 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Asymmetric Optimization of Reasoning and Perception in Vision-Language Model Post-Training
May 28, 2026Post-training has greatly improved reasoning in frontier vision-language models, yet its gains for perception remain comparatively limited, creating a bottleneck for end-to-end visual reasoning. To investigate this gap, we introduce a controlled diagnostic framework with two synthetic tasks that disentangle perception from reasoning. Our analysis reveals a consistent perception-reasoning asymmetry: posttraining improves reasoning more substantially than perception, though the underlying mechanism differs by training paradigm. For supervised fine-tuning (SFT), this asymmetry stems from token imbalance in chain-of-thought supervision, where perception occupies fewer tokens and thus receives a weaker training signal. Dynamically reweighting the loss mitigates this imbalance and boosts end-to-end performance by up to 18.2. For reinforcement learning (RL), the asymmetry instead arises from reward coupling: outcome rewards correlate more strongly with reasoning than with perception, weakening the signal for perception learning. Adding a perception-aware reward alleviates the imbalance and improves end-to-end accuracy by up to 6.0; even without groundtruth perception rewards, a reliable surrogate reward provide useful signal, yielding gains of 3.2 points. Together, our results comprehensively diagnose asymmetric optimization and suggest concrete interventions to balance perception and reasoning.
Learning to Select Visual In-Context Demonstrations
Mar 24, 2026Multimodal Large Language Models (MLLMs) adapt to visual tasks via in-context learning (ICL), which relies heavily on demonstration quality. The dominant demonstration selection strategy is unsupervised k-Nearest Neighbor (kNN) search. While simple, this similarity-first approach is sub-optimal for complex factual regression tasks; it selects redundant examples that fail to capture the task's full output range. We reframe selection as a sequential decision-making problem and introduce Learning to Select Demonstrations (LSD), training a Reinforcement Learning agent to construct optimal demonstration sets. Using a Dueling DQN with a query-centric Transformer Decoder, our agent learns a policy that maximizes MLLM downstream performance. Evaluating across five visual regression benchmarks, we uncover a crucial dichotomy: while kNN remains optimal for subjective preference tasks, LSD significantly outperforms baselines on objective, factual regression tasks. By balancing visual relevance with diversity, LSD better defines regression boundaries, illuminating when learned selection is strictly necessary for visual ICL.
Robust Humanoid Contact Planning with Learned Zero- and One-Step Capturability Prediction
Sep 19, 2019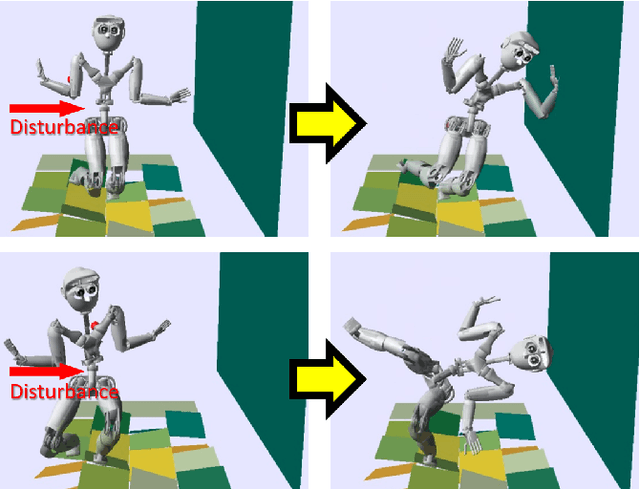
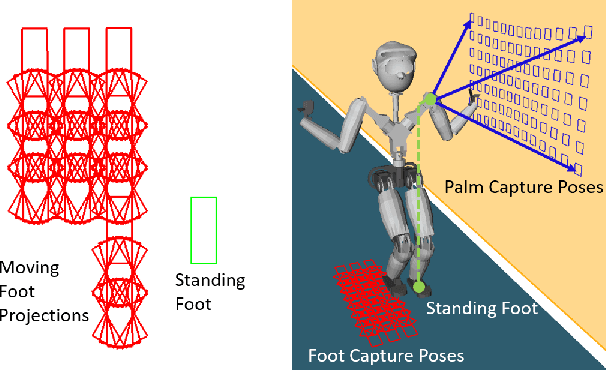
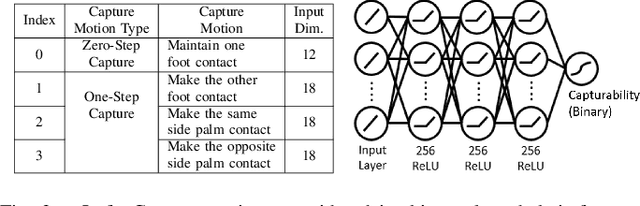
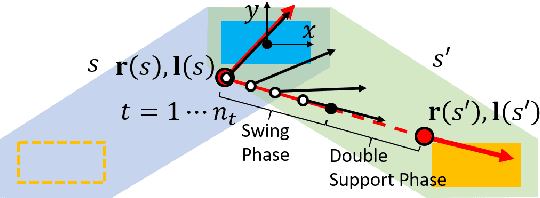
Humanoid robots maintain balance and navigate by controlling the contact wrenches applied to the environment. While it is possible to plan dynamically-feasible motion that applies appropriate wrenches using existing methods, a humanoid may also be affected by external disturbances. Existing systems typically rely on controllers to reactively recover from disturbances. However, such controllers may fail when the robot cannot reach contacts capable of rejecting a given disturbance. In this paper, we propose a search-based footstep planner which aims to maximize the probability of the robot successfully reaching the goal without falling under disturbances. The planner considers not only the poses of the planned contact sequence, but also alternative contacts near the planned contact sequence that can be used to recover from external disturbances. Although this additional consideration significantly increases the computation load, we train neural networks to efficiently predict multi-contact zero-step and one-step capturability, which allows the planner to generate robust contact sequences efficiently. Our results show that our approach generates footstep sequences that are more robust to external disturbances than a conventional footstep planner in four challenging scenarios.
Efficient Humanoid Contact Planning using Learned Centroidal Dynamics Prediction
Mar 01, 2019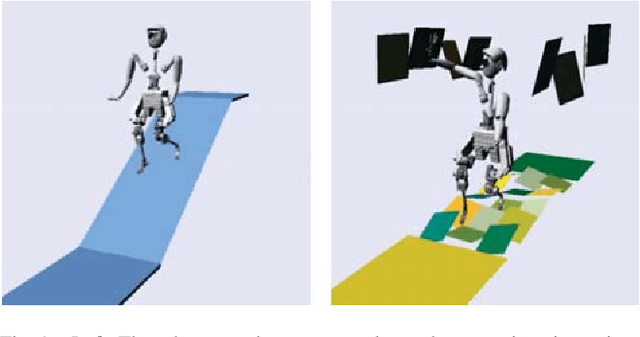
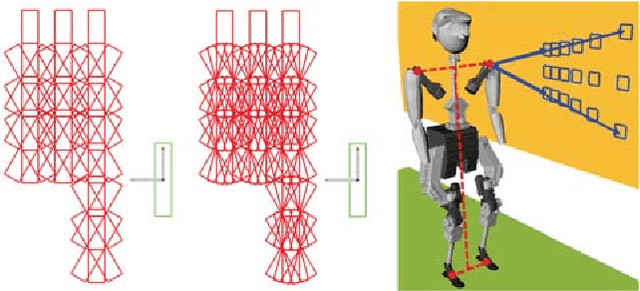
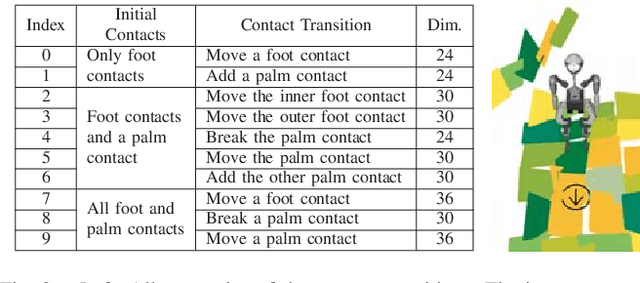
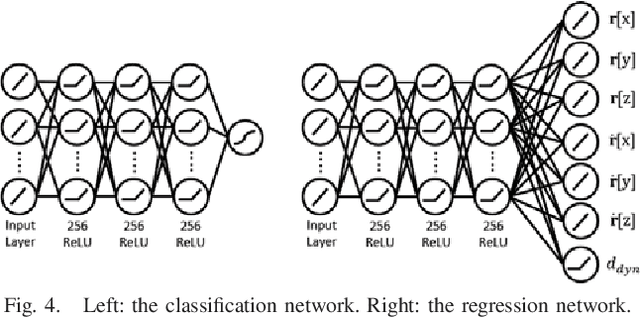
Humanoid robots dynamically navigate an environment by interacting with it via contact wrenches exerted at intermittent contact poses. Therefore, it is important to consider dynamics when planning a contact sequence. Traditional contact planning approaches assume a quasi-static balance criterion to reduce the computational challenges of selecting a contact sequence over a rough terrain. This however limits the applicability of the approach when dynamic motions are required, such as when walking down a steep slope or crossing a wide gap. Recent methods overcome this limitation with the help of efficient mixed integer convex programming solvers capable of synthesizing dynamic contact sequences. Nevertheless, its exponential-time complexity limits its applicability to short time horizon contact sequences within small environments. In this paper, we go beyond current approaches by learning a prediction of the dynamic evolution of the robot centroidal momenta, which can then be used for quickly generating dynamically robust contact sequences for robots with arms and legs using a search-based contact planner. We demonstrate the efficiency and quality of the results of the proposed approach in a set of dynamically challenging scenarios.