 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Learned Representations and Influence Functions Can Tell Us About Adversarial Examples
Sep 21, 2023



Adversarial examples, deliberately crafted using small perturbations to fool deep neural networks, were first studied in image processing and more recently in NLP. While approaches to detecting adversarial examples in NLP have largely relied on search over input perturbations, image processing has seen a range of techniques that aim to characterise adversarial subspaces over the learned representations. In this paper, we adapt two such approaches to NLP, one based on nearest neighbors and influence functions and one on Mahalanobis distances. The former in particular produces a state-of-the-art detector when compared against several strong baselines; moreover, the novel use of influence functions provides insight into how the nature of adversarial example subspaces in NLP relate to those in image processing, and also how they differ depending on the kind of NLP task.
OptIForest: Optimal Isolation Forest for Anomaly Detection
Jun 23, 2023



Anomaly detection plays an increasingly important role in various fields for critical tasks such as intrusion detection in cybersecurity, financial risk detection, and human health monitoring. A variety of anomaly detection methods have been proposed, and a category based on the isolation forest mechanism stands out due to its simplicity, effectiveness, and efficiency, e.g., iForest is often employed as a state-of-the-art detector for real deployment. While the majority of isolation forests use the binary structure, a framework LSHiForest has demonstrated that the multi-fork isolation tree structure can lead to better detection performance. However, there is no theoretical work answering the fundamentally and practically important question on the optimal tree structure for an isolation forest with respect to the branching factor. In this paper, we establish a theory on isolation efficiency to answer the question and determine the optimal branching factor for an isolation tree. Based on the theoretical underpinning, we design a practical optimal isolation forest OptIForest incorporating clustering based learning to hash which enables more information to be learned from data for better isolation quality. The rationale of our approach relies on a better bias-variance trade-off achieved by bias reduction in OptIForest. Extensive experiments on a series of benchmarking datasets for comparative and ablation studies demonstrate that our approach can efficiently and robustly achieve better detection performance in general than the state-of-the-arts including the deep learning based methods.
Directional Privacy for Deep Learning
Nov 09, 2022



Differentially Private Stochastic Gradient Descent (DP-SGD) is a key method for applying privacy in the training of deep learning models. This applies isotropic Gaussian noise to gradients during training, which can perturb these gradients in any direction, damaging utility. Metric DP, however, can provide alternative mechanisms based on arbitrary metrics that might be more suitable. In this paper we apply \textit{directional privacy}, via a mechanism based on the von Mises-Fisher (VMF) distribution, to perturb gradients in terms of \textit{angular distance} so that gradient direction is broadly preserved. We show that this provides $\epsilon d$-privacy for deep learning training, rather than the $(\epsilon, \delta)$-privacy of the Gaussian mechanism; and that experimentally, on key datasets, the VMF mechanism can outperform the Gaussian in the utility-privacy trade-off.
Detecting Textual Adversarial Examples Based on Distributional Characteristics of Data Representations
Apr 29, 2022

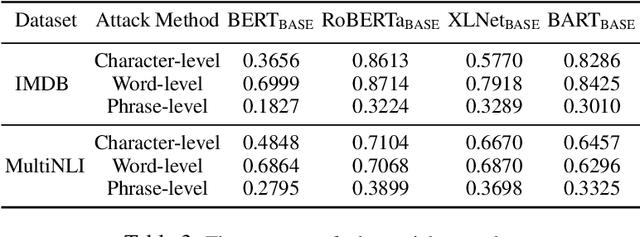

Although deep neural networks have achieved state-of-the-art performance in various machine learning tasks, adversarial examples, constructed by adding small non-random perturbations to correctly classified inputs, successfully fool highly expressive deep classifiers into incorrect predictions. Approaches to adversarial attacks in natural language tasks have boomed in the last five years using character-level, word-level, phrase-level, or sentence-level textual perturbations. While there is some work in NLP on defending against such attacks through proactive methods, like adversarial training, there is to our knowledge no effective general reactive approaches to defence via detection of textual adversarial examples such as is found in the image processing literature. In this paper, we propose two new reactive methods for NLP to fill this gap, which unlike the few limited application baselines from NLP are based entirely on distribution characteristics of learned representations: we adapt one from the image processing literature (Local Intrinsic Dimensionality (LID)), and propose a novel one (MultiDistance Representation Ensemble Method (MDRE)). Adapted LID and MDRE obtain state-of-the-art results on character-level, word-level, and phrase-level attacks on the IMDB dataset as well as on the later two with respect to the MultiNLI dataset. For future research, we publish our code.
Deep Reinforcement Learning Guided Graph Neural Networks for Brain Network Analysis
Mar 18, 2022
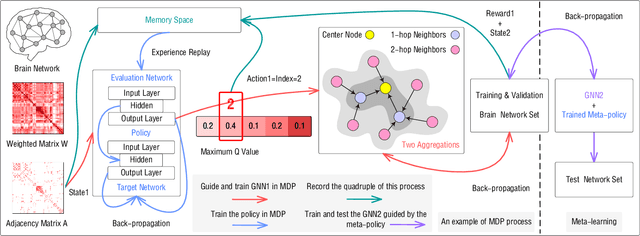

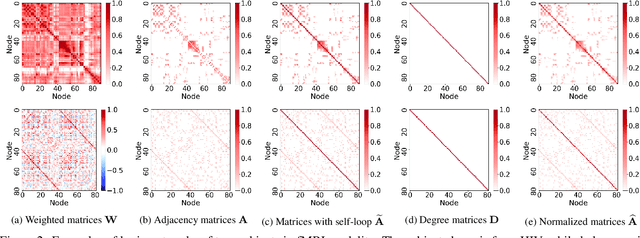
Modern neuroimaging techniques, such as diffusion tensor imaging (DTI) and functional magnetic resonance imaging (fMRI), enable us to model the human brain as a brain network or connectome. Capturing brain networks' structural information and hierarchical patterns is essential for understanding brain functions and disease states. Recently, the promising network representation learning capability of graph neural networks (GNNs) has prompted many GNN-based methods for brain network analysis to be proposed. Specifically, these methods apply feature aggregation and global pooling to convert brain network instances into meaningful low-dimensional representations used for downstream brain network analysis tasks. However, existing GNN-based methods often neglect that brain networks of different subjects may require various aggregation iterations and use GNN with a fixed number of layers to learn all brain networks. Therefore, how to fully release the potential of GNNs to promote brain network analysis is still non-trivial. To solve this problem, we propose a novel brain network representation framework, namely BN-GNN, which searches for the optimal GNN architecture for each brain network. Concretely, BN-GNN employs deep reinforcement learning (DRL) to train a meta-policy to automatically determine the optimal number of feature aggregations (reflected in the number of GNN layers) required for a given brain network. Extensive experiments on eight real-world brain network datasets demonstrate that our proposed BN-GNN improves the performance of traditional GNNs on different brain network analysis tasks.
Neural Rule-Execution Tracking Machine For Transformer-Based Text Generation
Jul 27, 2021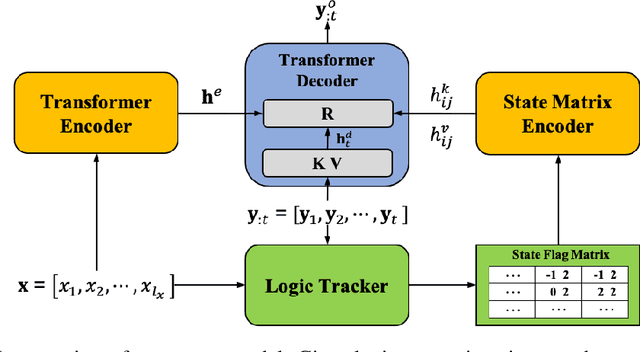

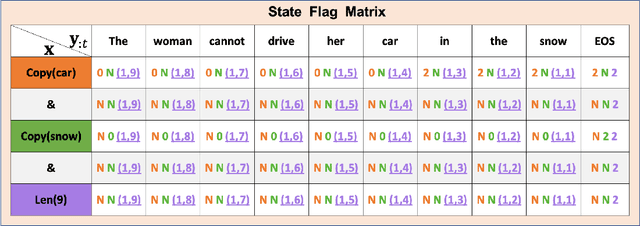
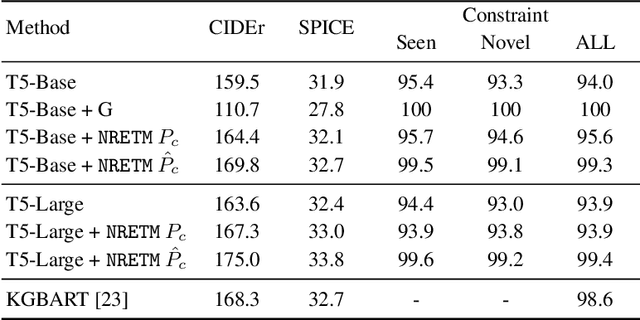
Sequence-to-Sequence (S2S) neural text generation models, especially the pre-trained ones (e.g., BART and T5), have exhibited compelling performance on various natural language generation tasks. However, the black-box nature of these models limits their application in tasks where specific rules (e.g., controllable constraints, prior knowledge) need to be executed. Previous works either design specific model structure (e.g., Copy Mechanism corresponding to the rule "the generated output should include certain words in the source input") or implement specialized inference algorithm (e.g., Constrained Beam Search) to execute particular rules through the text generation. These methods require careful design case-by-case and are difficult to support multiple rules concurrently. In this paper, we propose a novel module named Neural Rule-Execution Tracking Machine that can be equipped into various transformer-based generators to leverage multiple rules simultaneously to guide the neural generation model for superior generation performance in a unified and scalable way. Extensive experimental results on several benchmarks verify the effectiveness of our proposed model in both controllable and general text generation.
Pick-Object-Attack: Type-Specific Adversarial Attack for Object Detection
Jun 05, 2020
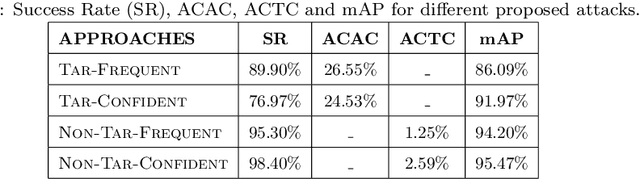
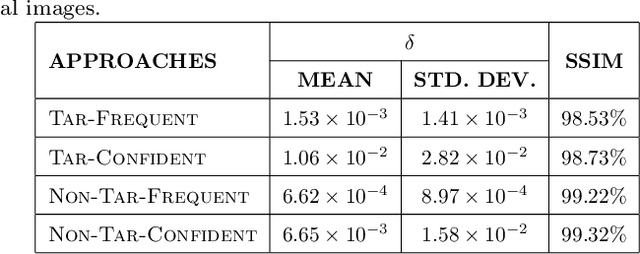
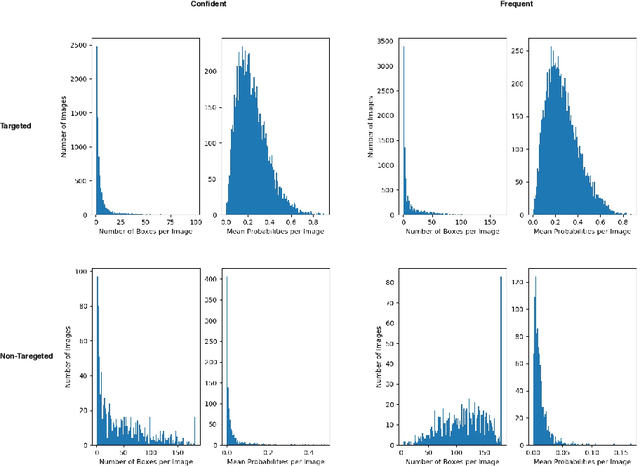
Many recent studies have shown that deep neural models are vulnerable to adversarial samples: images with imperceptible perturbations, for example, can fool image classifiers. In this paper, we generate adversarial examples for object detection, which entails detecting bounding boxes around multiple objects present in the image and classifying them at the same time, making it a harder task than against image classification. We specifically aim to attack the widely used Faster R-CNN by changing the predicted label for a particular object in an image: where prior work has targeted one specific object (a stop sign), we generalise to arbitrary objects, with the key challenge being the need to change the labels of all bounding boxes for all instances of that object type. To do so, we propose a novel method, named Pick-Object-Attack. Pick-Object-Attack successfully adds perturbations only to bounding boxes for the targeted object, preserving the labels of other detected objects in the image. In terms of perceptibility, the perturbations induced by the method are very small. Furthermore, for the first time, we examine the effect of adversarial attacks on object detection in terms of a downstream task, image captioning; we show that where a method that can modify all object types leads to very obvious changes in captions, the changes from our constrained attack are much less apparent.
Siamese Networks for Large-Scale Author Identification
Jan 21, 2020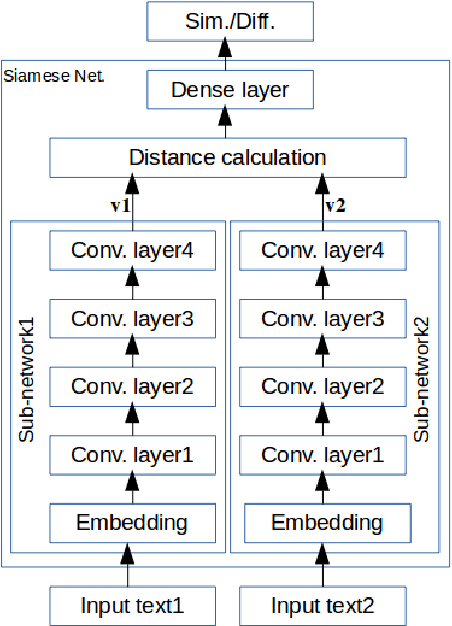
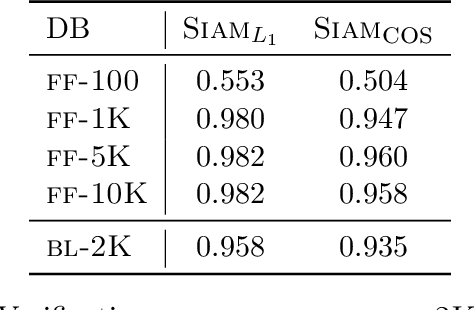
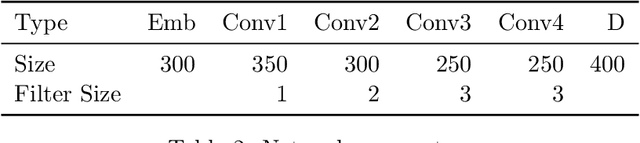
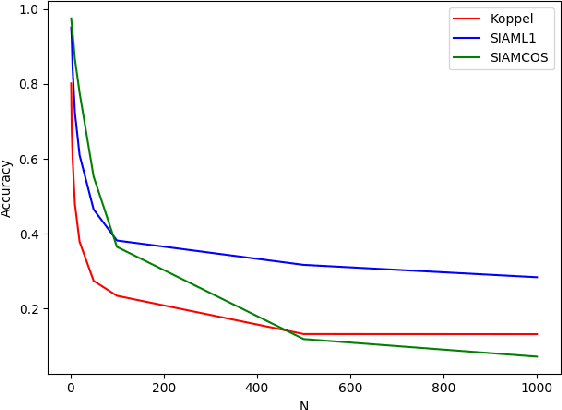
Authorship attribution is the process of identifying the author of a text. Classification-based approaches work well for small numbers of candidate authors, but only similarity-based methods are applicable for larger numbers of authors or for authors beyond the training set. While deep learning methods have been applied to classification-based approaches, applications to similarity-based applications have been limited, and most similarity-based methods only embody static notions of similarity. Siamese networks have been used to develop learned notions of similarity in one-shot image tasks, and also for tasks of mostly semantic relatedness in NLP. We examine their application to the stylistic task of authorship attribution on datasets with large numbers of authors, looking at multiple energy functions and neural network architectures, and show that they can substantially outperform both classification- and existing similarity-based approaches. We also find an unexpected relationship between choice of energy function and number of authors, in terms of performance.
Towards Generating Stylized Image Captions via Adversarial Training
Aug 08, 2019
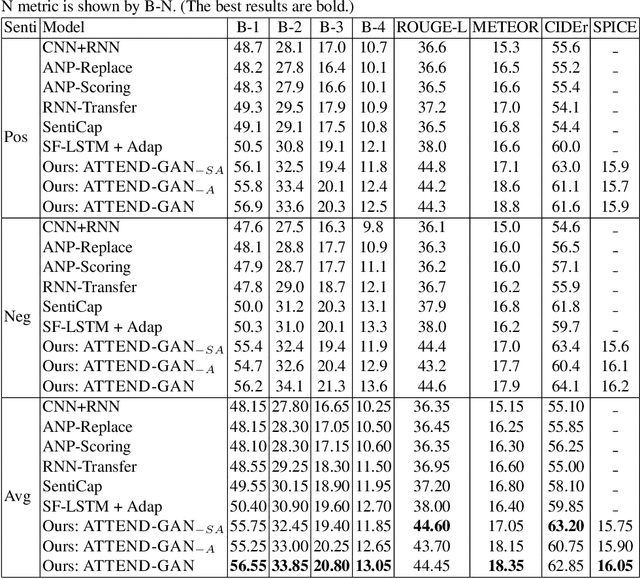
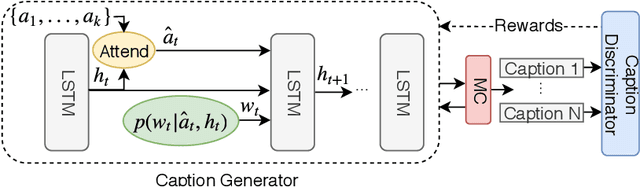
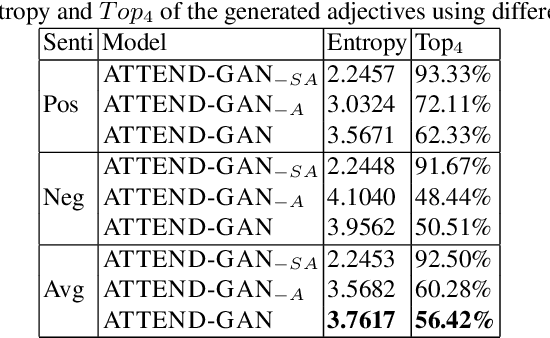
While most image captioning aims to generate objective descriptions of images, the last few years have seen work on generating visually grounded image captions which have a specific style (e.g., incorporating positive or negative sentiment). However, because the stylistic component is typically the last part of training, current models usually pay more attention to the style at the expense of accurate content description. In addition, there is a lack of variability in terms of the stylistic aspects. To address these issues, we propose an image captioning model called ATTEND-GAN which has two core components: first, an attention-based caption generator to strongly correlate different parts of an image with different parts of a caption; and second, an adversarial training mechanism to assist the caption generator to add diverse stylistic components to the generated captions. Because of these components, ATTEND-GAN can generate correlated captions as well as more human-like variability of stylistic patterns. Our system outperforms the state-of-the-art as well as a collection of our baseline models. A linguistic analysis of the generated captions demonstrates that captions generated using ATTEND-GAN have a wider range of stylistic adjectives and adjective-noun pairs.
Image Captioning using Facial Expression and Attention
Aug 08, 2019
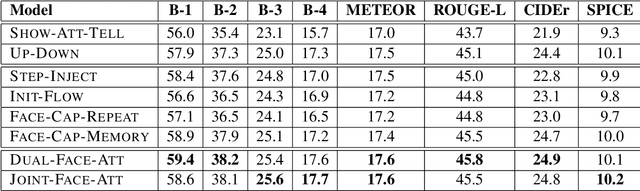

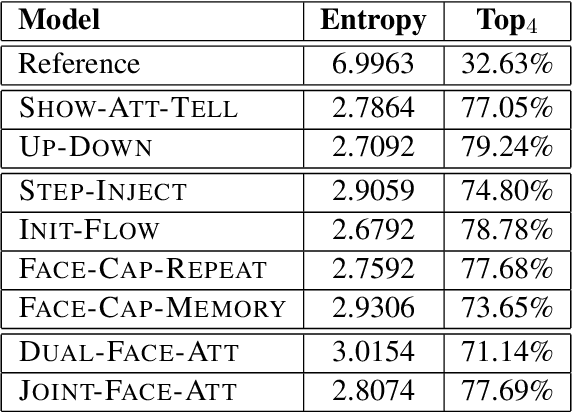
Benefiting from advances in machine vision and natural language processing techniques, current image captioning systems are able to generate detailed visual descriptions. For the most part, these descriptions represent an objective characterisation of the image, although some models do incorporate subjective aspects related to the observer's view of the image, such as sentiment; current models, however, usually do not consider the emotional content of images during the caption generation process. This paper addresses this issue by proposing novel image captioning models which use facial expression features to generate image captions. The models generate image captions using long short-term memory networks applying facial features in addition to other visual features at different time steps. We compare a comprehensive collection of image captioning models with and without facial features using all standard evaluation metrics. The evaluation metrics indicate that applying facial features with an attention mechanism achieves the best performance, showing more expressive and more correlated image captions, on an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the generated captions finds that, perhaps unexpectedly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.