 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Robustness in Large Language Models against Jailbreak Attacks
May 06, 2026Large Language Models (LLMs) have achieved remarkable success but remain highly susceptible to jailbreak attacks, in which adversarial prompts coerce models into generating harmful, unethical, or policy-violating outputs. Such attacks pose real-world risks, eroding safety, trust, and regulatory compliance in high-stakes applications. Although a variety of attack and defense methods have been proposed, existing evaluation practices are inadequate, often relying on narrow metrics like attack success rate that fail to capture the multidimensional nature of LLM security. In this paper, we present a systematic taxonomy of jailbreak attacks and defenses and introduce Security Cube, a unified, multi-dimensional framework for comprehensive evaluation of these techniques. We provide detailed comparison tables of existing attacks and defenses, highlighting key insights and open challenges across the literature. Leveraging Security Cube, we conduct benchmark studies on 13 representative attacks and 5 defenses, establishing a clear view of the current landscape encompassing jailbreak attacks, defenses, automated judges, and LLM vulnerabilities. Based on these evaluations, we distill critical findings, identify unresolved problems, and outline promising research directions for enhancing LLM robustness against jailbreak attacks. Our analysis aims to pave the way towards more robust, interpretable, and trustworthy LLM systems. Our code is available at Code.
When Better Features Mean Greater Risks: The Performance-Privacy Trade-Off in Contrastive Learning
Jun 06, 2025



With the rapid advancement of deep learning technology, pre-trained encoder models have demonstrated exceptional feature extraction capabilities, playing a pivotal role in the research and application of deep learning. However, their widespread use has raised significant concerns about the risk of training data privacy leakage. This paper systematically investigates the privacy threats posed by membership inference attacks (MIAs) targeting encoder models, focusing on contrastive learning frameworks. Through experimental analysis, we reveal the significant impact of model architecture complexity on membership privacy leakage: As more advanced encoder frameworks improve feature-extraction performance, they simultaneously exacerbate privacy-leakage risks. Furthermore, this paper proposes a novel membership inference attack method based on the p-norm of feature vectors, termed the Embedding Lp-Norm Likelihood Attack (LpLA). This method infers membership status, by leveraging the statistical distribution characteristics of the p-norm of feature vectors. Experimental results across multiple datasets and model architectures demonstrate that LpLA outperforms existing methods in attack performance and robustness, particularly under limited attack knowledge and query volumes. This study not only uncovers the potential risks of privacy leakage in contrastive learning frameworks, but also provides a practical basis for privacy protection research in encoder models. We hope that this work will draw greater attention to the privacy risks associated with self-supervised learning models and shed light on the importance of a balance between model utility and training data privacy. Our code is publicly available at: https://github.com/SeroneySun/LpLA_code.
From Pixels to Trajectory: Universal Adversarial Example Detection via Temporal Imprints
Mar 06, 2025For the first time, we unveil discernible temporal (or historical) trajectory imprints resulting from adversarial example (AE) attacks. Standing in contrast to existing studies all focusing on spatial (or static) imprints within the targeted underlying victim models, we present a fresh temporal paradigm for understanding these attacks. Of paramount discovery is that these imprints are encapsulated within a single loss metric, spanning universally across diverse tasks such as classification and regression, and modalities including image, text, and audio. Recognizing the distinct nature of loss between adversarial and clean examples, we exploit this temporal imprint for AE detection by proposing TRAIT (TRaceable Adversarial temporal trajectory ImprinTs). TRAIT operates under minimal assumptions without prior knowledge of attacks, thereby framing the detection challenge as a one-class classification problem. However, detecting AEs is still challenged by significant overlaps between the constructed synthetic losses of adversarial and clean examples due to the absence of ground truth for incoming inputs. TRAIT addresses this challenge by converting the synthetic loss into a spectrum signature, using the technique of Fast Fourier Transform to highlight the discrepancies, drawing inspiration from the temporal nature of the imprints, analogous to time-series signals. Across 12 AE attacks including SMACK (USENIX Sec'2023), TRAIT demonstrates consistent outstanding performance across comprehensively evaluated modalities, tasks, datasets, and model architectures. In all scenarios, TRAIT achieves an AE detection accuracy exceeding 97%, often around 99%, while maintaining a false rejection rate of 1%. TRAIT remains effective under the formulated strong adaptive attacks.
DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
Dec 08, 2024Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a realworld FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
AI-Compass: A Comprehensive and Effective Multi-module Testing Tool for AI Systems
Nov 09, 2024



AI systems, in particular with deep learning techniques, have demonstrated superior performance for various real-world applications. Given the need for tailored optimization in specific scenarios, as well as the concerns related to the exploits of subsurface vulnerabilities, a more comprehensive and in-depth testing AI system becomes a pivotal topic. We have seen the emergence of testing tools in real-world applications that aim to expand testing capabilities. However, they often concentrate on ad-hoc tasks, rendering them unsuitable for simultaneously testing multiple aspects or components. Furthermore, trustworthiness issues arising from adversarial attacks and the challenge of interpreting deep learning models pose new challenges for developing more comprehensive and in-depth AI system testing tools. In this study, we design and implement a testing tool, \tool, to comprehensively and effectively evaluate AI systems. The tool extensively assesses multiple measurements towards adversarial robustness, model interpretability, and performs neuron analysis. The feasibility of the proposed testing tool is thoroughly validated across various modalities, including image classification, object detection, and text classification. Extensive experiments demonstrate that \tool is the state-of-the-art tool for a comprehensive assessment of the robustness and trustworthiness of AI systems. Our research sheds light on a general solution for AI systems testing landscape.
Intellectual Property Protection for Deep Learning Model and Dataset Intelligence
Nov 07, 2024



With the growing applications of Deep Learning (DL), especially recent spectacular achievements of Large Language Models (LLMs) such as ChatGPT and LLaMA, the commercial significance of these remarkable models has soared. However, acquiring well-trained models is costly and resource-intensive. It requires a considerable high-quality dataset, substantial investment in dedicated architecture design, expensive computational resources, and efforts to develop technical expertise. Consequently, safeguarding the Intellectual Property (IP) of well-trained models is attracting increasing attention. In contrast to existing surveys overwhelmingly focusing on model IPP mainly, this survey not only encompasses the protection on model level intelligence but also valuable dataset intelligence. Firstly, according to the requirements for effective IPP design, this work systematically summarizes the general and scheme-specific performance evaluation metrics. Secondly, from proactive IP infringement prevention and reactive IP ownership verification perspectives, it comprehensively investigates and analyzes the existing IPP methods for both dataset and model intelligence. Additionally, from the standpoint of training settings, it delves into the unique challenges that distributed settings pose to IPP compared to centralized settings. Furthermore, this work examines various attacks faced by deep IPP techniques. Finally, we outline prospects for promising future directions that may act as a guide for innovative research.
Releasing Malevolence from Benevolence: The Menace of Benign Data on Machine Unlearning
Jul 06, 2024



Machine learning models trained on vast amounts of real or synthetic data often achieve outstanding predictive performance across various domains. However, this utility comes with increasing concerns about privacy, as the training data may include sensitive information. To address these concerns, machine unlearning has been proposed to erase specific data samples from models. While some unlearning techniques efficiently remove data at low costs, recent research highlights vulnerabilities where malicious users could request unlearning on manipulated data to compromise the model. Despite these attacks' effectiveness, perturbed data differs from original training data, failing hash verification. Existing attacks on machine unlearning also suffer from practical limitations and require substantial additional knowledge and resources. To fill the gaps in current unlearning attacks, we introduce the Unlearning Usability Attack. This model-agnostic, unlearning-agnostic, and budget-friendly attack distills data distribution information into a small set of benign data. These data are identified as benign by automatic poisoning detection tools due to their positive impact on model training. While benign for machine learning, unlearning these data significantly degrades model information. Our evaluation demonstrates that unlearning this benign data, comprising no more than 1% of the total training data, can reduce model accuracy by up to 50%. Furthermore, our findings show that well-prepared benign data poses challenges for recent unlearning techniques, as erasing these synthetic instances demands higher resources than regular data. These insights underscore the need for future research to reconsider "data poisoning" in the context of machine unlearning.
OptIForest: Optimal Isolation Forest for Anomaly Detection
Jun 23, 2023



Anomaly detection plays an increasingly important role in various fields for critical tasks such as intrusion detection in cybersecurity, financial risk detection, and human health monitoring. A variety of anomaly detection methods have been proposed, and a category based on the isolation forest mechanism stands out due to its simplicity, effectiveness, and efficiency, e.g., iForest is often employed as a state-of-the-art detector for real deployment. While the majority of isolation forests use the binary structure, a framework LSHiForest has demonstrated that the multi-fork isolation tree structure can lead to better detection performance. However, there is no theoretical work answering the fundamentally and practically important question on the optimal tree structure for an isolation forest with respect to the branching factor. In this paper, we establish a theory on isolation efficiency to answer the question and determine the optimal branching factor for an isolation tree. Based on the theoretical underpinning, we design a practical optimal isolation forest OptIForest incorporating clustering based learning to hash which enables more information to be learned from data for better isolation quality. The rationale of our approach relies on a better bias-variance trade-off achieved by bias reduction in OptIForest. Extensive experiments on a series of benchmarking datasets for comparative and ablation studies demonstrate that our approach can efficiently and robustly achieve better detection performance in general than the state-of-the-arts including the deep learning based methods.
Source Inference Attacks in Federated Learning
Sep 13, 2021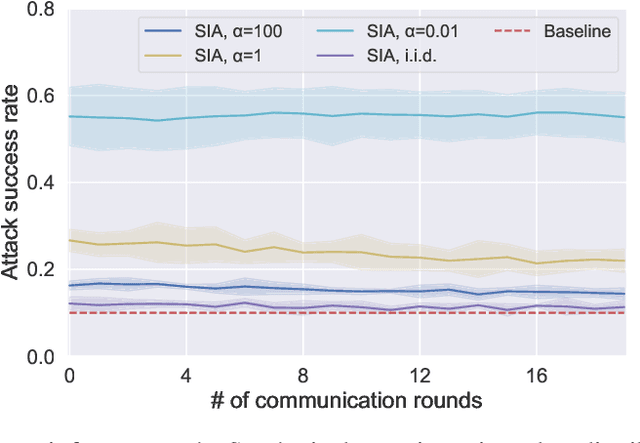

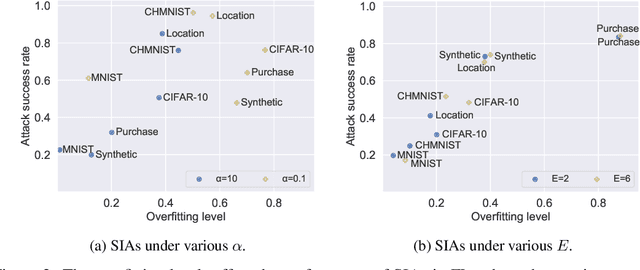
Federated learning (FL) has emerged as a promising privacy-aware paradigm that allows multiple clients to jointly train a model without sharing their private data. Recently, many studies have shown that FL is vulnerable to membership inference attacks (MIAs) that can distinguish the training members of the given model from the non-members. However, existing MIAs ignore the source of a training member, i.e., the information of which client owns the training member, while it is essential to explore source privacy in FL beyond membership privacy of examples from all clients. The leakage of source information can lead to severe privacy issues. For example, identification of the hospital contributing to the training of an FL model for COVID-19 pandemic can render the owner of a data record from this hospital more prone to discrimination if the hospital is in a high risk region. In this paper, we propose a new inference attack called source inference attack (SIA), which can derive an optimal estimation of the source of a training member. Specifically, we innovatively adopt the Bayesian perspective to demonstrate that an honest-but-curious server can launch an SIA to steal non-trivial source information of the training members without violating the FL protocol. The server leverages the prediction loss of local models on the training members to achieve the attack effectively and non-intrusively. We conduct extensive experiments on one synthetic and five real datasets to evaluate the key factors in an SIA, and the results show the efficacy of the proposed source inference attack.
Membership Inference Attacks on Machine Learning: A Survey
Mar 17, 2021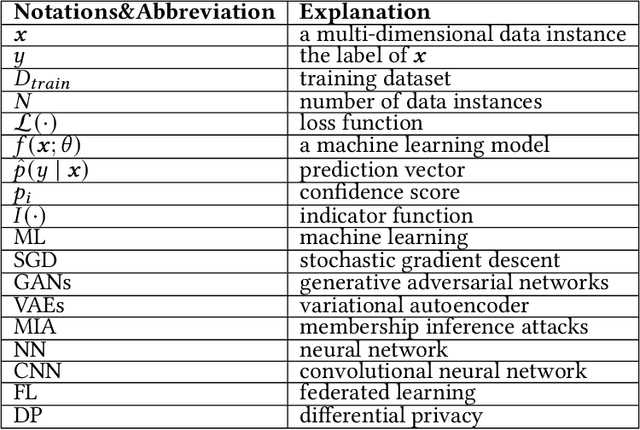
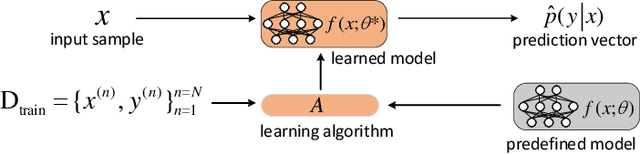

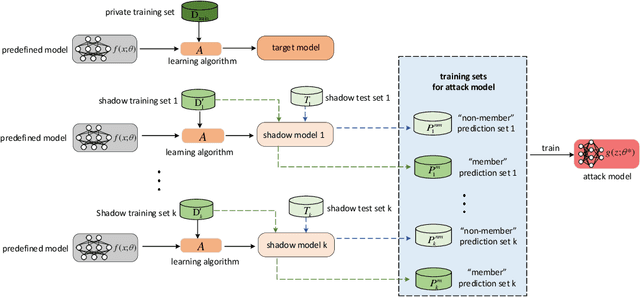
Membership inference attack aims to identify whether a data sample was used to train a machine learning model or not. It can raise severe privacy risks as the membership can reveal an individual's sensitive information. For example, identifying an individual's participation in a hospital's health analytics training set reveals that this individual was once a patient in that hospital. Membership inference attacks have been shown to be effective on various machine learning models, such as classification models, generative models, and sequence-to-sequence models. Meanwhile, many methods are proposed to defend such a privacy attack. Although membership inference attack is an emerging and rapidly growing research area, there is no comprehensive survey on this topic yet. In this paper, we bridge this important gap in membership inference attack literature. We present the first comprehensive survey of membership inference attacks. We summarize and categorize existing membership inference attacks and defenses and explicitly present how to implement attacks in various settings. Besides, we discuss why membership inference attacks work and summarize the benchmark datasets to facilitate comparison and ensure fairness of future work. Finally, we propose several possible directions for future research and possible applications relying on reviewed works.