 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does LeJEPA Learn a World Model?
May 25, 2026A representation that scrambles the true degrees of freedom of the world cannot support reliable planning or compositional generalization. We prove that LeJEPA (alignment plus Gaussian regularization) linearly recovers the world's latent variables from nonlinear observations, a property known as linear identifiability, in a broad class of worlds where latents evolve under stationary, additive-noise transitions. Our main result is that among all such worlds, the Gaussian is the unique latent distribution for which this guarantee holds. The forward direction rests on a spectral decomposition in which each degree of nonlinearity is strictly penalized by alignment, making the linear map the optimum; the converse rules out every non-Gaussian alternative. We further prove an approximate identifiability result where the guarantee degrades gracefully, and show that linear, orthogonal identifiability enables optimal latent-space planning. We validate the theory with experiments ranging from 2D examples to 1024-dimensional latents, including distributional ablations and pixel-based robotic control. Our theory turns an empirically successful recipe into a mathematical guarantee, providing the foundation for building World Models that provably recover the structure of the world.
Measuring the Representational Alignment of Neural Systems in Superposition
Mar 31, 2026Comparing the internal representations of neural networks is a central goal in both neuroscience and machine learning. Standard alignment metrics operate on raw neural activations, implicitly assuming that similar representations produce similar activity patterns. However, neural systems frequently operate in superposition, encoding more features than they have neurons via linear compression. We derive closed-form expressions showing that superposition systematically deflates Representational Similarity Analysis, Centered Kernel Alignment, and linear regression, causing networks with identical feature content to appear dissimilar. The root cause is that these metrics are dependent on cross-similarity between two systems' respective superposition matrices, which under assumption of random projection usually differ significantly, not on the latent features themselves: alignment scores conflate what a system represents with how it represents it. Under partial feature overlap, this confound can invert the expected ordering, making systems sharing fewer features appear more aligned than systems sharing more. Crucially, the apparent misalignment need not reflect a loss of information; compressed sensing guarantees that the original features remain recoverable from the lower-dimensional activity, provided they are sparse. We therefore argue that comparing neural systems in superposition requires extracting and aligning the underlying features rather than comparing the raw neural mixtures.
Stop Probing, Start Coding: Why Linear Probes and Sparse Autoencoders Fail at Compositional Generalisation
Mar 30, 2026The linear representation hypothesis states that neural network activations encode high-level concepts as linear mixtures. However, under superposition, this encoding is a projection from a higher-dimensional concept space into a lower-dimensional activation space, and a linear decision boundary in the concept space need not remain linear after projection. In this setting, classical sparse coding methods with per-sample iterative inference leverage compressed sensing guarantees to recover latent factors. Sparse autoencoders (SAEs), on the other hand, amortise sparse inference into a fixed encoder, introducing a systematic gap. We show this amortisation gap persists across training set sizes, latent dimensions, and sparsity levels, causing SAEs to fail under out-of-distribution (OOD) compositional shifts. Through controlled experiments that decompose the failure, we identify dictionary learning -- not the inference procedure -- as the binding constraint: SAE-learned dictionaries point in substantially wrong directions, and replacing the encoder with per-sample FISTA on the same dictionary does not close the gap. An oracle baseline proves the problem is solvable with a good dictionary at all scales tested. Our results reframe the SAE failure as a dictionary learning challenge, not an amortisation problem, and point to scalable dictionary learning as the key open problem for sparse inference under superposition.
FederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
Mar 17, 2026Federated Learning (FL) enables distributed optimization without compromising data sovereignty. Yet, where local label distributions are mutually exclusive, standard weight aggregation fails due to conflicting optimization trajectories. Often, FL methods rely on pretrained foundation models, introducing unrealistic assumptions. We introduce FederatedFactory, a zero-dependency framework that inverts the unit of federation from discriminative parameters to generative priors. By exchanging generative modules in a single communication round, our architecture supports ex nihilo synthesis of universally class balanced datasets, eliminating gradient conflict and external prior bias entirely. Evaluations across diverse medical imagery benchmarks, including MedMNIST and ISIC2019, demonstrate that our approach recovers centralized upper-bound performance. Under pathological heterogeneity, it lifts baseline accuracy from a collapsed 11.36% to 90.57% on CIFAR-10 and restores ISIC2019 AUROC to 90.57%. Additionally, this framework facilitates exact modular unlearning through the deterministic deletion of specific generative modules.
Causality is Key for Interpretability Claims to Generalise
Feb 18, 2026Interpretability research on large language models (LLMs) has yielded important insights into model behaviour, yet recurring pitfalls persist: findings that do not generalise, and causal interpretations that outrun the evidence. Our position is that causal inference specifies what constitutes a valid mapping from model activations to invariant high-level structures, the data or assumptions needed to achieve it, and the inferences it can support. Specifically, Pearl's causal hierarchy clarifies what an interpretability study can justify. Observations establish associations between model behaviour and internal components. Interventions (e.g., ablations or activation patching) support claims how these edits affect a behavioural metric (\eg, average change in token probabilities) over a set of prompts. However, counterfactual claims -- i.e., asking what the model output would have been for the same prompt under an unobserved intervention -- remain largely unverifiable without controlled supervision. We show how causal representation learning (CRL) operationalises this hierarchy, specifying which variables are recoverable from activations and under what assumptions. Together, these motivate a diagnostic framework that helps practitioners select methods and evaluations matching claims to evidence such that findings generalise.
The Observer Effect in World Models: Invasive Adaptation Corrupts Latent Physics
Feb 12, 2026Determining whether neural models internalize physical laws as world models, rather than exploiting statistical shortcuts, remains challenging, especially under out-of-distribution (OOD) shifts. Standard evaluations often test latent capability via downstream adaptation (e.g., fine-tuning or high-capacity probes), but such interventions can change the representations being measured and thus confound what was learned during self-supervised learning (SSL). We propose a non-invasive evaluation protocol, PhyIP. We test whether physical quantities are linearly decodable from frozen representations, motivated by the linear representation hypothesis. Across fluid dynamics and orbital mechanics, we find that when SSL achieves low error, latent structure becomes linearly accessible. PhyIP recovers internal energy and Newtonian inverse-square scaling on OOD tests (e.g., $ρ> 0.90$). In contrast, adaptation-based evaluations can collapse this structure ($ρ\approx 0.05$). These findings suggest that adaptation-based evaluation can obscure latent structures and that low-capacity probes offer a more accurate evaluation of physical world models.
Data Whitening Improves Sparse Autoencoder Learning
Nov 17, 2025Sparse autoencoders (SAEs) have emerged as a promising approach for learning interpretable features from neural network activations. However, the optimization landscape for SAE training can be challenging due to correlations in the input data. We demonstrate that applying PCA Whitening to input activations -- a standard preprocessing technique in classical sparse coding -- improves SAE performance across multiple metrics. Through theoretical analysis and simulation, we show that whitening transforms the optimization landscape, making it more convex and easier to navigate. We evaluate both ReLU and Top-K SAEs across diverse model architectures, widths, and sparsity regimes. Empirical evaluation on SAEBench, a comprehensive benchmark for sparse autoencoders, reveals that whitening consistently improves interpretability metrics, including sparse probing accuracy and feature disentanglement, despite minor drops in reconstruction quality. Our results challenge the assumption that interpretability aligns with an optimal sparsity--fidelity trade-off and suggest that whitening should be considered as a default preprocessing step for SAE training, particularly when interpretability is prioritized over perfect reconstruction.
An Empirically Grounded Identifiability Theory Will Accelerate Self-Supervised Learning Research
Apr 17, 2025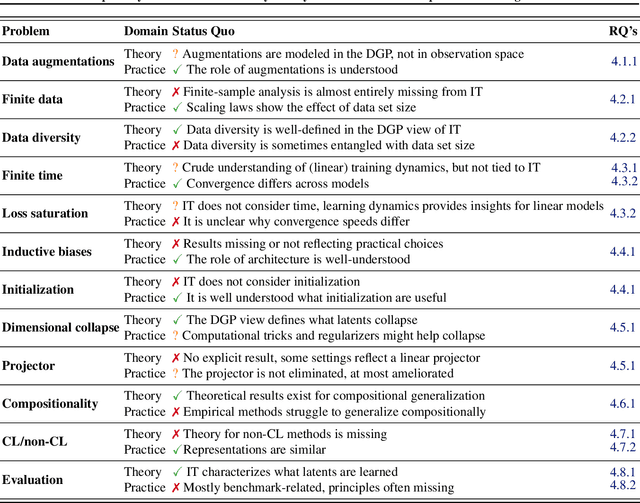
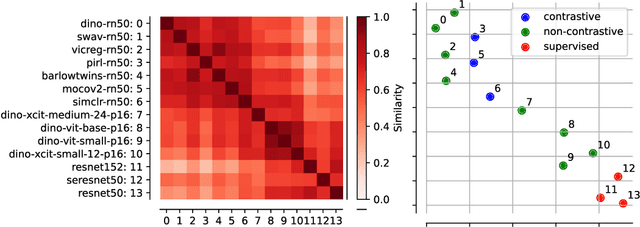
Self-Supervised Learning (SSL) powers many current AI systems. As research interest and investment grow, the SSL design space continues to expand. The Platonic view of SSL, following the Platonic Representation Hypothesis (PRH), suggests that despite different methods and engineering approaches, all representations converge to the same Platonic ideal. However, this phenomenon lacks precise theoretical explanation. By synthesizing evidence from Identifiability Theory (IT), we show that the PRH can emerge in SSL. However, current IT cannot explain SSL's empirical success. To bridge the gap between theory and practice, we propose expanding IT into what we term Singular Identifiability Theory (SITh), a broader theoretical framework encompassing the entire SSL pipeline. SITh would allow deeper insights into the implicit data assumptions in SSL and advance the field towards learning more interpretable and generalizable representations. We highlight three critical directions for future research: 1) training dynamics and convergence properties of SSL; 2) the impact of finite samples, batch size, and data diversity; and 3) the role of inductive biases in architecture, augmentations, initialization schemes, and optimizers.
From superposition to sparse codes: interpretable representations in neural networks
Mar 03, 2025Understanding how information is represented in neural networks is a fundamental challenge in both neuroscience and artificial intelligence. Despite their nonlinear architectures, recent evidence suggests that neural networks encode features in superposition, meaning that input concepts are linearly overlaid within the network's representations. We present a perspective that explains this phenomenon and provides a foundation for extracting interpretable representations from neural activations. Our theoretical framework consists of three steps: (1) Identifiability theory shows that neural networks trained for classification recover latent features up to a linear transformation. (2) Sparse coding methods can extract disentangled features from these representations by leveraging principles from compressed sensing. (3) Quantitative interpretability metrics provide a means to assess the success of these methods, ensuring that extracted features align with human-interpretable concepts. By bridging insights from theoretical neuroscience, representation learning, and interpretability research, we propose an emerging perspective on understanding neural representations in both artificial and biological systems. Our arguments have implications for neural coding theories, AI transparency, and the broader goal of making deep learning models more interpretable.
Compute Optimal Inference and Provable Amortisation Gap in Sparse Autoencoders
Nov 20, 2024



A recent line of work has shown promise in using sparse autoencoders (SAEs) to uncover interpretable features in neural network representations. However, the simple linear-nonlinear encoding mechanism in SAEs limits their ability to perform accurate sparse inference. In this paper, we investigate sparse inference and learning in SAEs through the lens of sparse coding. Specifically, we show that SAEs perform amortised sparse inference with a computationally restricted encoder and, using compressed sensing theory, we prove that this mapping is inherently insufficient for accurate sparse inference, even in solvable cases. Building on this theory, we empirically explore conditions where more sophisticated sparse inference methods outperform traditional SAE encoders. Our key contribution is the decoupling of the encoding and decoding processes, which allows for a comparison of various sparse encoding strategies. We evaluate these strategies on two dimensions: alignment with true underlying sparse features and correct inference of sparse codes, while also accounting for computational costs during training and inference. Our results reveal that substantial performance gains can be achieved with minimal increases in compute cost. We demonstrate that this generalises to SAEs applied to large language models (LLMs), where advanced encoders achieve similar interpretability. This work opens new avenues for understanding neural network representations and offers important implications for improving the tools we use to analyse the activations of large language models.