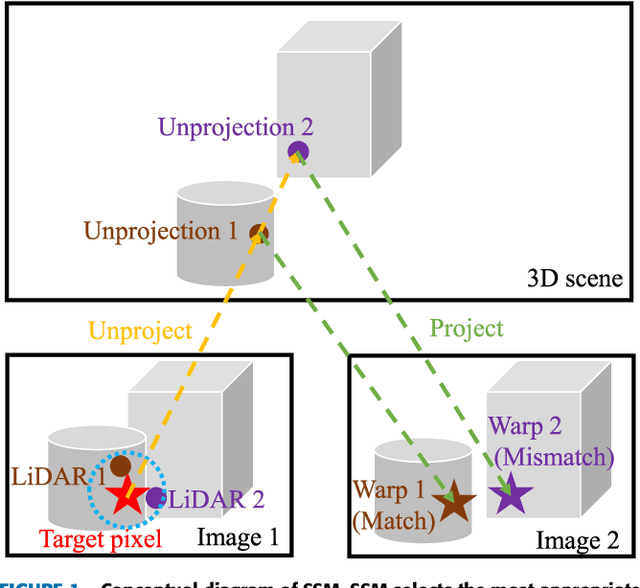
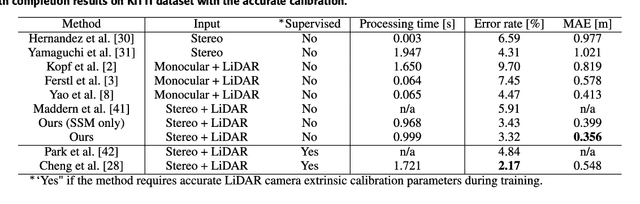
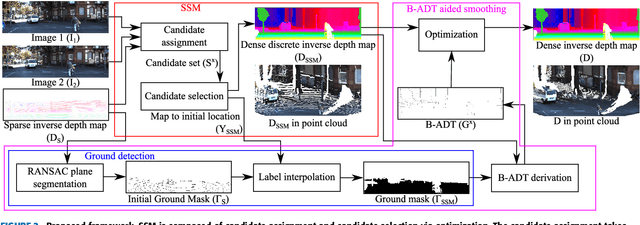

We propose a non-learning depth completion method for a sparse depth map captured using a light detection and ranging (LiDAR) sensor guided by a pair of stereo images. Generally, conventional stereo-aided depth completion methods have two limiations. (i) They assume the given sparse depth map is accurately aligned to the input image, whereas the alignment is difficult to achieve in practice. (ii) They have limited accuracy in the long range because the depth is estimated by pixel disparity. To solve the abovementioned limitations, we propose selective stereo matching (SSM) that searches the most appropriate depth value for each image pixel from its neighborly projected LiDAR points based on an energy minimization framework. This depth selection approach can handle any type of mis-projection. Moreover, SSM has an advantage in terms of long-range depth accuracy because it directly uses the LiDAR measurement rather than the depth acquired from the stereo. SSM is a discrete process; thus, we apply variational smoothing with binary anisotropic diffusion tensor (B-ADT) to generate a continuous depth map while preserving depth discontinuity across object boundaries. Experimentally, compared with the previous state-of-the-art stereo-aided depth completion, the proposed method reduced the mean absolute error (MAE) of the depth estimation to 0.65 times and demonstrated approximately twice more accurate estimation in the long range. Moreover, under various LiDAR-camera calibration errors, the proposed method reduced the depth estimation MAE to 0.34-0.93 times from previous depth completion methods.
* 15 pages, 13 figures