 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVG: Towards UNIfied-modal Video Generation
Jan 17, 2024Diffusion based video generation has received extensive attention and achieved considerable success within both the academic and industrial communities. However, current efforts are mainly concentrated on single-objective or single-task video generation, such as generation driven by text, by image, or by a combination of text and image. This cannot fully meet the needs of real-world application scenarios, as users are likely to input images and text conditions in a flexible manner, either individually or in combination. To address this, we propose a Unified-modal Video Genearation system that is capable of handling multiple video generation tasks across text and image modalities. To this end, we revisit the various video generation tasks within our system from the perspective of generative freedom, and classify them into high-freedom and low-freedom video generation categories. For high-freedom video generation, we employ Multi-condition Cross Attention to generate videos that align with the semantics of the input images or text. For low-freedom video generation, we introduce Biased Gaussian Noise to replace the pure random Gaussian Noise, which helps to better preserve the content of the input conditions. Our method achieves the lowest Fr\'echet Video Distance (FVD) on the public academic benchmark MSR-VTT, surpasses the current open-source methods in human evaluations, and is on par with the current close-source method Gen2. For more samples, visit https://univg-baidu.github.io.
Accommodating Audio Modality in CLIP for Multimodal Processing
Mar 12, 2023Multimodal processing has attracted much attention lately especially with the success of pre-training. However, the exploration has mainly focused on vision-language pre-training, as introducing more modalities can greatly complicate model design and optimization. In this paper, we extend the stateof-the-art Vision-Language model CLIP to accommodate the audio modality for Vision-Language-Audio multimodal processing. Specifically, we apply inter-modal and intra-modal contrastive learning to explore the correlation between audio and other modalities in addition to the inner characteristics of the audio modality. Moreover, we further design an audio type token to dynamically learn different audio information type for different scenarios, as both verbal and nonverbal heterogeneous information is conveyed in general audios. Our proposed CLIP4VLA model is validated in different downstream tasks including video retrieval and video captioning, and achieves the state-of-the-art performance on the benchmark datasets of MSR-VTT, VATEX, and Audiocaps.
TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat
Jan 14, 2023



We present a novel multi-modal chitchat dialogue dataset-TikTalk aimed at facilitating the research of intelligent chatbots. It consists of the videos and corresponding dialogues users generate on video social applications. In contrast to existing multi-modal dialogue datasets, we construct dialogue corpora based on video comment-reply pairs, which is more similar to chitchat in real-world dialogue scenarios. Our dialogue context includes three modalities: text, vision, and audio. Compared with previous image-based dialogue datasets, the richer sources of context in TikTalk lead to a greater diversity of conversations. TikTalk contains over 38K videos and 367K dialogues. Data analysis shows that responses in TikTalk are in correlation with various contexts and external knowledge. It poses a great challenge for the deep understanding of multi-modal information and the generation of responses. We evaluate several baselines on three types of automatic metrics and conduct case studies. Experimental results demonstrate that there is still a large room for future improvement on TikTalk. Our dataset is available at \url{https://github.com/RUC-AIMind/TikTalk}.
MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Dec 19, 2022We propose the first joint audio-video generation framework that brings engaging watching and listening experiences simultaneously, towards high-quality realistic videos. To generate joint audio-video pairs, we propose a novel Multi-Modal Diffusion model (i.e., MM-Diffusion), with two-coupled denoising autoencoders. In contrast to existing single-modal diffusion models, MM-Diffusion consists of a sequential multi-modal U-Net for a joint denoising process by design. Two subnets for audio and video learn to gradually generate aligned audio-video pairs from Gaussian noises. To ensure semantic consistency across modalities, we propose a novel random-shift based attention block bridging over the two subnets, which enables efficient cross-modal alignment, and thus reinforces the audio-video fidelity for each other. Extensive experiments show superior results in unconditional audio-video generation, and zero-shot conditional tasks (e.g., video-to-audio). In particular, we achieve the best FVD and FAD on Landscape and AIST++ dancing datasets. Turing tests of 10k votes further demonstrate dominant preferences for our model. The code and pre-trained models can be downloaded at https://github.com/researchmm/MM-Diffusion.
Survey: Transformer based Video-Language Pre-training
Sep 21, 2021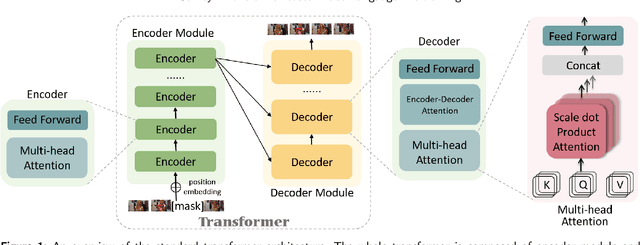
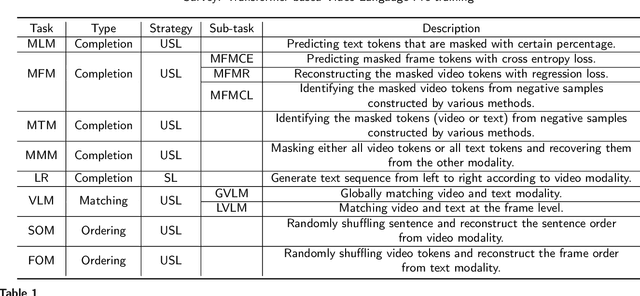
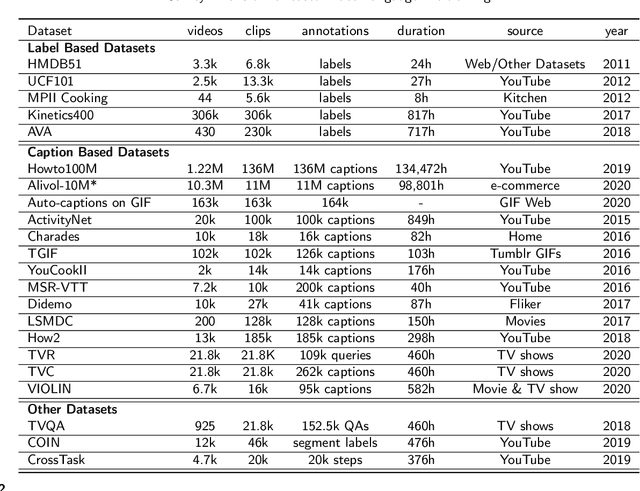
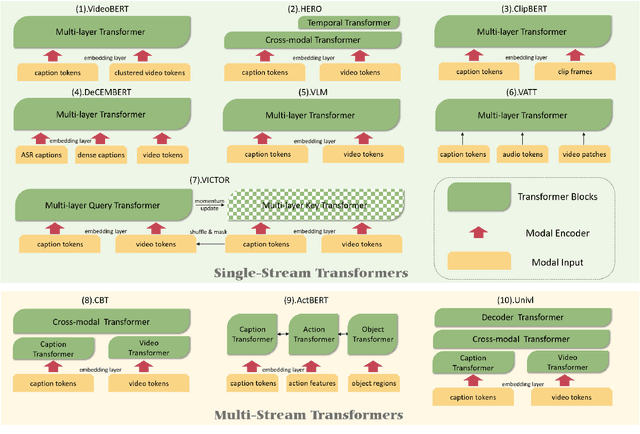
Inspired by the success of transformer-based pre-training methods on natural language tasks and further computer vision tasks, researchers have begun to apply transformer to video processing. This survey aims to give a comprehensive overview on transformer-based pre-training methods for Video-Language learning. We first briefly introduce the transformer tructure as the background knowledge, including attention mechanism, position encoding etc. We then describe the typical paradigm of pre-training & fine-tuning on Video-Language processing in terms of proxy tasks, downstream tasks and commonly used video datasets. Next, we categorize transformer models into Single-Stream and Multi-Stream structures, highlight their innovations and compare their performances. Finally, we analyze and discuss the current challenges and possible future research directions for Video-Language pre-training.
Team RUC_AIM3 Technical Report at ActivityNet 2021: Entities Object Localization
Jun 11, 2021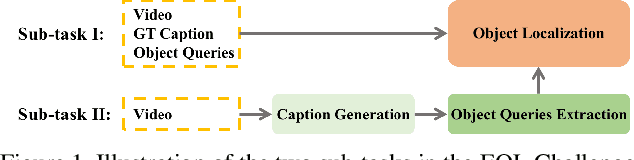
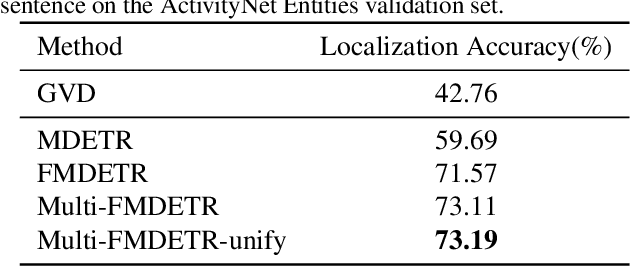
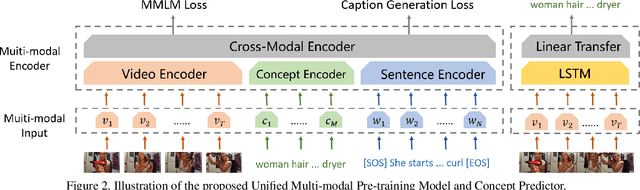
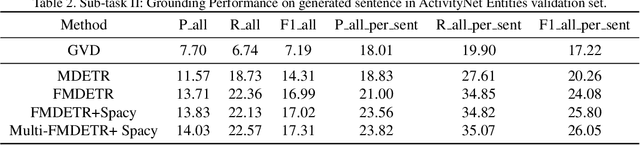
Entities Object Localization (EOL) aims to evaluate how grounded or faithful a description is, which consists of caption generation and object grounding. Previous works tackle this problem by jointly training the two modules in a framework, which limits the complexity of each module. Therefore, in this work, we propose to divide these two modules into two stages and improve them respectively to boost the whole system performance. For the caption generation, we propose a Unified Multi-modal Pre-training Model (UMPM) to generate event descriptions with rich objects for better localization. For the object grounding, we fine-tune the state-of-the-art detection model MDETR and design a post processing method to make the grounding results more faithful. Our overall system achieves the state-of-the-art performances on both sub-tasks in Entities Object Localization challenge at Activitynet 2021, with 72.57 localization accuracy on the testing set of sub-task I and 0.2477 F1_all_per_sent on the hidden testing set of sub-task II.
YouMakeup VQA Challenge: Towards Fine-grained Action Understanding in Domain-Specific Videos
Apr 12, 2020
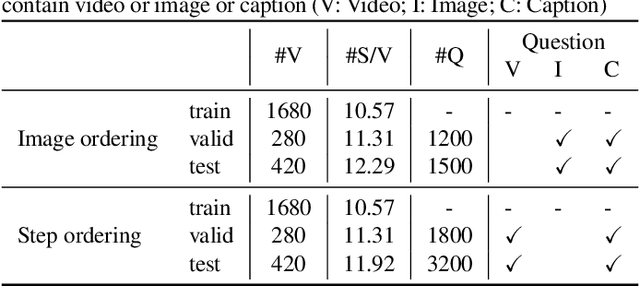

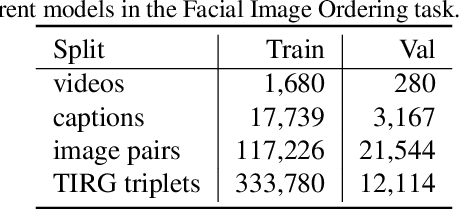
The goal of the YouMakeup VQA Challenge 2020 is to provide a common benchmark for fine-grained action understanding in domain-specific videos e.g. makeup instructional videos. We propose two novel question-answering tasks to evaluate models' fine-grained action understanding abilities. The first task is \textbf{Facial Image Ordering}, which aims to understand visual effects of different actions expressed in natural language to the facial object. The second task is \textbf{Step Ordering}, which aims to measure cross-modal semantic alignments between untrimmed videos and multi-sentence texts. In this paper, we present the challenge guidelines, the dataset used, and performances of baseline models on the two proposed tasks. The baseline codes and models are released at \url{https://github.com/AIM3-RUC/YouMakeup_Baseline}.