 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Traffic Advisors: Distributed, Multi-view Traffic Prediction for Smart Cities
Apr 13, 2022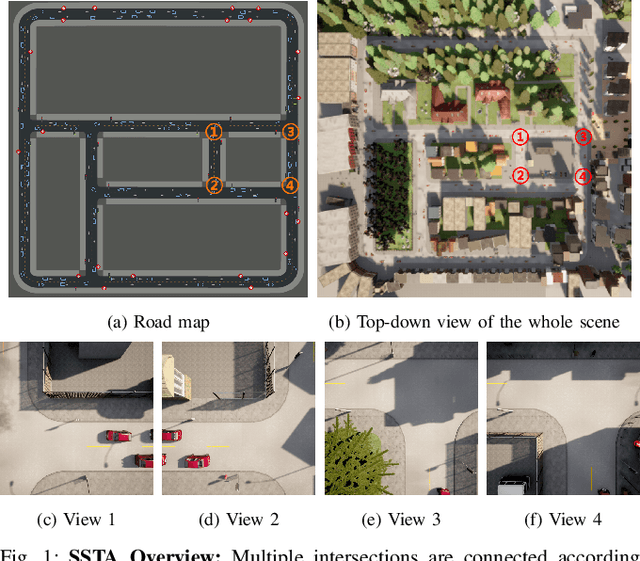
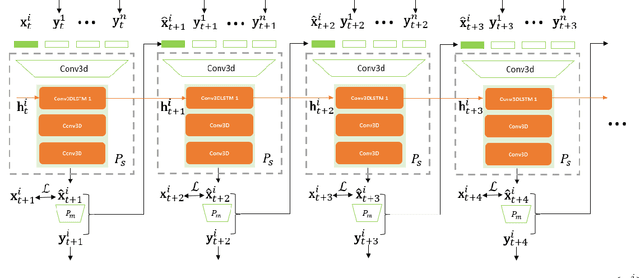
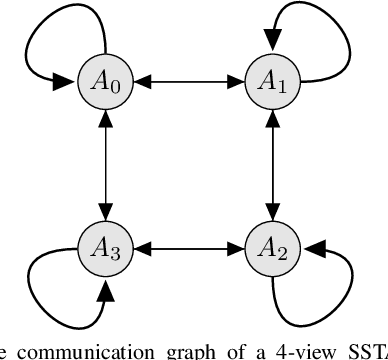
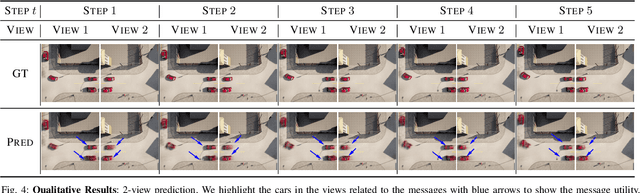
Connected and Autonomous Vehicles (CAVs) are becoming more widely deployed, but it is unclear how to best deploy smart infrastructure to maximize their capabilities. One key challenge is to ensure CAVs can reliably perceive other agents, especially occluded ones. A further challenge is the desire for smart infrastructure to be autonomous and readily scalable to wide-area deployments, similar to modern traffic lights. The present work proposes the Self-Supervised Traffic Advisor (SSTA), an infrastructure edge device concept that leverages self-supervised video prediction in concert with a communication and co-training framework to enable autonomously predicting traffic throughout a smart city. An SSTA is a statically-mounted camera that overlooks an intersection or area of complex traffic flow that predicts traffic flow as future video frames and learns to communicate with neighboring SSTAs to enable predicting traffic before it appears in the Field of View (FOV). The proposed framework aims at three goals: (1) inter-device communication to enable high-quality predictions, (2) scalability to an arbitrary number of devices, and (3) lifelong online learning to ensure adaptability to changing circumstances. Finally, an SSTA can broadcast its future predicted video frames directly as information for CAVs to run their own post-processing for the purpose of control.
FIG-OP: Exploring Large-Scale Unknown Environments on a Fixed Time Budget
Mar 12, 2022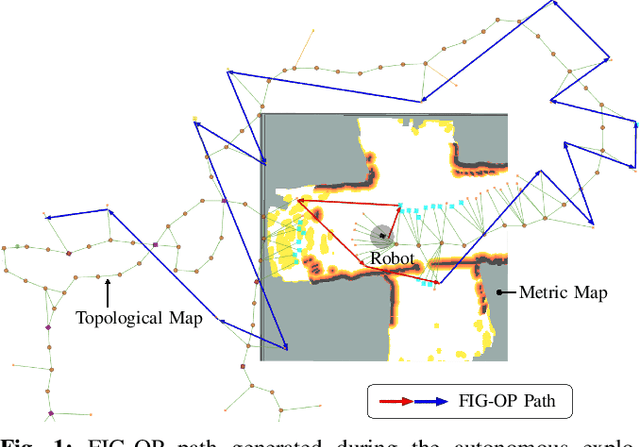
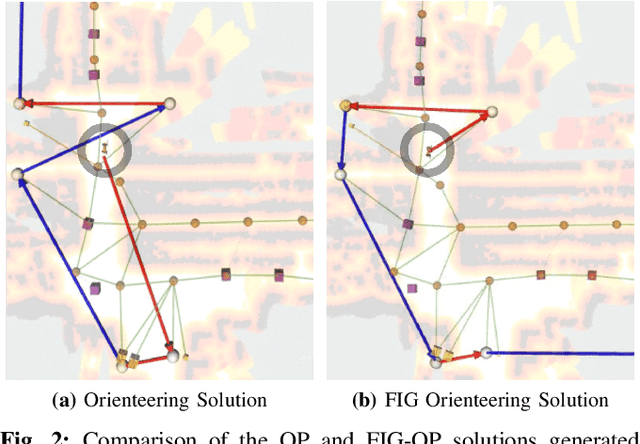
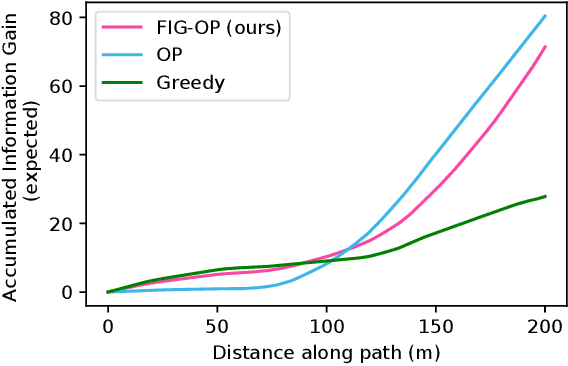
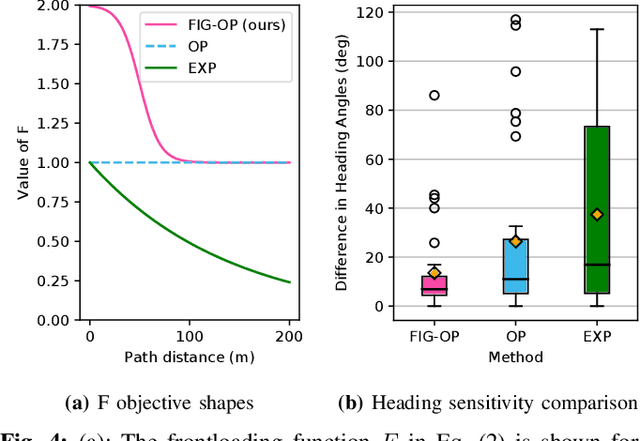
We present a method for autonomous exploration of large-scale unknown environments under mission time constraints. We start by proposing the Frontloaded Information Gain Orienteering Problem (FIG-OP) -- a generalization of the traditional orienteering problem where the assumption of a reliable environmental model no longer holds. The FIG-OP addresses model uncertainty by frontloading expected information gain through the addition of a greedy incentive, effectively expediting the moment in which new area is uncovered. In order to reason across multi-kilometre environments, we solve FIG-OP over an information-efficient world representation, constructed through the aggregation of information from a topological and metric map. Our method was extensively tested and field-hardened across various complex environments, ranging from subway systems to mines. In comparative simulations, we observe that the FIG-OP solution exhibits improved coverage efficiency over solutions generated by greedy and traditional orienteering-based approaches (i.e. severe and minimal model uncertainty assumptions, respectively).
Dojo: A Differentiable Simulator for Robotics
Mar 03, 2022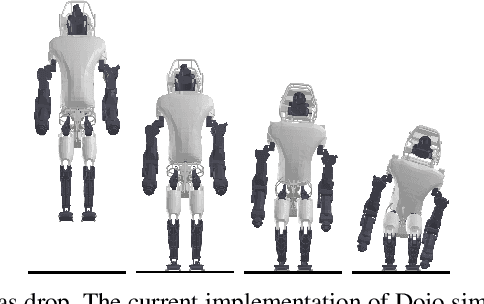
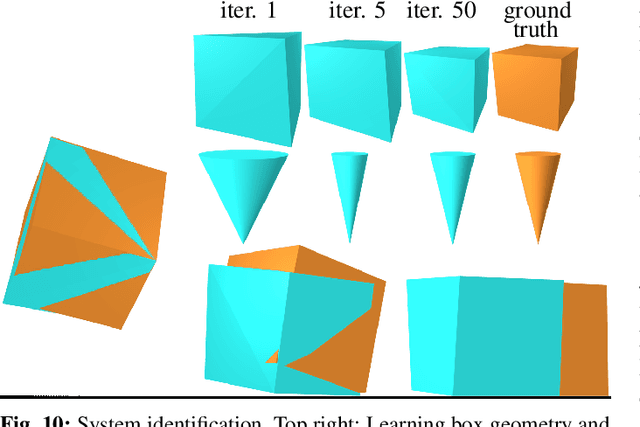
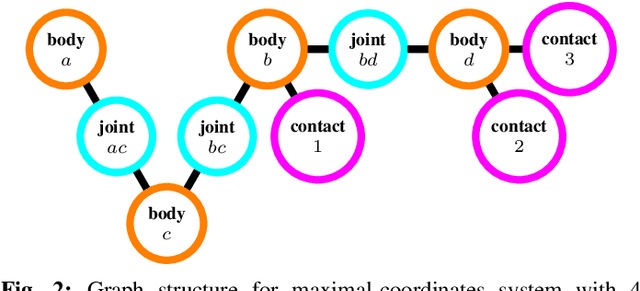

We present a differentiable rigid-body-dynamics simulator for robotics that prioritizes physical accuracy and differentiability: Dojo. The simulator utilizes an expressive maximal-coordinates representation, achieves stable simulation at low sample rates, and conserves energy and momentum by employing a variational integrator. A nonlinear complementarity problem, with nonlinear friction cones, models hard contact and is reliably solved using a custom primal-dual interior-point method. The implicit-function theorem enables efficient differentiation of an intermediate relaxed problem and computes smooth gradients from the contact model. We demonstrate the usefulness of the simulator and its gradients through a number of examples including: simulation, trajectory optimization, reinforcement learning, and system identification.
Maximum-Entropy Multi-Agent Dynamic Games: Forward and Inverse Solutions
Oct 03, 2021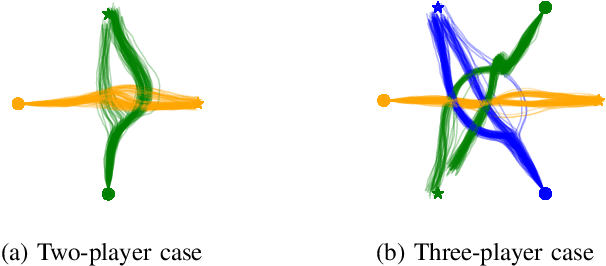
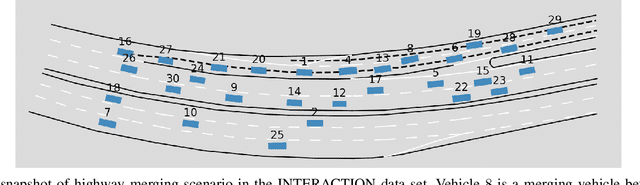
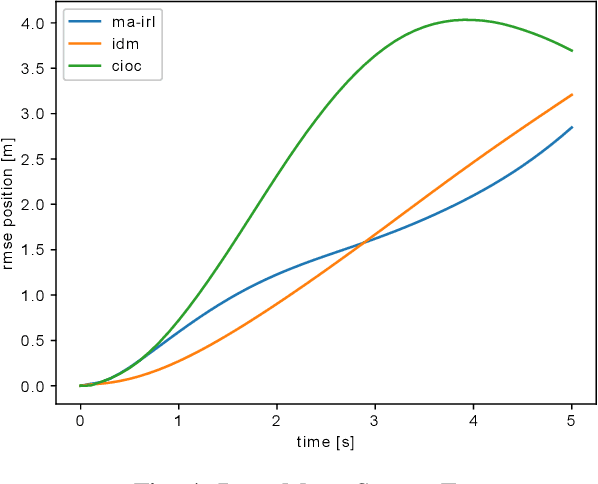
In this paper, we study the problem of multiple stochastic agents interacting in a dynamic game scenario with continuous state and action spaces. We define a new notion of stochastic Nash equilibrium for boundedly rational agents, which we call the Entropic Cost Equilibrium (ECE). We show that ECE is a natural extension to multiple agents of Maximum Entropy optimality for single agents. We solve both the "forward" and "inverse" problems for the multi-agent ECE game. For the forward problem, we provide a Riccati algorithm to compute closed-form ECE feedback policies for the agents, which are exact in the Linear-Quadratic-Gaussian case. We give an iterative variant to find locally ECE feedback policies for the nonlinear case. For the inverse problem, we present an algorithm to infer the cost functions of the multiple interacting agents given noisy, boundedly rational input and state trajectory examples from agents acting in an ECE. The effectiveness of our algorithms is demonstrated in a simulated multi-agent collision avoidance scenario, and with data from the INTERACTION traffic dataset. In both cases, we show that, by taking into account the agents' game theoretic interactions using our algorithm, a more accurate model of agents' costs can be learned, compared with standard inverse optimal control methods.
Vision-Only Robot Navigation in a Neural Radiance World
Oct 01, 2021
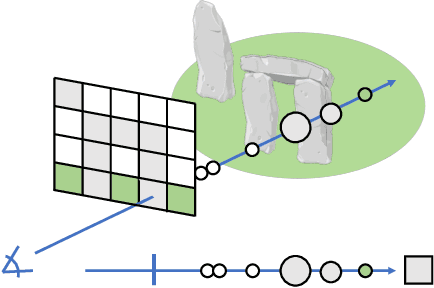
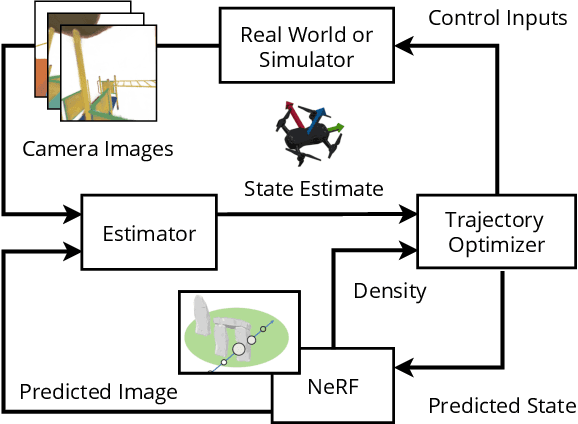
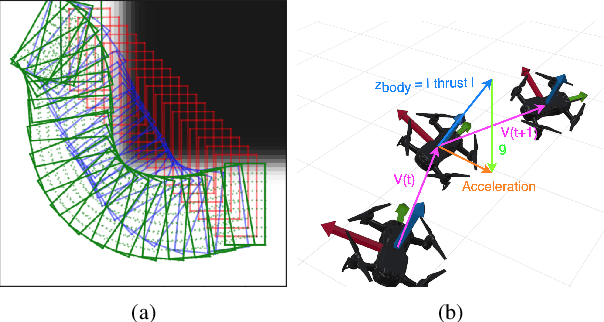
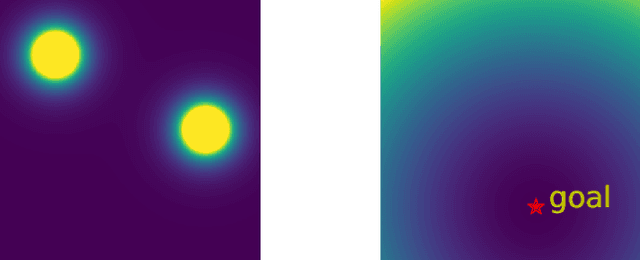
Neural Radiance Fields (NeRFs) have recently emerged as a powerful paradigm for the representation of natural, complex 3D scenes. NeRFs represent continuous volumetric density and RGB values in a neural network, and generate photo-realistic images from unseen camera viewpoints through ray tracing. We propose an algorithm for navigating a robot through a 3D environment represented as a NeRF using only an on-board RGB camera for localization. We assume the NeRF for the scene has been pre-trained offline, and the robot's objective is to navigate through unoccupied space in the NeRF to reach a goal pose. We introduce a trajectory optimization algorithm that avoids collisions with high-density regions in the NeRF based on a discrete time version of differential flatness that is amenable to constraining the robot's full pose and control inputs. We also introduce an optimization based filtering method to estimate 6DoF pose and velocities for the robot in the NeRF given only an onboard RGB camera. We combine the trajectory planner with the pose filter in an online replanning loop to give a vision-based robot navigation pipeline. We present simulation results with a quadrotor robot navigating through a jungle gym environment, the inside of a church, and Stonehenge using only an RGB camera. We also demonstrate an omnidirectional ground robot navigating through the church, requiring it to reorient to fit through the narrow gap. Videos of this work can be found at https://mikh3x4.github.io/nerf-navigation/ .
Decentralized Role Assignment in Multi-Agent Teams via Empirical Game-Theoretic Analysis
Sep 29, 2021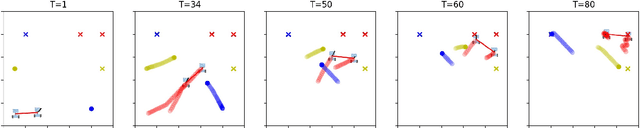
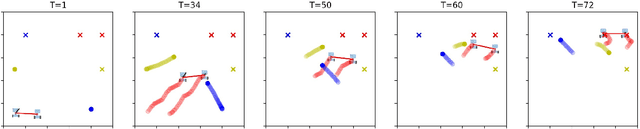
We propose a method, based on empirical game theory, for a robot operating as part of a team to choose its role within the team without explicitly communicating with team members, by leveraging its knowledge about the team structure. To do this, we formulate the role assignment problem as a dynamic game, and borrow tools from empirical game-theoretic analysis to analyze such games. Based on this game-theoretic formulation, we propose a distributed controller for each robot to dynamically decide on the best role to take. We demonstrate our method in simulations of a collaborative planar manipulation scenario in which each agent chooses from a set of feedback control policies at each instant. The agents can effectively collaborate without communication to manipulate the object while also avoiding collisions using our method.
TrajectoTree: Trajectory Optimization Meets Tree Search for Planning Multi-contact Dexterous Manipulation
Sep 28, 2021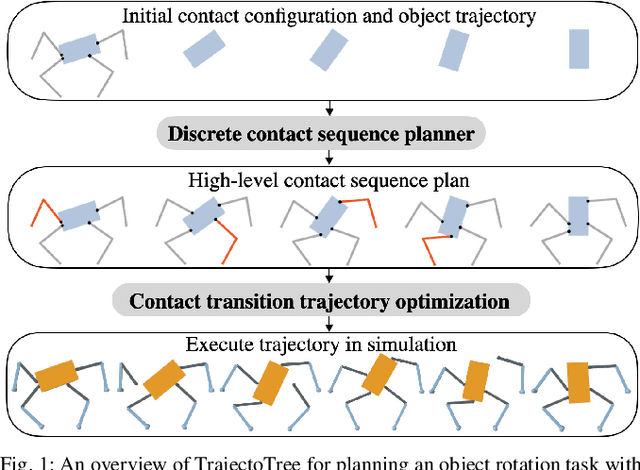
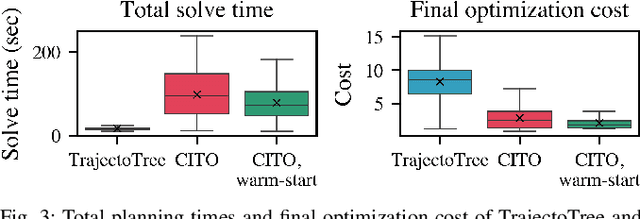

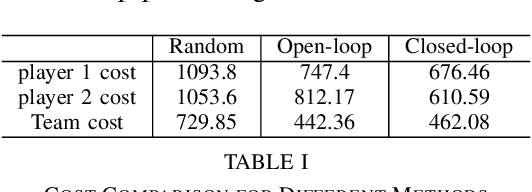
Dexterous manipulation tasks often require contact switching, where fingers make and break contact with the object. We propose a method that plans trajectories for dexterous manipulation tasks involving contact switching using contact-implicit trajectory optimization (CITO) augmented with a high-level discrete contact sequence planner. We first use the high-level planner to find a sequence of finger contact switches given a desired object trajectory. With this contact sequence plan, we impose additional constraints in the CITO problem. We show that our method finds trajectories approximately 7 times faster than a general CITO baseline for a four-finger planar manipulation scenario. Furthermore, when executing the planned trajectories in a full dynamics simulator, we are able to more closely track the object pose trajectories planned by our method than those planned by the baselines.
DiNNO: Distributed Neural Network Optimization for Multi-Robot Collaborative Learning
Sep 17, 2021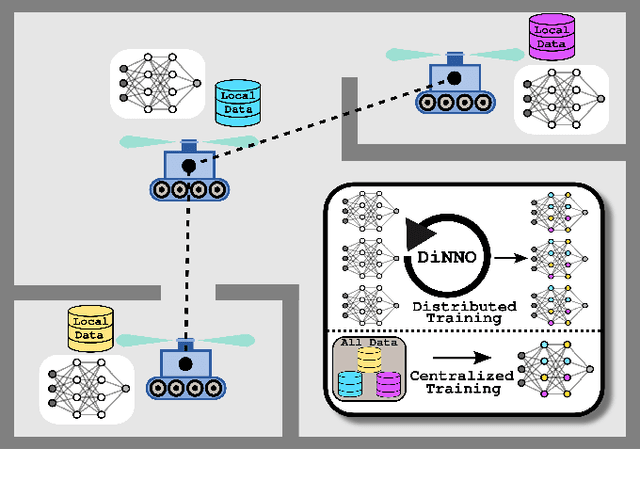
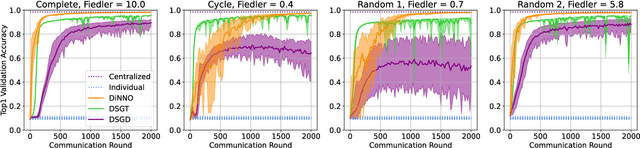
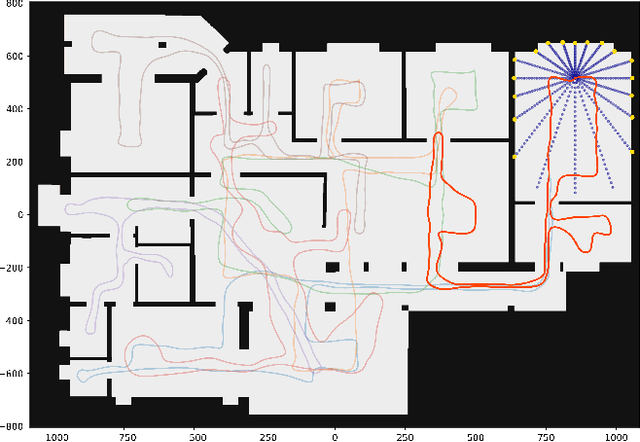
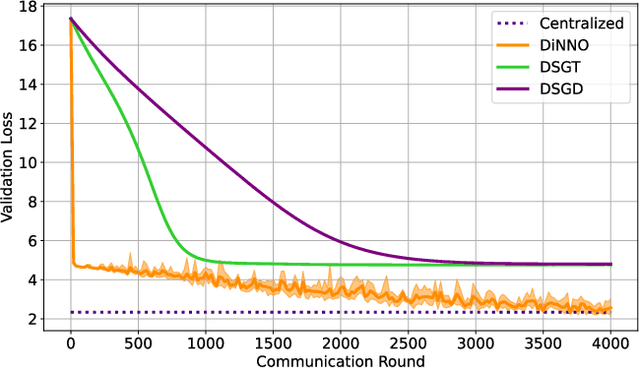
We present a distributed algorithm that enables a group of robots to collaboratively optimize the parameters of a deep neural network model while communicating over a mesh network. Each robot only has access to its own data and maintains its own version of the neural network, but eventually learns a model that is as good as if it had been trained on all the data centrally. No robot sends raw data over the wireless network, preserving data privacy and ensuring efficient use of wireless bandwidth. At each iteration, each robot approximately optimizes an augmented Lagrangian function, then communicates the resulting weights to its neighbors, updates dual variables, and repeats. Eventually, all robots' local network weights reach a consensus. For convex objective functions, we prove this consensus is a global optimum. We compare our algorithm to two existing distributed deep neural network training algorithms in (i) an MNIST image classification task, (ii) a multi-robot implicit mapping task, and (iii) a multi-robot reinforcement learning task. In all of our experiments our method out performed baselines, and was able to achieve validation loss equivalent to centrally trained models. See \href{https://msl.stanford.edu/projects/dist_nn_train}{https://msl.stanford.edu/projects/dist\_nn\_train} for videos and a link to our GitHub repository.
Distributed Control of Truss Robots Using Consensus Alternating Direction Method of Multipliers
Aug 14, 2021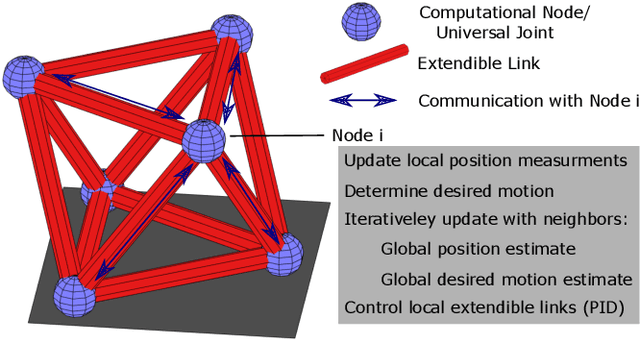
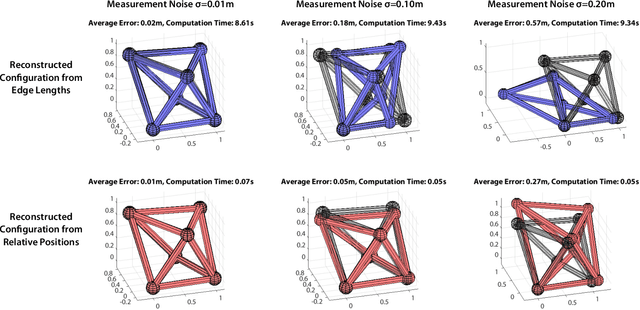
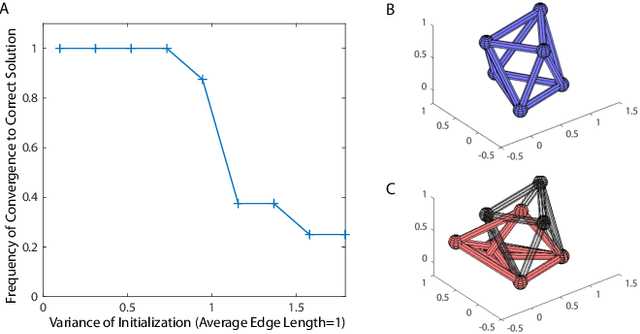
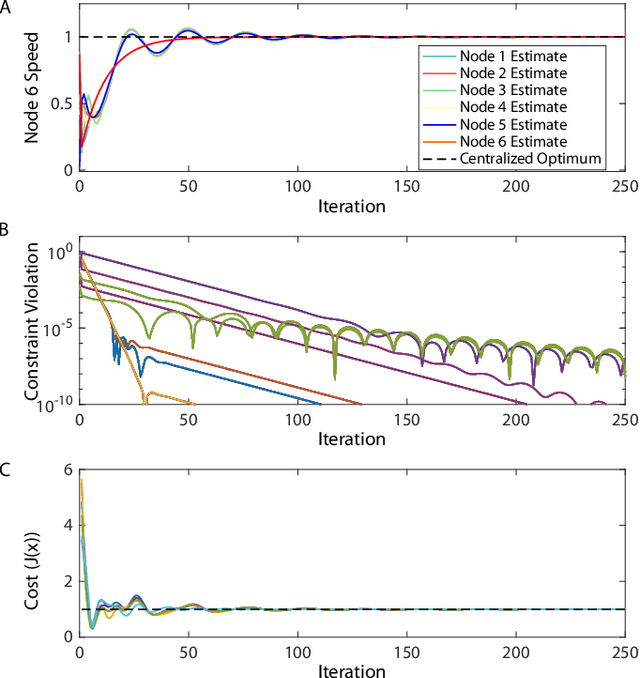
Truss robots, or robots that consist of extensible links connected at universal joints, are often designed with modular physical components but require centralized control techniques. This paper presents a distributed control technique for truss robots. The truss robot is viewed as a collective, where each individual node of the robot is capable of measuring the lengths of the neighboring edges, communicating with a subset of the other nodes, and computing and executing its own control actions with its connected edges. Through an iterative distributed optimization, the individual members utilize local information to converge on a global estimate of the robot's state, and then coordinate their planned motion to achieve desired global behavior. This distributed optimization is based on a consensus alternating direction method of multipliers framework. This distributed algorithm is then adapted to control an isoperimetric truss robot, and the distributed algorithm is used in an experimental demonstration. The demonstration allows a user to broadcast commands to a single node of the robot, which then ensures the coordinated motion of all other nodes to achieve the desired global motion.
Reciprocal Multi-Robot Collision Avoidance with Asymmetric State Uncertainty
Jul 22, 2021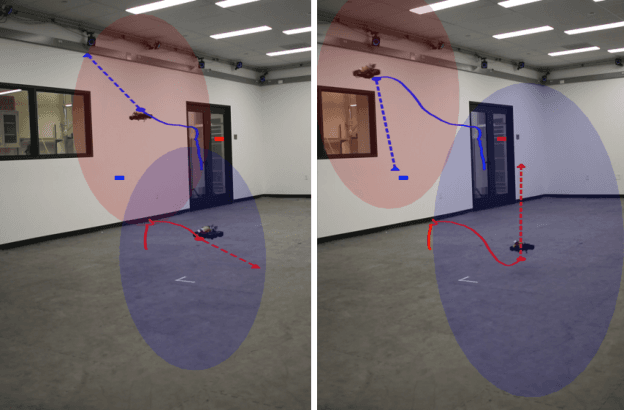
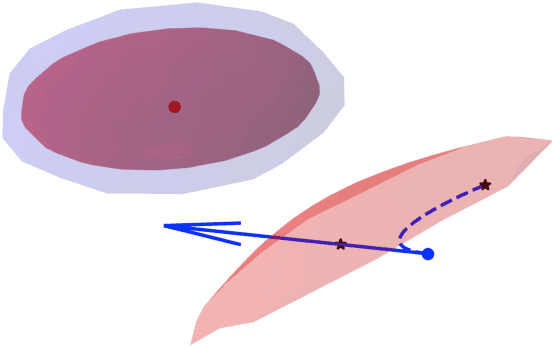
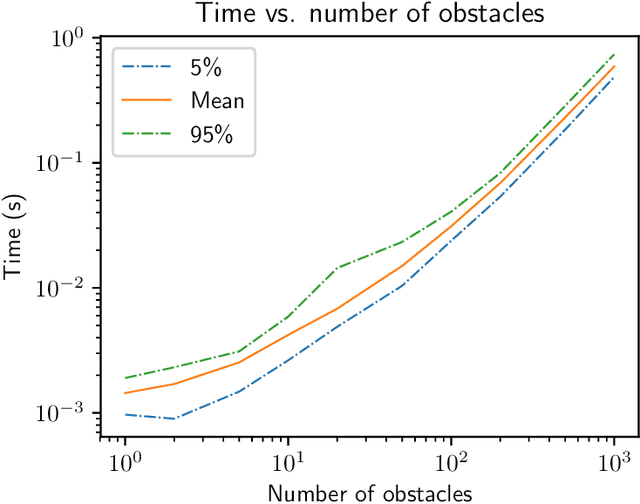
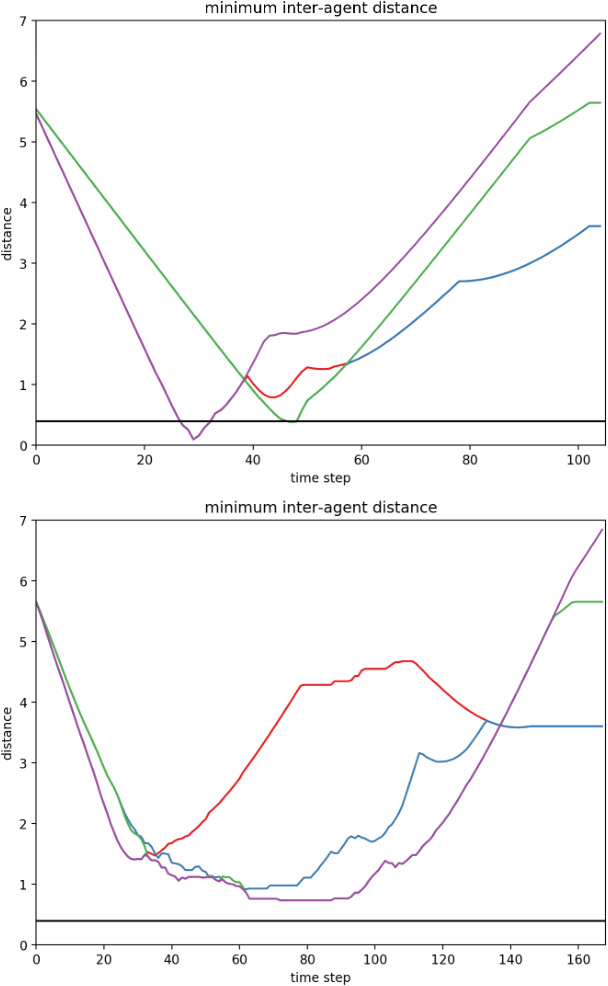
We present a general decentralized formulation for a large class of collision avoidance methods and show that all collision avoidance methods of this form are guaranteed to be collision free. This class includes several existing algorithms in the literature as special cases. We then present a particular instance of this collision avoidance method, CARP (Collision Avoidance by Reciprocal Projections), that is effective even when the estimates of other agents' positions and velocities are noisy. The method's main computational step involves the solution of a small convex optimization problem, which can be quickly solved in practice, even on embedded platforms, making it practical to use on computationally-constrained robots such as quadrotors. This method can be extended to find smooth polynomial trajectories for higher dynamic systems such at quadrotors. We demonstrate this algorithm's performance in simulations and on a team of physical quadrotors. Our method finds optimal projections in a median time of 17.12ms for 285 instances of 100 randomly generated obstacles, and produces safe polynomial trajectories at over 60hz on-board quadrotors. Our paper is accompanied by an open source Julia implementation and ROS package.