 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Theoretical Bounds: Empirical Privacy Loss Calibration for Text Rewriting Under Local Differential Privacy
Mar 24, 2026The growing use of large language models has increased interest in sharing textual data in a privacy-preserving manner. One prominent line of work addresses this challenge through text rewriting under Local Differential Privacy (LDP), where input texts are locally obfuscated before release with formal privacy guarantees. These guarantees are typically expressed by a parameter $\varepsilon$ that upper bounds the worst-case privacy loss. However, nominal $\varepsilon$ values are often difficult to interpret and compare across mechanisms. In this work, we investigate how to empirically calibrate across text rewriting mechanisms under LDP. We propose TeDA, which formulates calibration via a hypothesis-testing framework that instantiates text distinguishability audits in both surface and embedding spaces, enabling empirical assessment of indistinguishability from privatized texts. Applying this calibration to several representative mechanisms, we demonstrate that similar nominal $\varepsilon$ bounds can imply very different levels of distinguishability. Empirical calibration thus provides a more comparable footing for evaluating privacy-utility trade-offs, as well as a practical tool for mechanism comparison and analysis in real-world LDP text rewriting deployments.
Empirical Calibration and Metric Differential Privacy in Language Models
Mar 18, 2025



NLP models trained with differential privacy (DP) usually adopt the DP-SGD framework, and privacy guarantees are often reported in terms of the privacy budget $\epsilon$. However, $\epsilon$ does not have any intrinsic meaning, and it is generally not possible to compare across variants of the framework. Work in image processing has therefore explored how to empirically calibrate noise across frameworks using Membership Inference Attacks (MIAs). However, this kind of calibration has not been established for NLP. In this paper, we show that MIAs offer little help in calibrating privacy, whereas reconstruction attacks are more useful. As a use case, we define a novel kind of directional privacy based on the von Mises-Fisher (VMF) distribution, a metric DP mechanism that perturbs angular distance rather than adding (isotropic) Gaussian noise, and apply this to NLP architectures. We show that, even though formal guarantees are incomparable, empirical privacy calibration reveals that each mechanism has different areas of strength with respect to utility-privacy trade-offs.
Comparing privacy notions for protection against reconstruction attacks in machine learning
Feb 06, 2025



Within the machine learning community, reconstruction attacks are a principal concern and have been identified even in federated learning (FL), which was designed with privacy preservation in mind. In response to these threats, the privacy community recommends the use of differential privacy (DP) in the stochastic gradient descent algorithm, termed DP-SGD. However, the proliferation of variants of DP in recent years\textemdash such as metric privacy\textemdash has made it challenging to conduct a fair comparison between different mechanisms due to the different meanings of the privacy parameters $\epsilon$ and $\delta$ across different variants. Thus, interpreting the practical implications of $\epsilon$ and $\delta$ in the FL context and amongst variants of DP remains ambiguous. In this paper, we lay a foundational framework for comparing mechanisms with differing notions of privacy guarantees, namely $(\epsilon,\delta)$-DP and metric privacy. We provide two foundational means of comparison: firstly, via the well-established $(\epsilon,\delta)$-DP guarantees, made possible through the R\'enyi differential privacy framework; and secondly, via Bayes' capacity, which we identify as an appropriate measure for reconstruction threats.
IDT: Dual-Task Adversarial Attacks for Privacy Protection
Jun 28, 2024



Natural language processing (NLP) models may leak private information in different ways, including membership inference, reconstruction or attribute inference attacks. Sensitive information may not be explicit in the text, but hidden in underlying writing characteristics. Methods to protect privacy can involve using representations inside models that are demonstrated not to detect sensitive attributes or -- for instance, in cases where users might not trust a model, the sort of scenario of interest here -- changing the raw text before models can have access to it. The goal is to rewrite text to prevent someone from inferring a sensitive attribute (e.g. the gender of the author, or their location by the writing style) whilst keeping the text useful for its original intention (e.g. the sentiment of a product review). The few works tackling this have focused on generative techniques. However, these often create extensively different texts from the original ones or face problems such as mode collapse. This paper explores a novel adaptation of adversarial attack techniques to manipulate a text to deceive a classifier w.r.t one task (privacy) whilst keeping the predictions of another classifier trained for another task (utility) unchanged. We propose IDT, a method that analyses predictions made by auxiliary and interpretable models to identify which tokens are important to change for the privacy task, and which ones should be kept for the utility task. We evaluate different datasets for NLP suitable for different tasks. Automatic and human evaluations show that IDT retains the utility of text, while also outperforming existing methods when deceiving a classifier w.r.t privacy task.
Bayes' capacity as a measure for reconstruction attacks in federated learning
Jun 19, 2024

Within the machine learning community, reconstruction attacks are a principal attack of concern and have been identified even in federated learning, which was designed with privacy preservation in mind. In federated learning, it has been shown that an adversary with knowledge of the machine learning architecture is able to infer the exact value of a training element given an observation of the weight updates performed during stochastic gradient descent. In response to these threats, the privacy community recommends the use of differential privacy in the stochastic gradient descent algorithm, termed DP-SGD. However, DP has not yet been formally established as an effective countermeasure against reconstruction attacks. In this paper, we formalise the reconstruction threat model using the information-theoretic framework of quantitative information flow. We show that the Bayes' capacity, related to the Sibson mutual information of order infinity, represents a tight upper bound on the leakage of the DP-SGD algorithm to an adversary interested in performing a reconstruction attack. We provide empirical results demonstrating the effectiveness of this measure for comparing mechanisms against reconstruction threats.
Directional Privacy for Deep Learning
Nov 09, 2022



Differentially Private Stochastic Gradient Descent (DP-SGD) is a key method for applying privacy in the training of deep learning models. This applies isotropic Gaussian noise to gradients during training, which can perturb these gradients in any direction, damaging utility. Metric DP, however, can provide alternative mechanisms based on arbitrary metrics that might be more suitable. In this paper we apply \textit{directional privacy}, via a mechanism based on the von Mises-Fisher (VMF) distribution, to perturb gradients in terms of \textit{angular distance} so that gradient direction is broadly preserved. We show that this provides $\epsilon d$-privacy for deep learning training, rather than the $(\epsilon, \delta)$-privacy of the Gaussian mechanism; and that experimentally, on key datasets, the VMF mechanism can outperform the Gaussian in the utility-privacy trade-off.
Generalised Differential Privacy for Text Document Processing
Nov 26, 2018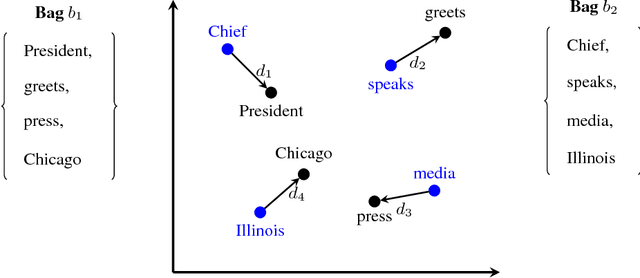
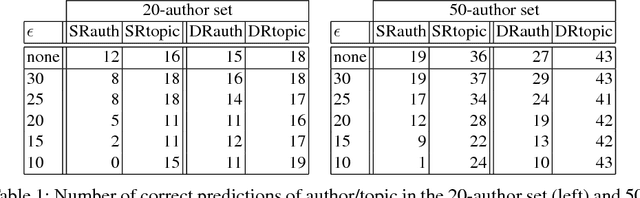

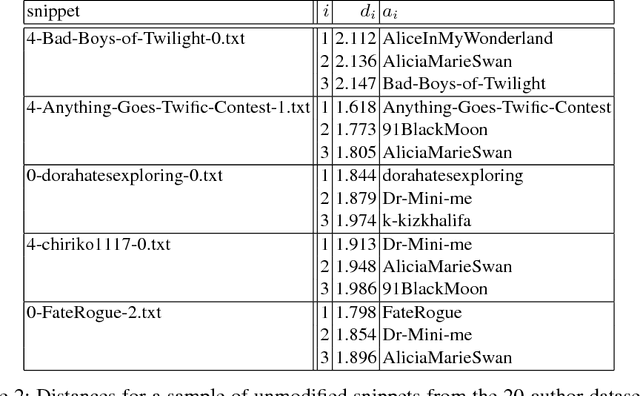
We address the problem of how to "obfuscate" texts by removing stylistic clues which can identify authorship, whilst preserving (as much as possible) the content of the text. In this paper we combine ideas from "generalised differential privacy" and machine learning techniques for text processing to model privacy for text documents. We define a privacy mechanism that operates at the level of text documents represented as "bags-of-words" - these representations are typical in machine learning and contain sufficient information to carry out many kinds of classification tasks including topic identification and authorship attribution (of the original documents). We show that our mechanism satisfies privacy with respect to a metric for semantic similarity, thereby providing a balance between utility, defined by the semantic content of texts, with the obfuscation of stylistic clues. We demonstrate our implementation on a "fan fiction" dataset, confirming that it is indeed possible to disguise writing style effectively whilst preserving enough information and variation for accurate content classification tasks.