 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Aspect-Level Sentiment Analysis with Aspect Extraction
May 03, 2020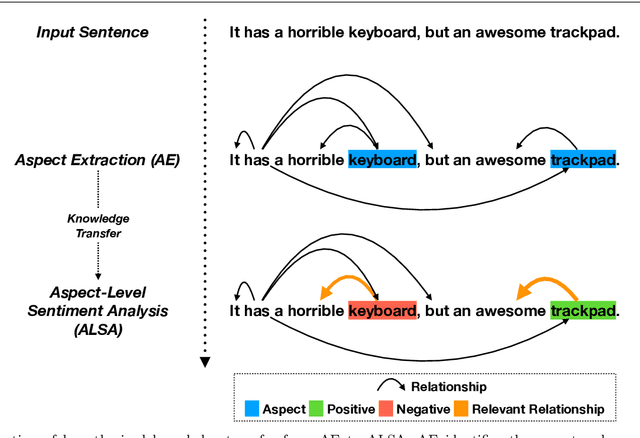
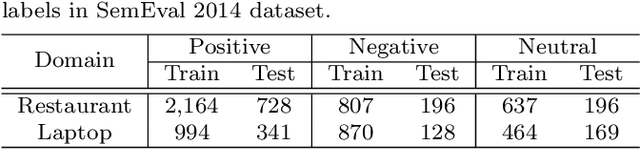
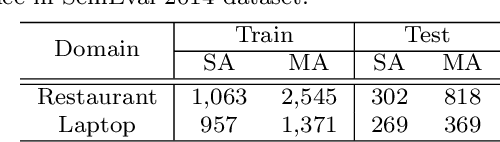
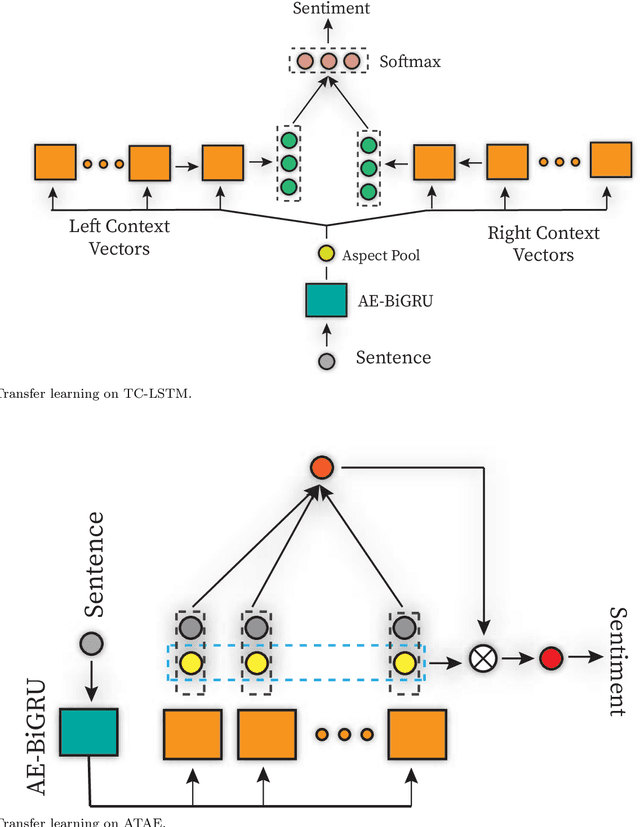
Aspect-based sentiment analysis (ABSA), a popular research area in NLP has two distinct parts -- aspect extraction (AE) and labeling the aspects with sentiment polarity (ALSA). Although distinct, these two tasks are highly correlated. The work primarily hypothesize that transferring knowledge from a pre-trained AE model can benefit the performance of ALSA models. Based on this hypothesis, word embeddings are obtained during AE and subsequently, feed that to the ALSA model. Empirically, this work show that the added information significantly improves the performance of three different baseline ALSA models on two distinct domains. This improvement also translates well across domains between AE and ALSA tasks.
Interpretable Multimodal Routing for Human Multimodal Language
Apr 29, 2020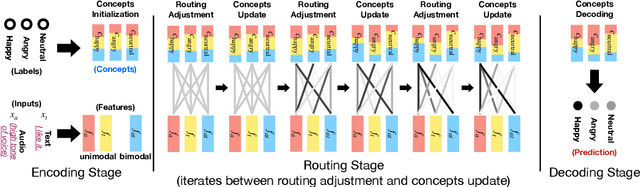
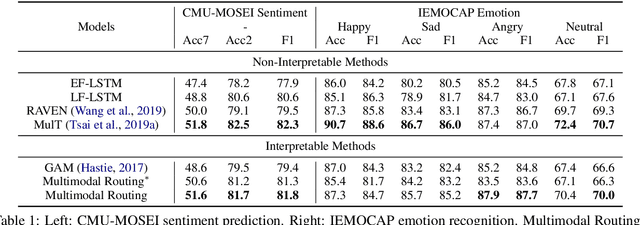
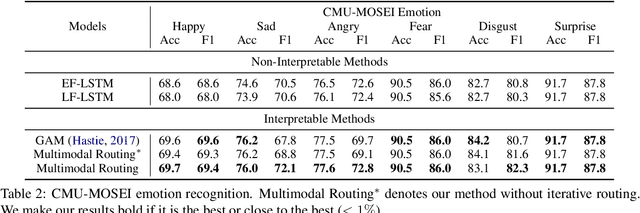

The human language has heterogeneous sources of information, including tones of voice, facial gestures, and spoken language. Recent advances introduced computational models to combine these multimodal sources and yielded strong performance on human-centric tasks. Nevertheless, most of the models are often black-box, which comes with the price of lacking interpretability. In this paper, we propose Multimodal Routing to separate the contributions to the prediction from each modality and the interactions between modalities. At the heart of our method is a routing mechanism that represents each prediction as a concept, i.e., a vector in a Euclidean space. The concept assumes a linear aggregation from the contributions of multimodal features. Then, the routing procedure iteratively 1) associates a feature and a concept by checking how this concept agrees with this feature and 2) updates the concept based on the associations. In our experiments, we provide both global and local interpretation using Multimodal Routing on sentiment analysis and emotion prediction, without loss of performance compared to state-of-the-art methods. For example, we observe that our model relies mostly on the text modality for neutral sentiment predictions, the acoustic modality for extremely negative predictions, and the text-acoustic bimodal interaction for extremely positive predictions.
Diverse and Admissible Trajectory Forecasting through Multimodal Context Understanding
Apr 03, 2020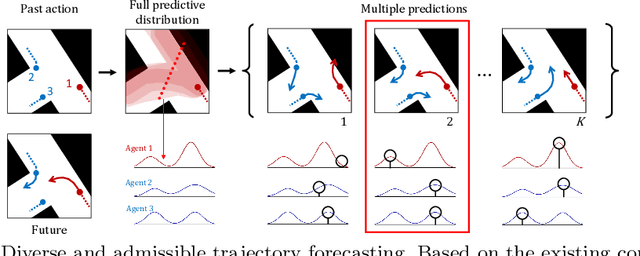
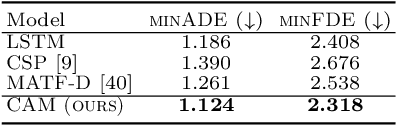
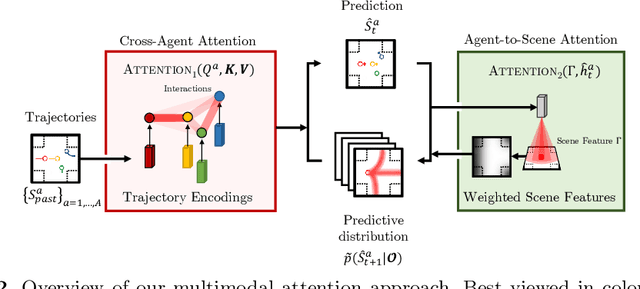
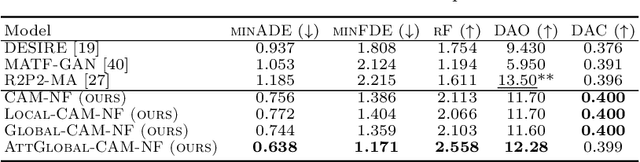
Multi-agent trajectory forecasting in autonomous driving requires an agent to accurately anticipate the behaviors of the surrounding vehicles and pedestrians, for safe and reliable decision-making. Due to partial observability over the goals, contexts, and interactions of agents in these dynamical scenes, directly obtaining the posterior distribution over future agent trajectories remains a challenging problem. In realistic embodied environments, each agent's future trajectories should be diverse since multiple plausible sequences of actions can be used to reach its intended goals, and they should be admissible since they must obey physical constraints and stay in drivable areas. In this paper, we propose a model that fully synthesizes multiple input signals from the multimodal world|the environment's scene context and interactions between multiple surrounding agents|to best model all diverse and admissible trajectories. We offer new metrics to evaluate the diversity of trajectory predictions, while ensuring admissibility of each trajectory. Based on our new metrics as well as those used in prior work, we compare our model with strong baselines and ablations across two datasets and show a 35% performance-improvement over the state-of-the-art.
On Emergent Communication in Competitive Multi-Agent Teams
Mar 04, 2020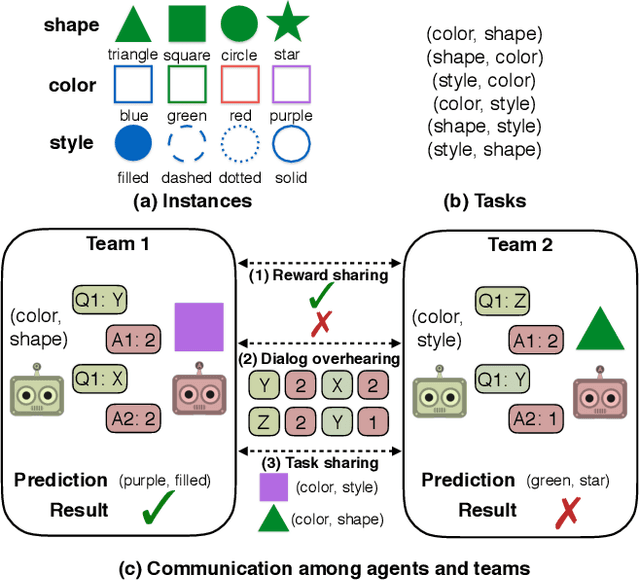
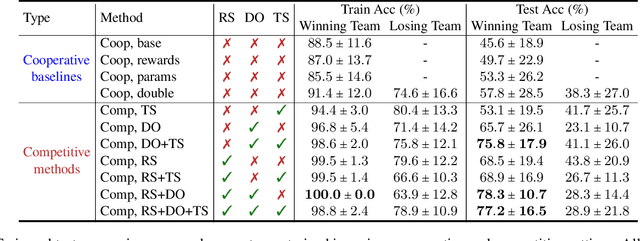
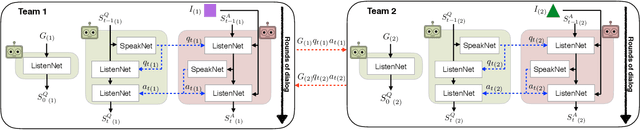
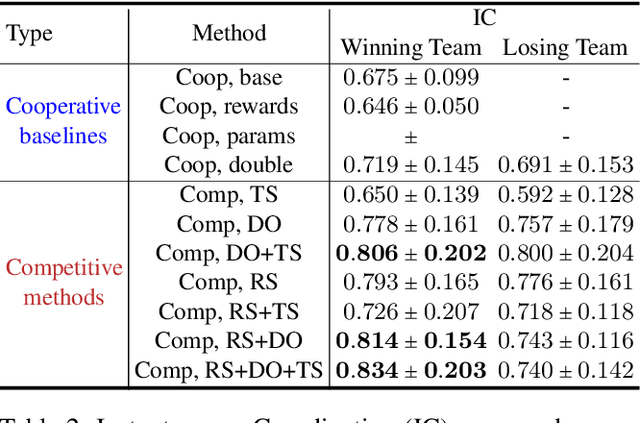
Several recent works have found the emergence of grounded compositional language in the communication protocols developed by mostly cooperative multi-agent systems when learned end-to-end to maximize performance on a downstream task. However, human populations learn to solve complex tasks involving communicative behaviors not only in fully cooperative settings but also in scenarios where competition acts as an additional external pressure for improvement. In this work, we investigate whether competition for performance from an external, similar agent team could act as a social influence that encourages multi-agent populations to develop better communication protocols for improved performance, compositionality, and convergence speed. We start from Task & Talk, a previously proposed referential game between two cooperative agents as our testbed and extend it into Task, Talk & Compete, a game involving two competitive teams each consisting of two aforementioned cooperative agents. Using this new setting, we provide an empirical study demonstrating the impact of competitive influence on multi-agent teams. Our results show that an external competitive influence leads to improved accuracy and generalization, as well as faster emergence of communicative languages that are more informative and compositional.
Learning Not to Learn in the Presence of Noisy Labels
Feb 16, 2020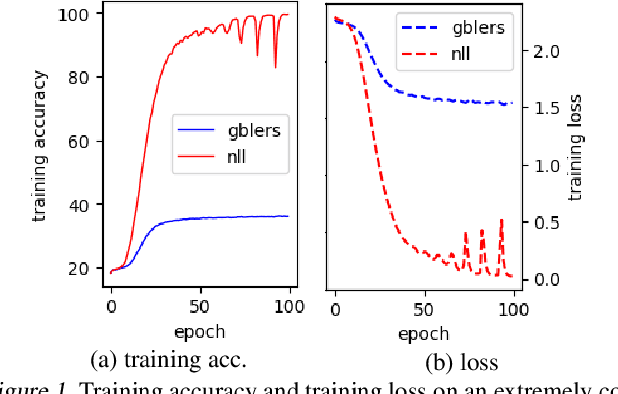

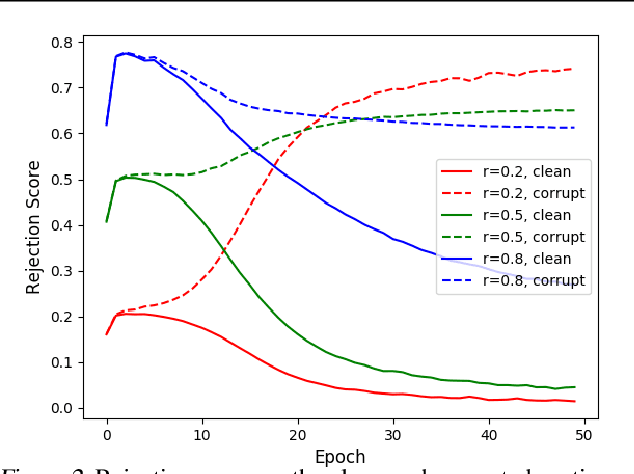
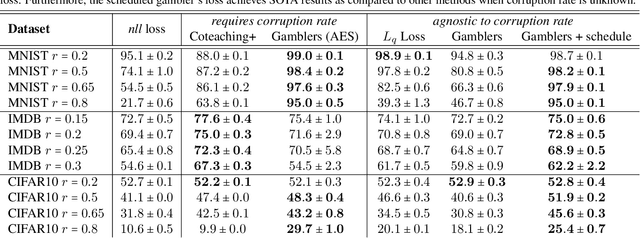
Learning in the presence of label noise is a challenging yet important task: it is crucial to design models that are robust in the presence of mislabeled datasets. In this paper, we discover that a new class of loss functions called the gambler's loss provides strong robustness to label noise across various levels of corruption. We show that training with this loss function encourages the model to "abstain" from learning on the data points with noisy labels, resulting in a simple and effective method to improve robustness and generalization. In addition, we propose two practical extensions of the method: 1) an analytical early stopping criterion to approximately stop training before the memorization of noisy labels, as well as 2) a heuristic for setting hyperparameters which do not require knowledge of the noise corruption rate. We demonstrate the effectiveness of our method by achieving strong results across three image and text classification tasks as compared to existing baselines.
Think Locally, Act Globally: Federated Learning with Local and Global Representations
Jan 06, 2020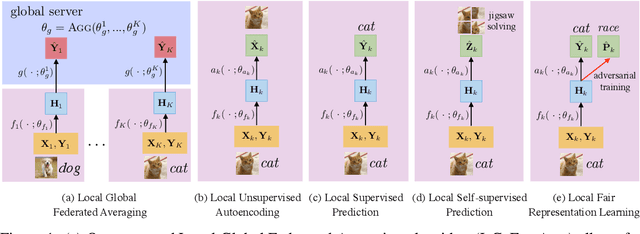

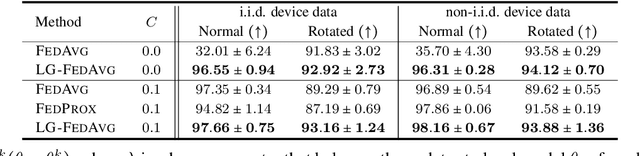
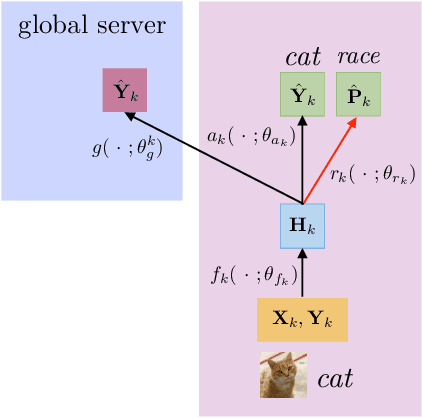
Federated learning is an emerging research paradigm to train models on private data distributed over multiple devices. A key challenge involves keeping private all the data on each device and training a global model only by communicating parameters and updates. Overcoming this problem relies on the global model being sufficiently compact so that the parameters can be efficiently sent over communication channels such as wireless internet. Given the recent trend towards building deeper and larger neural networks, deploying such models in federated settings on real-world tasks is becoming increasingly difficult. To this end, we propose to augment federated learning with local representation learning on each device to learn useful and compact features from raw data. As a result, the global model can be smaller since it only operates on higher-level local representations. We show that our proposed method achieves superior or competitive results when compared to traditional federated approaches on a suite of publicly available real-world datasets spanning image recognition (MNIST, CIFAR) and multimodal learning (VQA). Our choice of local representation learning also reduces the number of parameters and updates that need to be communicated to and from the global model, thereby reducing the bottleneck in terms of communication cost. Finally, we show that our local models provide flexibility in dealing with online heterogeneous data and can be easily modified to learn fair representations that obfuscate protected attributes such as race, age, and gender, a feature crucial to preserving the privacy of on-device data.
Context-Dependent Models for Predicting and Characterizing Facial Expressiveness
Dec 10, 2019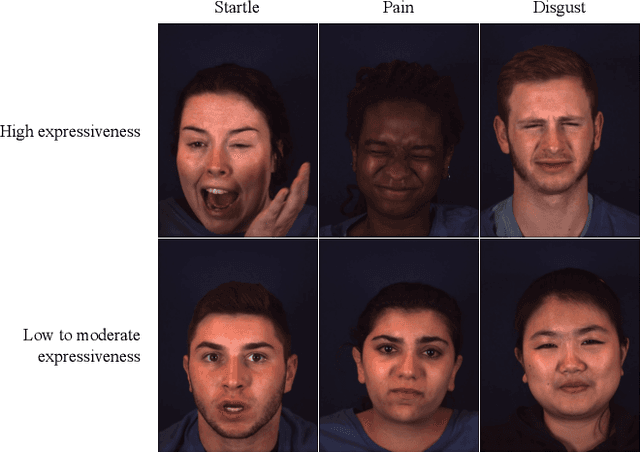
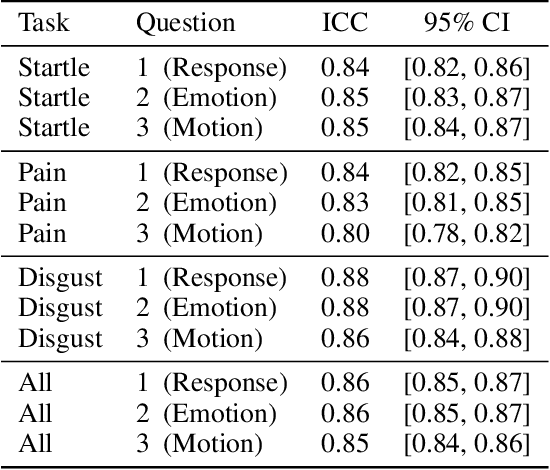
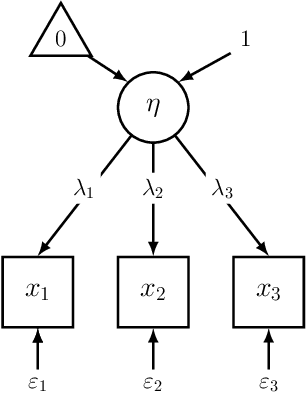
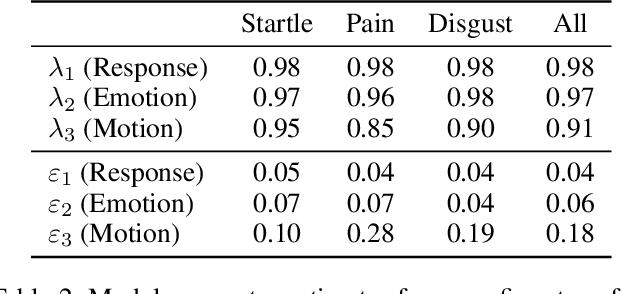
In recent years, extensive research has emerged in affective computing on topics like automatic emotion recognition and determining the signals that characterize individual emotions. Much less studied, however, is expressiveness, or the extent to which someone shows any feeling or emotion. Expressiveness is related to personality and mental health and plays a crucial role in social interaction. As such, the ability to automatically detect or predict expressiveness can facilitate significant advancements in areas ranging from psychiatric care to artificial social intelligence. Motivated by these potential applications, we present an extension of the BP4D+ dataset with human ratings of expressiveness and develop methods for (1) automatically predicting expressiveness from visual data and (2) defining relationships between interpretable visual signals and expressiveness. In addition, we study the emotional context in which expressiveness occurs and hypothesize that different sets of signals are indicative of expressiveness in different contexts (e.g., in response to surprise or in response to pain). Analysis of our statistical models confirms our hypothesis. Consequently, by looking at expressiveness separately in distinct emotional contexts, our predictive models show significant improvements over baselines and achieve comparable results to human performance in terms of correlation with the ground truth.
Factorized Multimodal Transformer for Multimodal Sequential Learning
Nov 22, 2019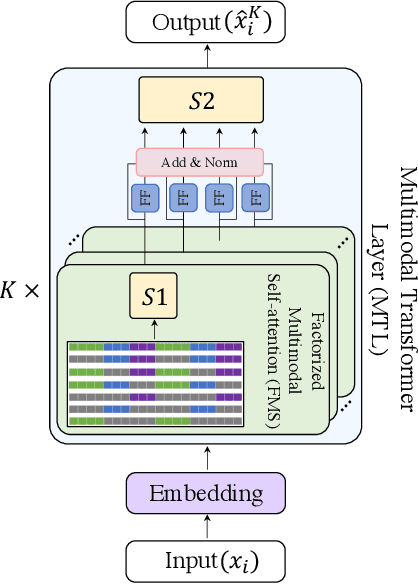
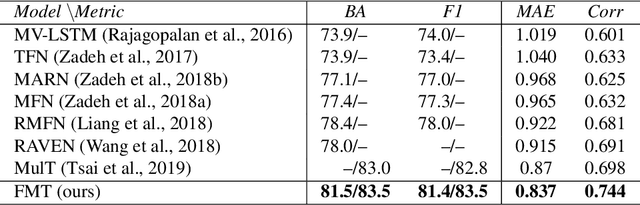
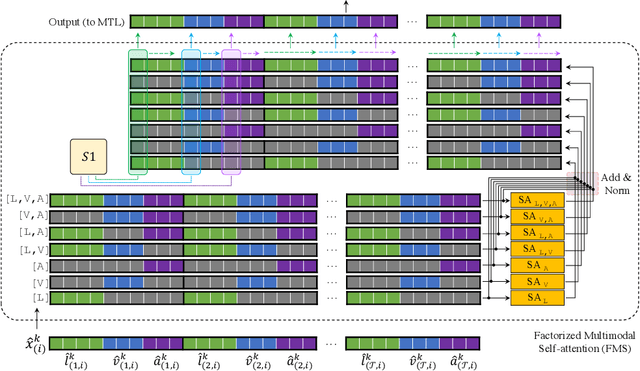
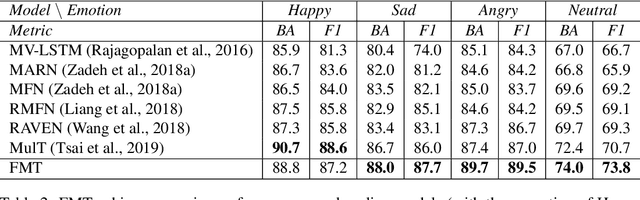
The complex world around us is inherently multimodal and sequential (continuous). Information is scattered across different modalities and requires multiple continuous sensors to be captured. As machine learning leaps towards better generalization to real world, multimodal sequential learning becomes a fundamental research area. Arguably, modeling arbitrarily distributed spatio-temporal dynamics within and across modalities is the biggest challenge in this research area. In this paper, we present a new transformer model, called the Factorized Multimodal Transformer (FMT) for multimodal sequential learning. FMT inherently models the intramodal and intermodal (involving two or more modalities) dynamics within its multimodal input in a factorized manner. The proposed factorization allows for increasing the number of self-attentions to better model the multimodal phenomena at hand; without encountering difficulties during training (e.g. overfitting) even on relatively low-resource setups. All the attention mechanisms within FMT have a full time-domain receptive field which allows them to asynchronously capture long-range multimodal dynamics. In our experiments we focus on datasets that contain the three commonly studied modalities of language, vision and acoustic. We perform a wide range of experiments, spanning across 3 well-studied datasets and 21 distinct labels. FMT shows superior performance over previously proposed models, setting new state of the art in the studied datasets.
WildMix Dataset and Spectro-Temporal Transformer Model for Monoaural Audio Source Separation
Nov 21, 2019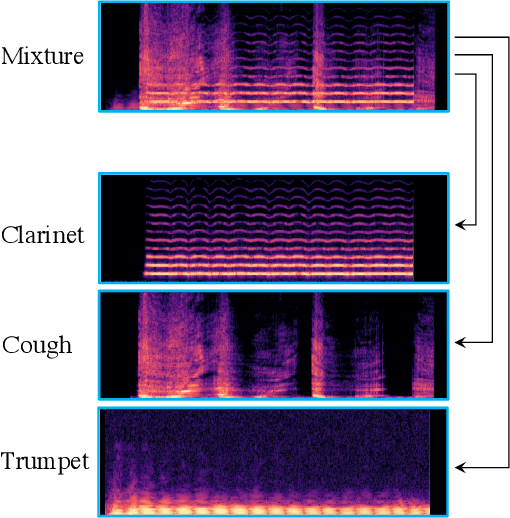
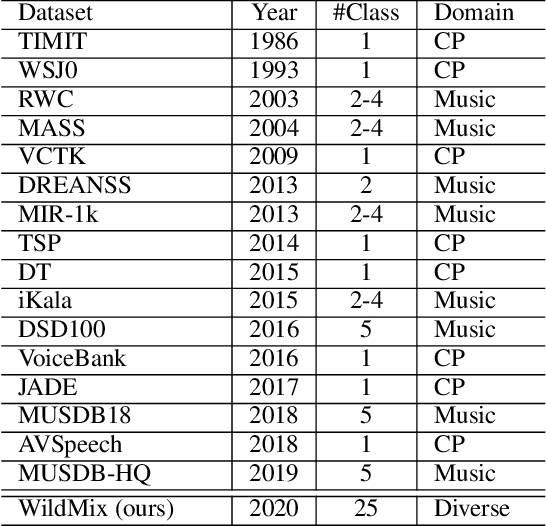

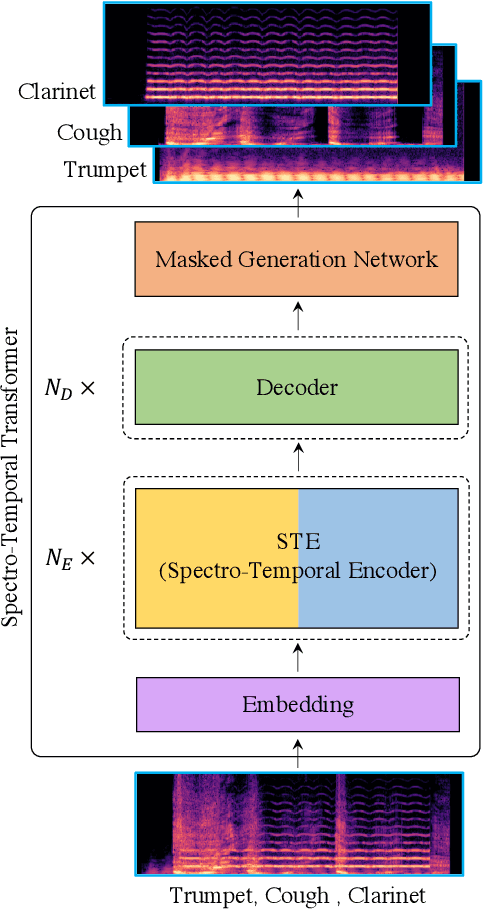
Monoaural audio source separation is a challenging research area in machine learning. In this area, a mixture containing multiple audio sources is given, and a model is expected to disentangle the mixture into isolated atomic sources. In this paper, we first introduce a challenging new dataset for monoaural source separation called WildMix. WildMix is designed with the goal of extending the boundaries of source separation beyond what previous datasets in this area would allow. It contains diverse in-the-wild recordings from 25 different sound classes, combined with each other using arbitrary composition policies. Source separation often requires modeling long-range dependencies in both temporal and spectral domains. To this end, we introduce a novel trasnformer-based model called Spectro-Temporal Transformer (STT). STT utilizes a specialized encoder, called Spectro-Temporal Encoder (STE). STE highlights temporal and spectral components of sources within a mixture, using a self-attention mechanism. It subsequently disentangles them in a hierarchical manner. In our experiments, STT swiftly outperforms various previous baselines for monoaural source separation on the challenging WildMix dataset.
To React or not to React: End-to-End Visual Pose Forecasting for Personalized Avatar during Dyadic Conversations
Oct 05, 2019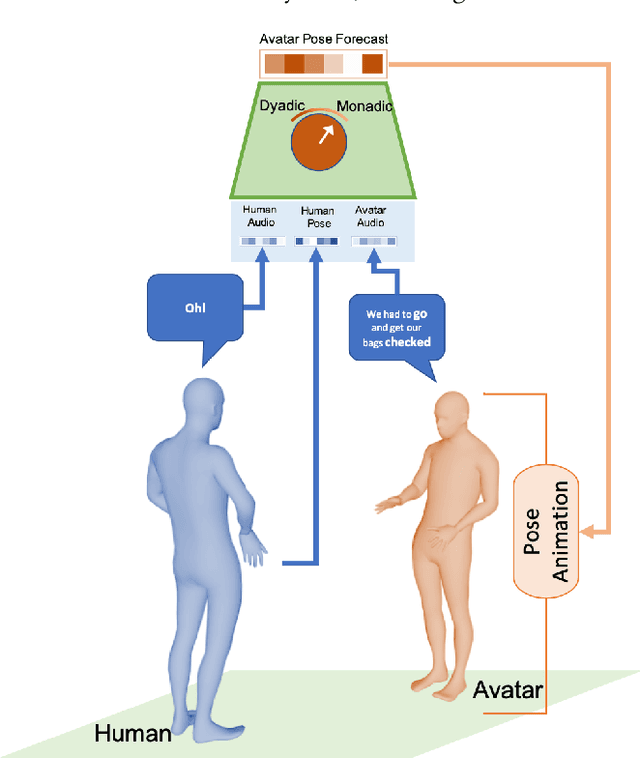
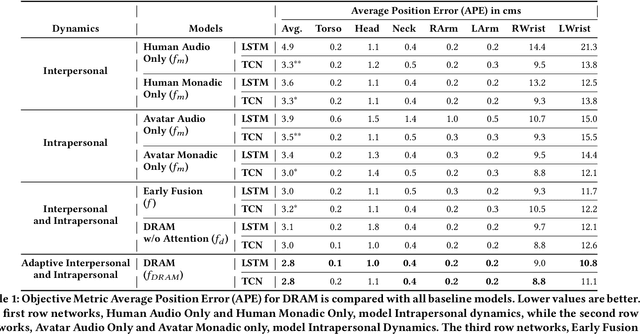
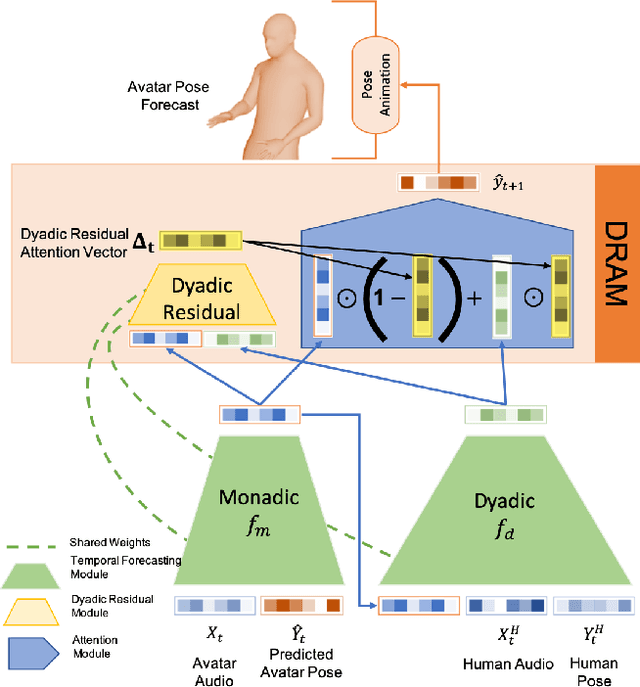
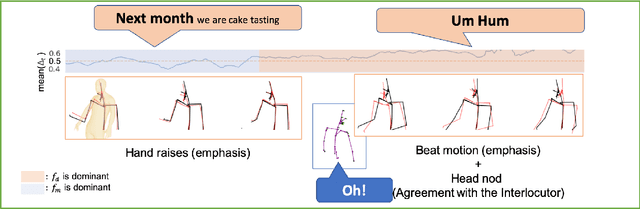
Non verbal behaviours such as gestures, facial expressions, body posture, and para-linguistic cues have been shown to complement or clarify verbal messages. Hence to improve telepresence, in form of an avatar, it is important to model these behaviours, especially in dyadic interactions. Creating such personalized avatars not only requires to model intrapersonal dynamics between a avatar's speech and their body pose, but it also needs to model interpersonal dynamics with the interlocutor present in the conversation. In this paper, we introduce a neural architecture named Dyadic Residual-Attention Model (DRAM), which integrates intrapersonal (monadic) and interpersonal (dyadic) dynamics using selective attention to generate sequences of body pose conditioned on audio and body pose of the interlocutor and audio of the human operating the avatar. We evaluate our proposed model on dyadic conversational data consisting of pose and audio of both participants, confirming the importance of adaptive attention between monadic and dyadic dynamics when predicting avatar pose. We also conduct a user study to analyze judgments of human observers. Our results confirm that the generated body pose is more natural, models intrapersonal dynamics and interpersonal dynamics better than non-adaptive monadic/dyadic models.