 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriFinger: An Open-Source Robot for Learning Dexterity
Aug 08, 2020



Dexterous object manipulation remains an open problem in robotics, despite the rapid progress in machine learning during the past decade. We argue that a hindrance is the high cost of experimentation on real systems, in terms of both time and money. We address this problem by proposing an open-source robotic platform which can safely operate without human supervision. The hardware is inexpensive (about \SI{5000}[\$]{}) yet highly dynamic, robust, and capable of complex interaction with external objects. The software operates at 1-kilohertz and performs safety checks to prevent the hardware from breaking. The easy-to-use front-end (in C++ and Python) is suitable for real-time control as well as deep reinforcement learning. In addition, the software framework is largely robot-agnostic and can hence be used independently of the hardware proposed herein. Finally, we illustrate the potential of the proposed platform through a number of experiments, including real-time optimal control, deep reinforcement learning from scratch, throwing, and writing.
Stochastic and Robust MPC for Bipedal Locomotion: A Comparative Study on Robustness and Performance
May 15, 2020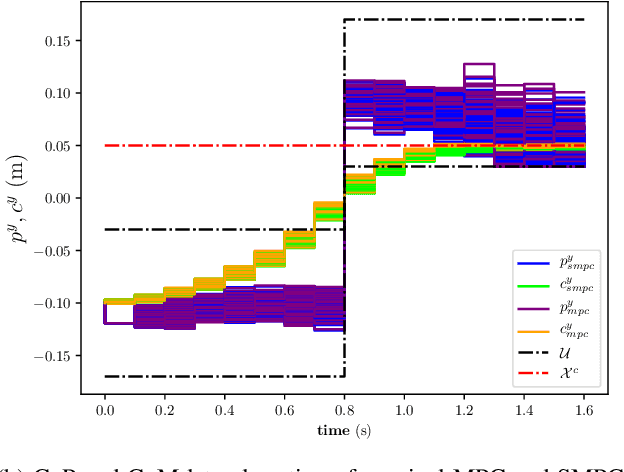
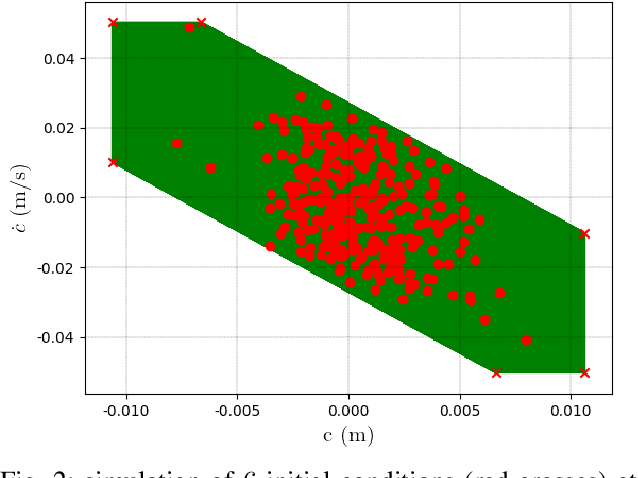
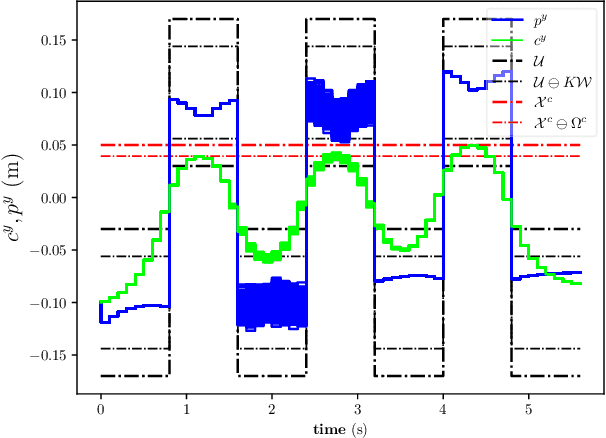
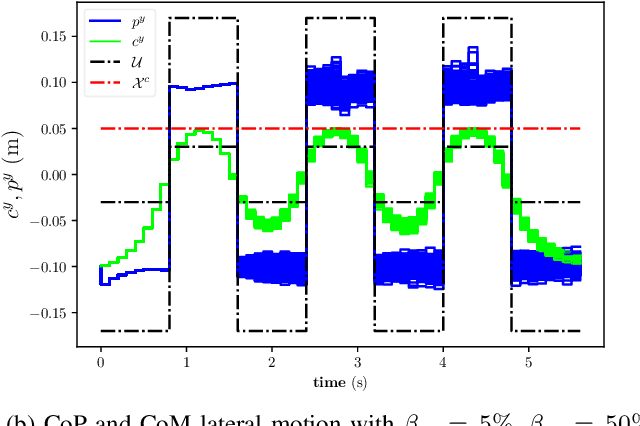
Linear Model Predictive Control (MPC) has been successfully used for generating feasible walking motions for humanoid robots. However, the effect of uncertainties on constraints satisfaction has only been studied using Robust MPC (RMPC) approaches, which account for the worst-case realization of bounded disturbances at each time instant. In this letter, we propose for the first time to use linear stochastic MPC (SMPC) to account for uncertainties in bipedal walking. We show that SMPC offers more flexibility to the user (or a high level decision maker) by tolerating small (user-defined) probabilities of constraint violation. Therefore, SMPC can be tuned to achieve a constraint satisfaction probability that is arbitrarily close to 100\%, but without sacrificing performance as much as tube-based RMPC. We compare SMPC against RMPC in terms of robustness (constraint satisfaction) and performance (optimality). Our results highlight the benefits of SMPC and its interest for the robotics community as a powerful mathematical tool for dealing with uncertainties.
An Open Torque-Controlled Modular Robot Architecture for Legged Locomotion Research
Sep 30, 2019

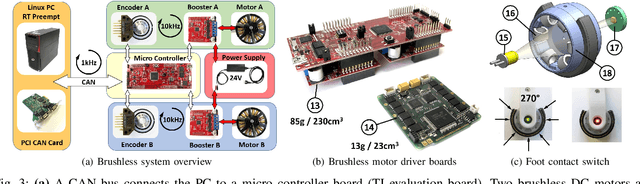
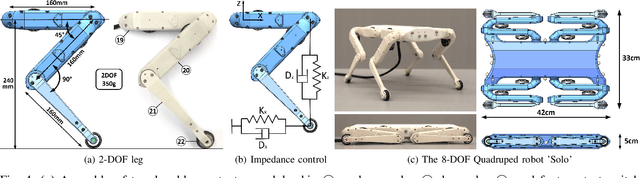
We present a new open-source torque-controlled legged robot system, with a low cost and low complexity actuator module at its core. It consists of a low-weight high torque brushless DC motor and a low gear ratio transmission suitable for impedance and force control. We also present a novel foot contact sensor suitable for legged locomotion with hard impacts. A 2.2 kg quadruped robot with a large range of motion is assembled from 8 identical actuator modules and 4 lower legs with foot contact sensors. To the best of our knowledge, it is the most lightest force-controlled quadruped robot. We leverage standard plastic 3D printing and off-the-shelf parts, resulting in light-weight and inexpensive robots, allowing for rapid distribution and duplication within the research community. In order to quantify the capabilities of our design, we systematically measure the achieved impedance at the foot in static and dynamic scenarios. We measured up to 10.8 dimensionless leg stiffness without active damping, which is comparable to the leg stiffness of a running human. Finally, in order to demonstrate the capabilities of our quadruped robot, we propose a novel controller which combines feedforward contact forces computed from a kino-dynamic optimizer with impedance control of the robot center of mass and base orientation. The controller is capable of regulating complex motions which are robust to environmental uncertainty.
Robust Humanoid Contact Planning with Learned Zero- and One-Step Capturability Prediction
Sep 19, 2019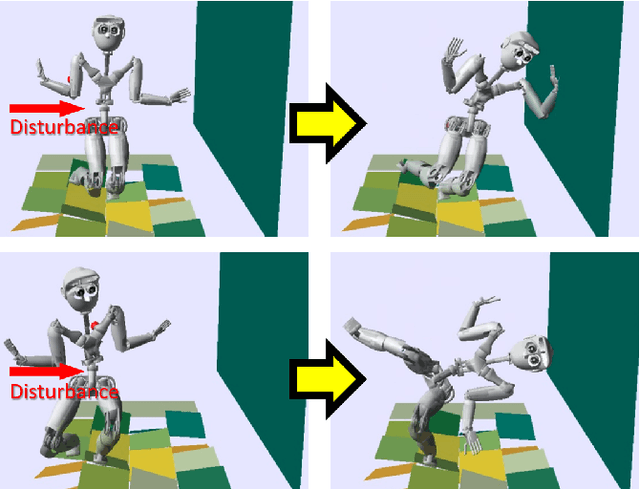
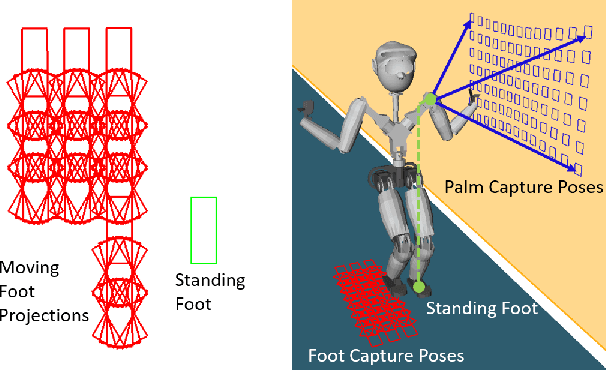
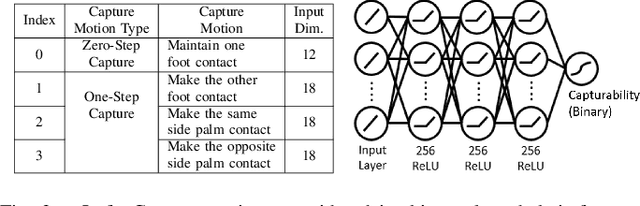
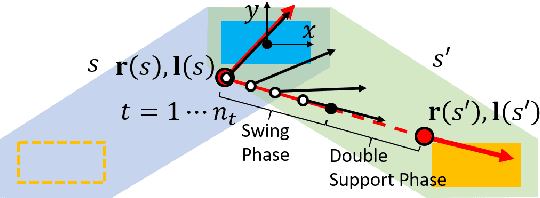
Humanoid robots maintain balance and navigate by controlling the contact wrenches applied to the environment. While it is possible to plan dynamically-feasible motion that applies appropriate wrenches using existing methods, a humanoid may also be affected by external disturbances. Existing systems typically rely on controllers to reactively recover from disturbances. However, such controllers may fail when the robot cannot reach contacts capable of rejecting a given disturbance. In this paper, we propose a search-based footstep planner which aims to maximize the probability of the robot successfully reaching the goal without falling under disturbances. The planner considers not only the poses of the planned contact sequence, but also alternative contacts near the planned contact sequence that can be used to recover from external disturbances. Although this additional consideration significantly increases the computation load, we train neural networks to efficiently predict multi-contact zero-step and one-step capturability, which allows the planner to generate robust contact sequences efficiently. Our results show that our approach generates footstep sequences that are more robust to external disturbances than a conventional footstep planner in four challenging scenarios.
Learning to Explore in Motion and Interaction Tasks
Aug 10, 2019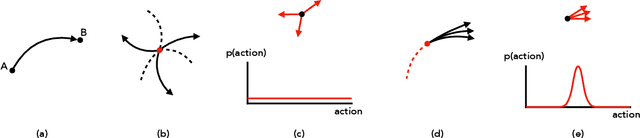
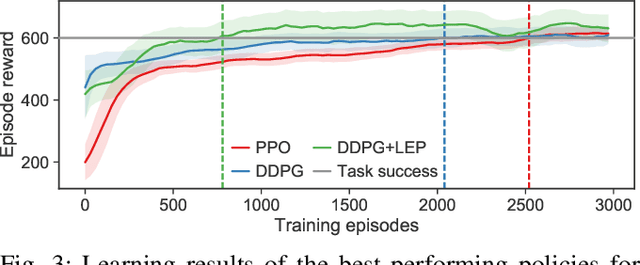
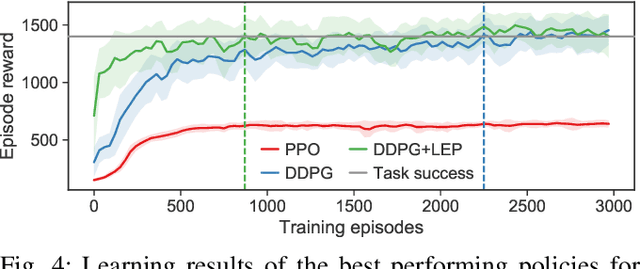
Model free reinforcement learning suffers from the high sampling complexity inherent to robotic manipulation or locomotion tasks. Most successful approaches typically use random sampling strategies which leads to slow policy convergence. In this paper we present a novel approach for efficient exploration that leverages previously learned tasks. We exploit the fact that the same system is used across many tasks and build a generative model for exploration based on data from previously solved tasks to improve learning new tasks. The approach also enables continuous learning of improved exploration strategies as novel tasks are learned. Extensive simulations on a robot manipulator performing a variety of motion and contact interaction tasks demonstrate the capabilities of the approach. In particular, our experiments suggest that the exploration strategy can more than double learning speed, especially when rewards are sparse. Moreover, the algorithm is robust to task variations and parameter tuning, making it beneficial for complex robotic problems.
Learning Variable Impedance Control for Contact Sensitive Tasks
Jul 17, 2019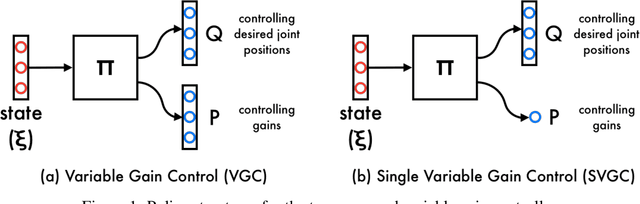

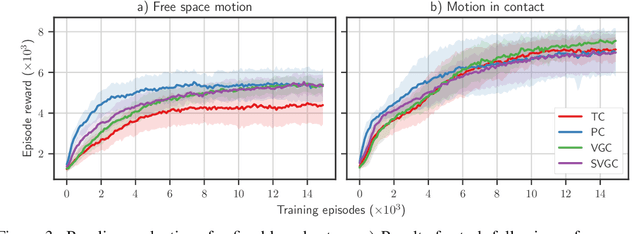
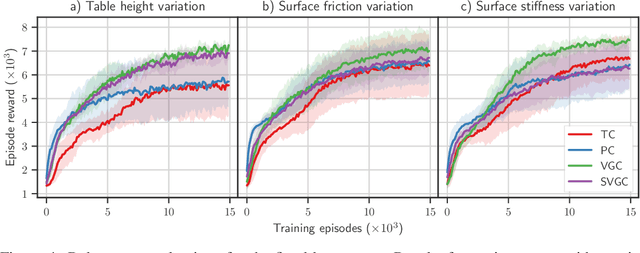
Reinforcement learning algorithms have shown great success in solving different problems ranging from playing video games to robotics. However, they struggle to solve delicate robotic problems, especially those involving contact interactions. Though in principle a policy outputting joint torques should be able to learn these tasks, in practice we see that they have difficulty to robustly solve the problem without any structure in the action space. In this paper, we investigate how the choice of action space can give robust performance in presence of contact uncertainties. We propose to learn a policy that outputs impedance and desired position in joint space as a function of system states without imposing any other structure to the problem. We compare the performance of this approach to torque and position control policies under different contact uncertainties. Extensive simulation results on two different systems, a hopper (floating-base) with intermittent contacts and a manipulator (fixed-base) wiping a table, show that our proposed approach outperforms policies outputting torque or position in terms of both learning rate and robustness to environment uncertainty.
Robust Humanoid Locomotion Using Trajectory Optimization and Sample-Efficient Learning
Jul 10, 2019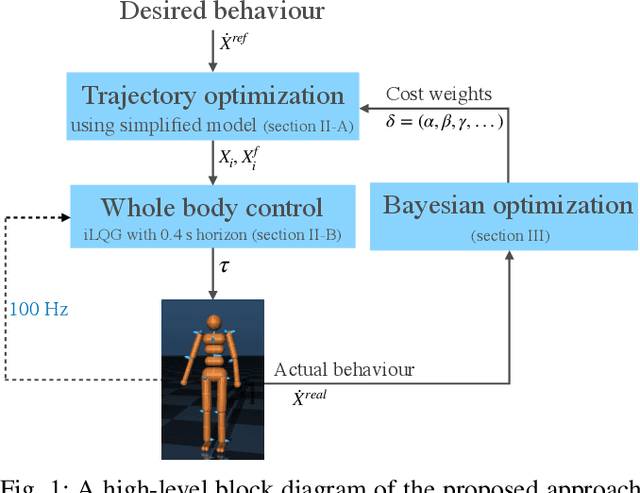

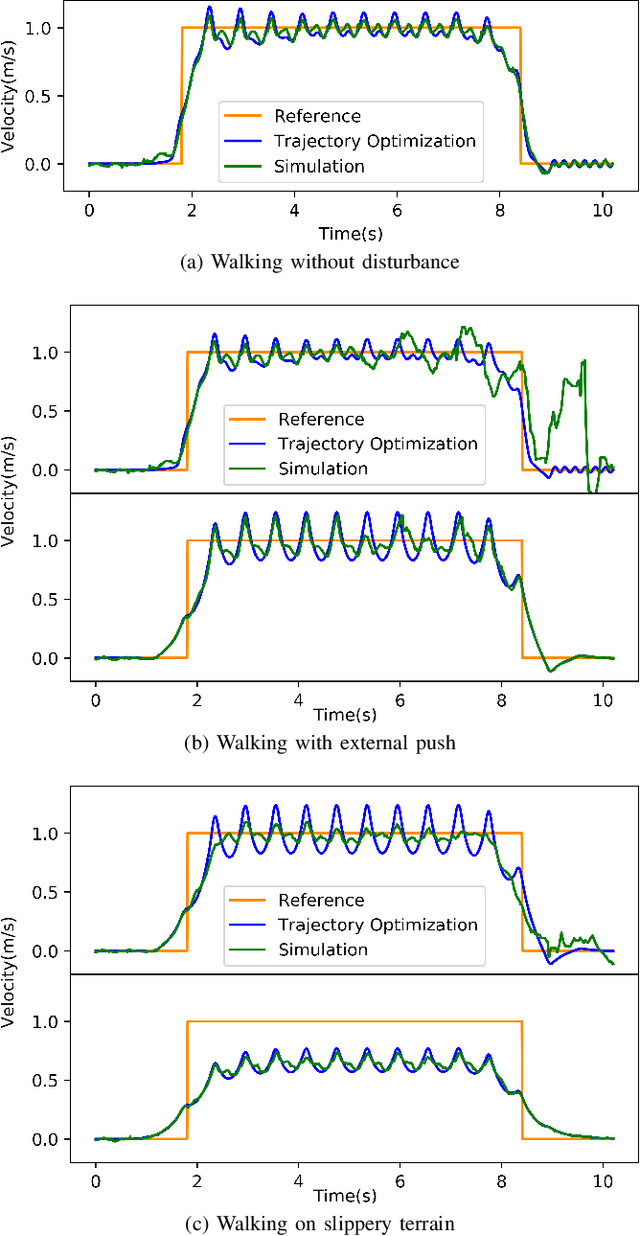
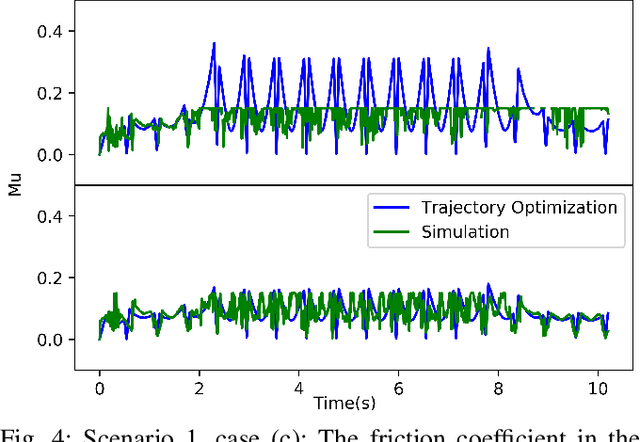
Trajectory optimization (TO) is one of the most powerful tools for generating feasible motions for humanoid robots. However, including uncertainties and stochasticity in the TO problem to generate robust motions can easily lead to intractable problems. Furthermore, since the models used in TO have always some level of abstraction, it can be hard to find a realistic set of uncertainties in the model space. In this paper we leverage a sample-efficient learning technique (Bayesian optimization) to robustify TO for humanoid locomotion. The main idea is to use data from full-body simulations to make the TO stage robust by tuning the cost weights. To this end, we split the TO problem into two phases. The first phase solves a convex optimization problem for generating center of mass (CoM) trajectories based on simplified linear dynamics. The second stage employs iterative Linear-Quadratic Gaussian (iLQG) as a whole-body controller to generate full body control inputs. Then we use Bayesian optimization to find the cost weights to use in the first stage that yields robust performance in the simulation/experiment, in the presence of different disturbance/uncertainties. The results show that the proposed approach is able to generate robust motions for different sets of disturbances and uncertainties.
Meta-Learning via Learned Loss
Jun 12, 2019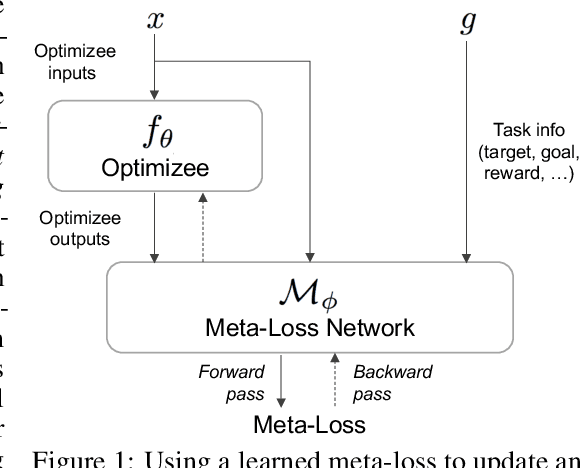
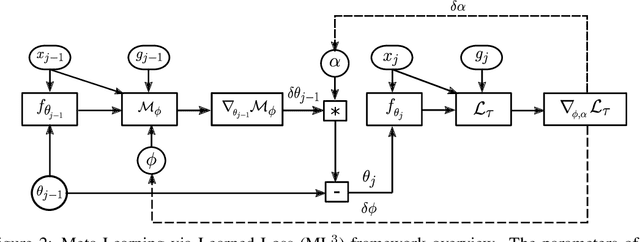
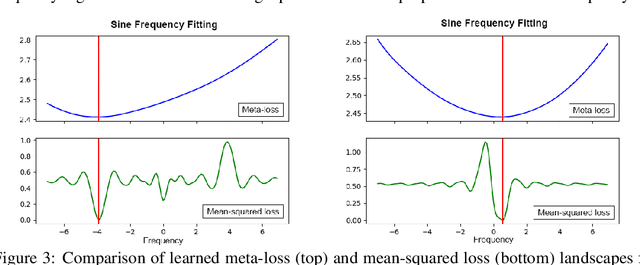
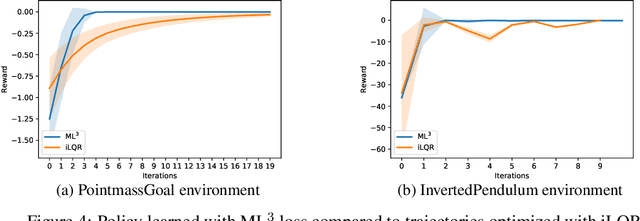
We present a meta-learning approach based on learning an adaptive, high-dimensional loss function that can generalize across multiple tasks and different model architectures. We develop a fully differentiable pipeline for learning a loss function targeted at maximizing the performance of an optimizee trained using this loss function. We observe that the loss landscape produced by our learned loss significantly improves upon the original task-specific loss. We evaluate our method on supervised and reinforcement learning tasks. Furthermore, we show that our pipeline is able to operate in sparse reward and self-supervised reinforcement learning scenarios.
Trajectory Optimization for Robust Humanoid Locomotion with Sample-Efficient Learning
Jun 09, 2019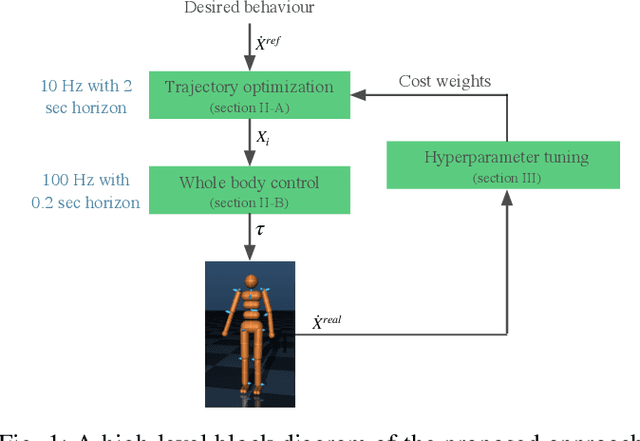

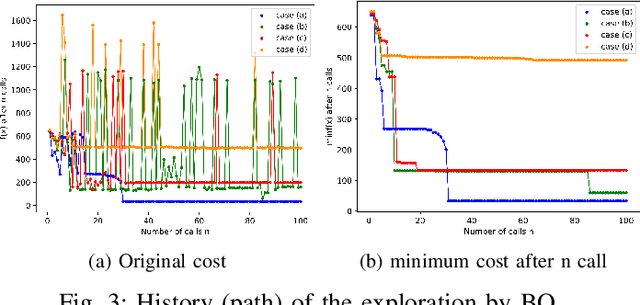
Trajectory optimization (TO) is one of the most powerful tools for generating feasible motions for humanoid robots. However, including uncertainties and stochasticity in the TO problem to generate robust motions can easily lead to an interactable problem. Furthermore, since the models used in the TO have always some level of abstraction, it is hard to find a realistic set of uncertainty in the space of abstract model. In this paper we aim at leveraging a sample-efficient learning technique (Bayesian optimization) to robustify trajectory optimization for humanoid locomotion. The main idea is to use Bayesian optimization to find the optimal set of cost weights which compromises performance with respect to robustness with a few realistic simulation/experiment. The results show that the proposed approach is able to generate robust motions for different set of disturbances and uncertainties.
Curious iLQR: Resolving Uncertainty in Model-based RL
Apr 15, 2019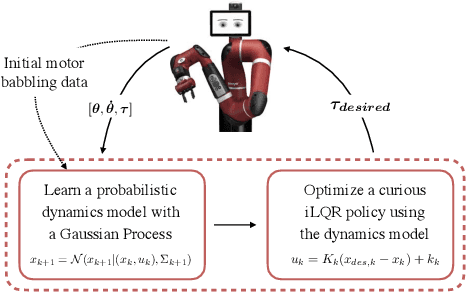
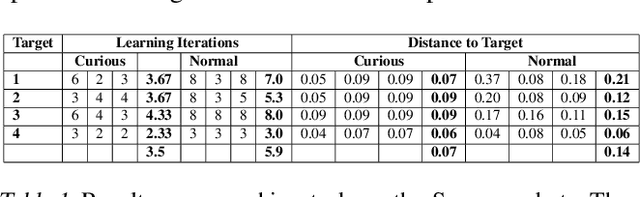
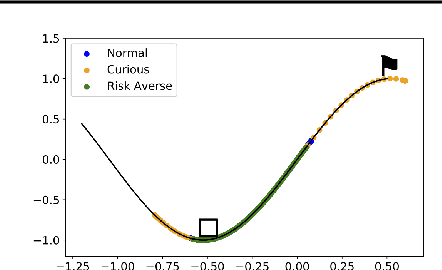
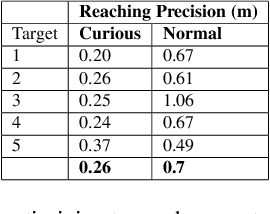
Curiosity as a means to explore during reinforcement learning problems has recently become very popular. However, very little progress has been made in utilizing curiosity for learning control. In this work, we propose a model-based reinforcement learning (MBRL) framework that combines Bayesian modeling of the system dynamics with curious iLQR, a risk-seeking iterative LQR approach. During trajectory optimization the curious iLQR attempts to minimize both the task-dependent cost and the uncertainty in the dynamics model. We scale this approach to perform reaching tasks on 7-DoF manipulators, to perform both simulation and real robot reaching experiments. Our experiments consistently show that MBRL with curious iLQR more easily overcomes bad initial dynamics models and reaches desired joint configurations more reliably and with less system rollouts.