 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarNet: Gradient-free Training of Deep Generative Models using Determined System of Linear Equations
Jan 03, 2021



In this paper we present an approach for training deep generative models solely based on solving determined systems of linear equations. A network that uses this approach, called a StarNet, has the following desirable properties: 1) training requires no gradient as solution to the system of linear equations is not stochastic, 2) is highly scalable when solving the system of linear equations w.r.t the latent codes, and similarly for the parameters of the model, and 3) it gives desirable least-square bounds for the estimation of latent codes and network parameters within each layer.
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020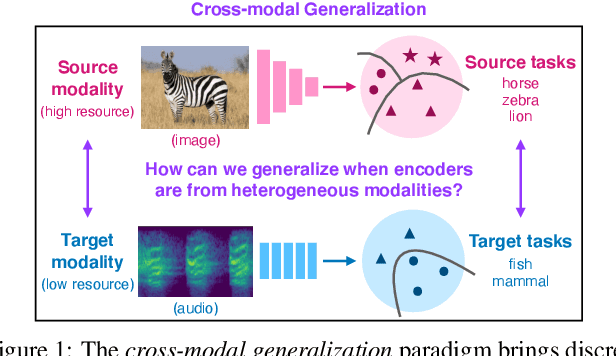
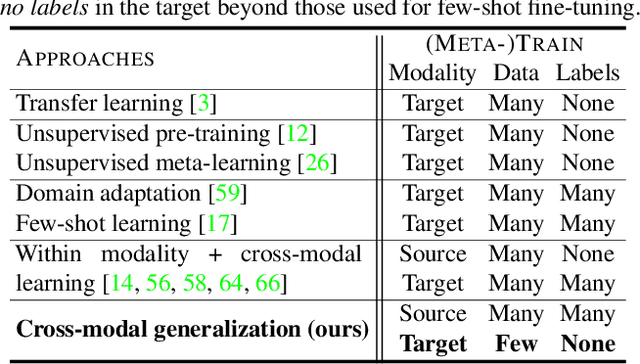
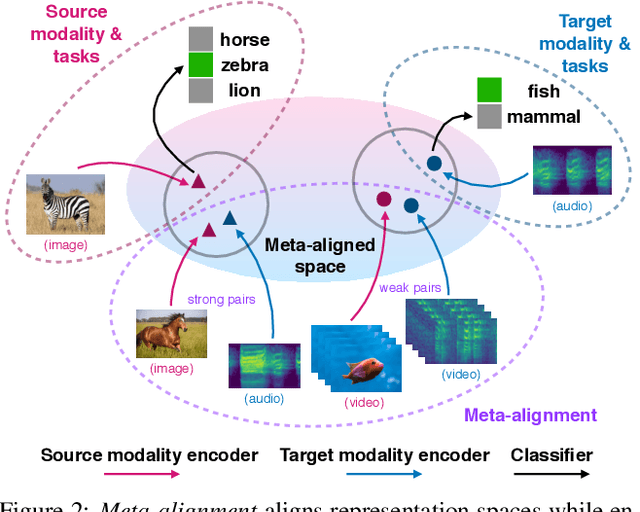
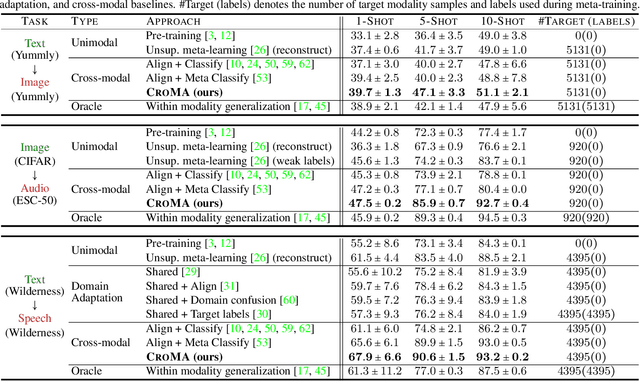
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
Multimodal Privacy-preserving Mood Prediction from Mobile Data: A Preliminary Study
Dec 04, 2020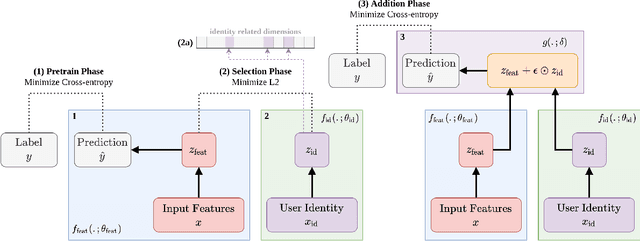
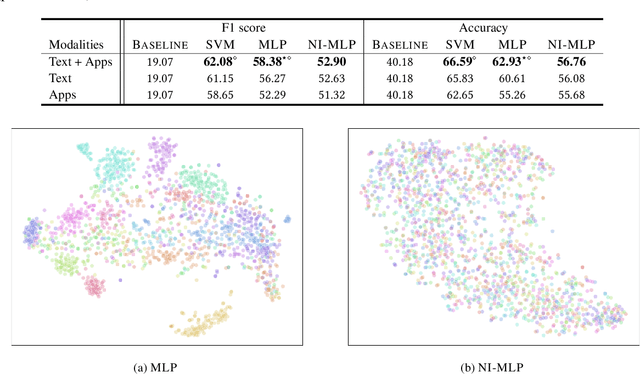
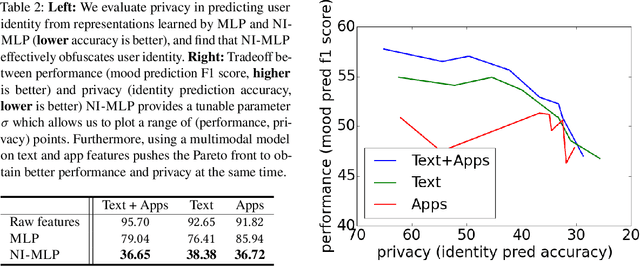
Mental health conditions remain under-diagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications towards the early detection and intervention of mental health disorders. One promising data source to help monitor human behavior is from daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected attributes (e.g., race, gender). In this paper, we study behavioral markers or daily mood using a recent dataset of mobile behaviors from high-risk adolescent populations. Using computational models, we find that multimodal modeling of both text and app usage features is highly predictive of daily mood over each modality alone. Furthermore, we evaluate approaches that reliably obfuscate user identity while remaining predictive of daily mood. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier as compared to unimodal approaches.
Unsupervised Domain Adaptation for Visual Navigation
Nov 12, 2020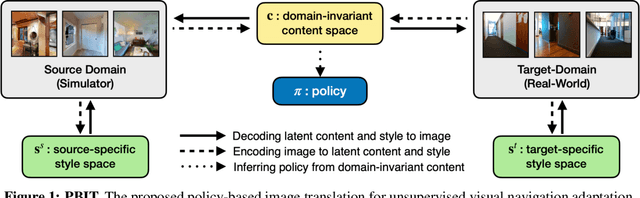
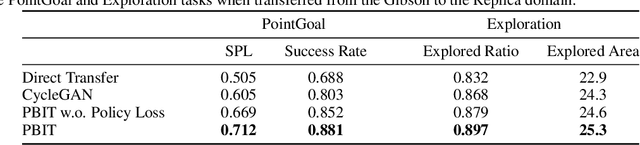

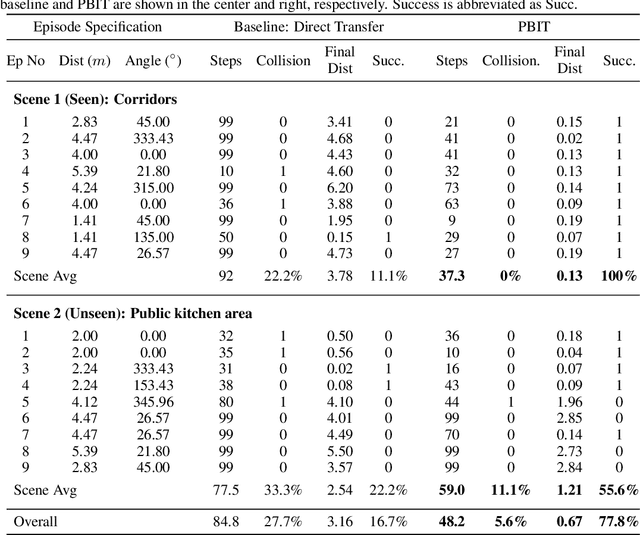
Advances in visual navigation methods have led to intelligent embodied navigation agents capable of learning meaningful representations from raw RGB images and perform a wide variety of tasks involving structural and semantic reasoning. However, most learning-based navigation policies are trained and tested in simulation environments. In order for these policies to be practically useful, they need to be transferred to the real-world. In this paper, we propose an unsupervised domain adaptation method for visual navigation. Our method translates the images in the target domain to the source domain such that the translation is consistent with the representations learned by the navigation policy. The proposed method outperforms several baselines across two different navigation tasks in simulation. We further show that our method can be used to transfer the navigation policies learned in simulation to the real world.
MTGAT: Multimodal Temporal Graph Attention Networks for Unaligned Human Multimodal Language Sequences
Oct 22, 2020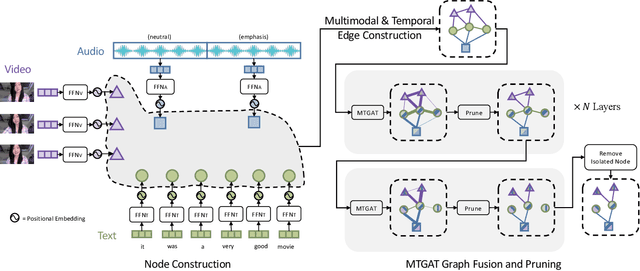
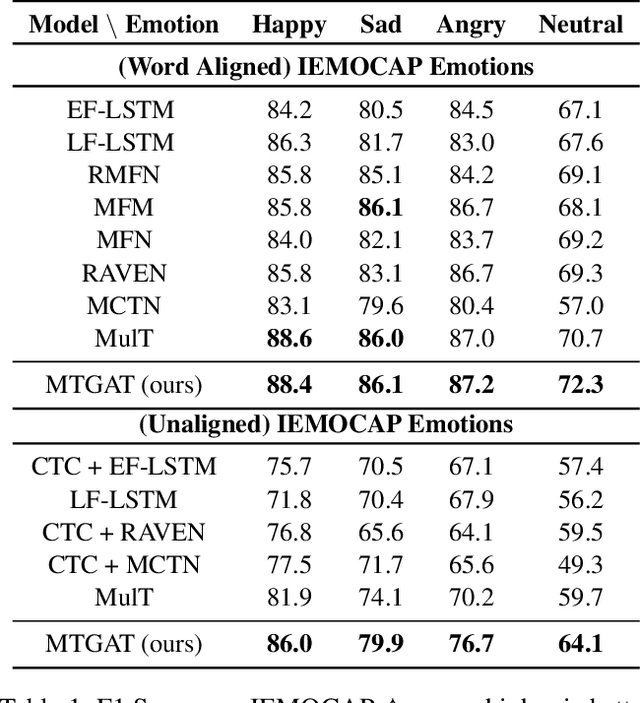
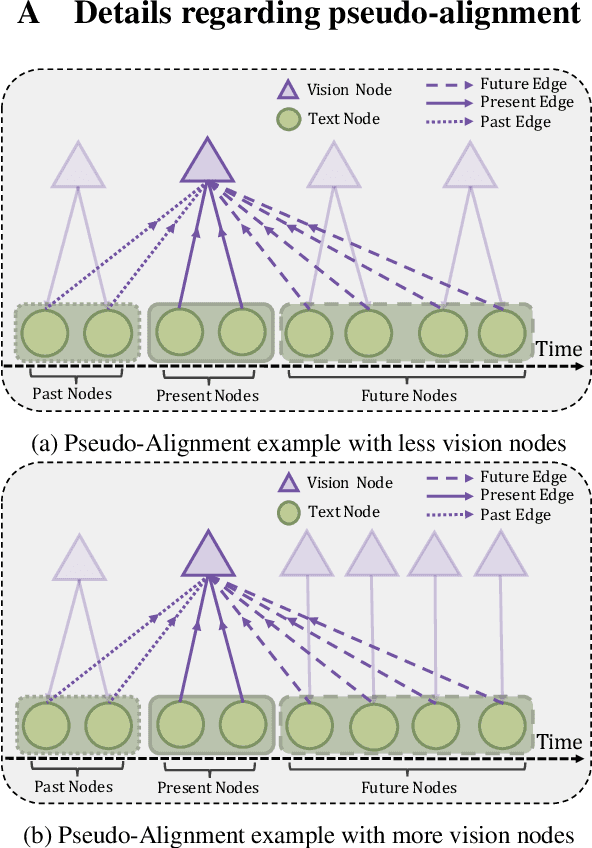
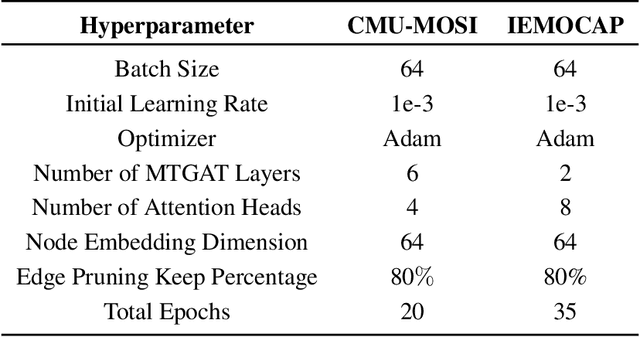
Human communication is multimodal in nature; it is through multiple modalities, i.e., language, voice, and facial expressions, that opinions and emotions are expressed. Data in this domain exhibits complex multi-relational and temporal interactions. Learning from this data is a fundamentally challenging research problem. In this paper, we propose Multimodal Temporal Graph Attention Networks (MTGAT). MTGAT is an interpretable graph-based neural model that provides a suitable framework for analyzing this type of multimodal sequential data. We first introduce a procedure to convert unaligned multimodal sequence data into a graph with heterogeneous nodes and edges that captures the rich interactions between different modalities through time. Then, a novel graph operation, called Multimodal Temporal Graph Attention, along with a dynamic pruning and read-out technique is designed to efficiently process this multimodal temporal graph. By learning to focus only on the important interactions within the graph, our MTGAT is able to achieve state-of-the-art performance on multimodal sentiment analysis and emotion recognition benchmarks including IEMOCAP and CMU-MOSI, while utilizing significantly fewer computations.
Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional-Mixture Approach
Jul 24, 2020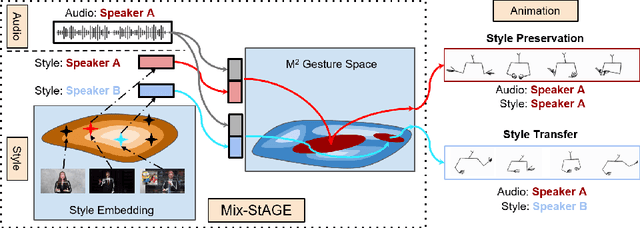
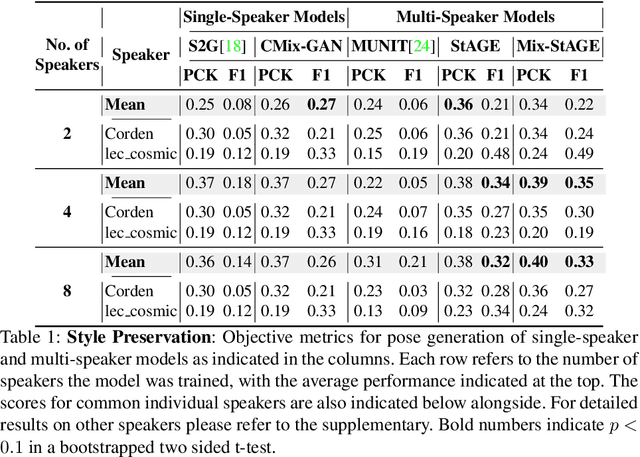
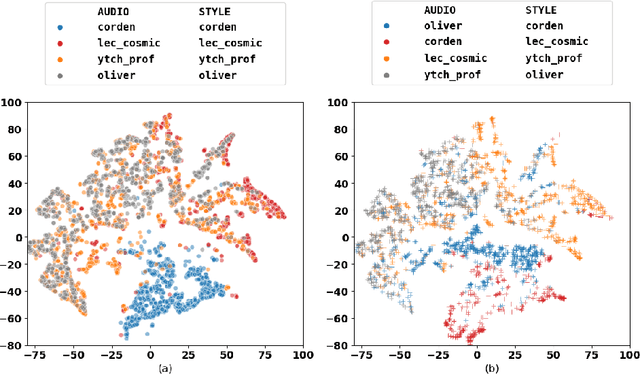
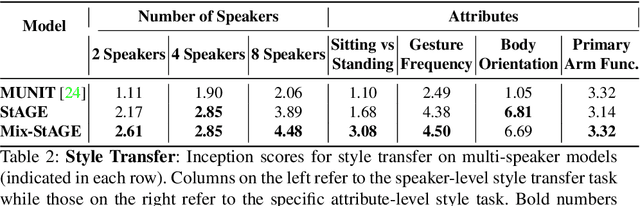
How can we teach robots or virtual assistants to gesture naturally? Can we go further and adapt the gesturing style to follow a specific speaker? Gestures that are naturally timed with corresponding speech during human communication are called co-speech gestures. A key challenge, called gesture style transfer, is to learn a model that generates these gestures for a speaking agent 'A' in the gesturing style of a target speaker 'B'. A secondary goal is to simultaneously learn to generate co-speech gestures for multiple speakers while remembering what is unique about each speaker. We call this challenge style preservation. In this paper, we propose a new model, named Mix-StAGE, which trains a single model for multiple speakers while learning unique style embeddings for each speaker's gestures in an end-to-end manner. A novelty of Mix-StAGE is to learn a mixture of generative models which allows for conditioning on the unique gesture style of each speaker. As Mix-StAGE disentangles style and content of gestures, gesturing styles for the same input speech can be altered by simply switching the style embeddings. Mix-StAGE also allows for style preservation when learning simultaneously from multiple speakers. We also introduce a new dataset, Pose-Audio-Transcript-Style (PATS), designed to study gesture generation and style transfer. Our proposed Mix-StAGE model significantly outperforms the previous state-of-the-art approach for gesture generation and provides a path towards performing gesture style transfer across multiple speakers. Link to code, data, and videos: http://chahuja.com/mix-stage
* 24 pages, 12 figures
Towards Debiasing Sentence Representations
Jul 16, 2020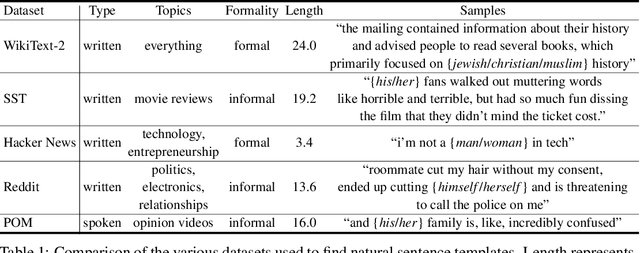
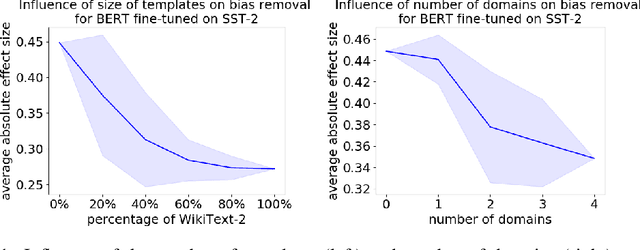

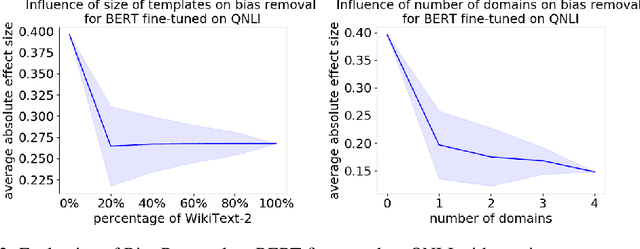
As natural language processing methods are increasingly deployed in real-world scenarios such as healthcare, legal systems, and social science, it becomes necessary to recognize the role they potentially play in shaping social biases and stereotypes. Previous work has revealed the presence of social biases in widely used word embeddings involving gender, race, religion, and other social constructs. While some methods were proposed to debias these word-level embeddings, there is a need to perform debiasing at the sentence-level given the recent shift towards new contextualized sentence representations such as ELMo and BERT. In this paper, we investigate the presence of social biases in sentence-level representations and propose a new method, Sent-Debias, to reduce these biases. We show that Sent-Debias is effective in removing biases, and at the same time, preserves performance on sentence-level downstream tasks such as sentiment analysis, linguistic acceptability, and natural language understanding. We hope that our work will inspire future research on characterizing and removing social biases from widely adopted sentence representations for fairer NLP.
What Gives the Answer Away? Question Answering Bias Analysis on Video QA Datasets
Jul 07, 2020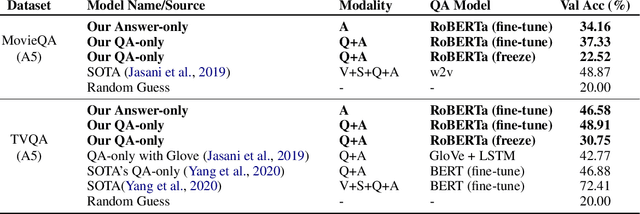
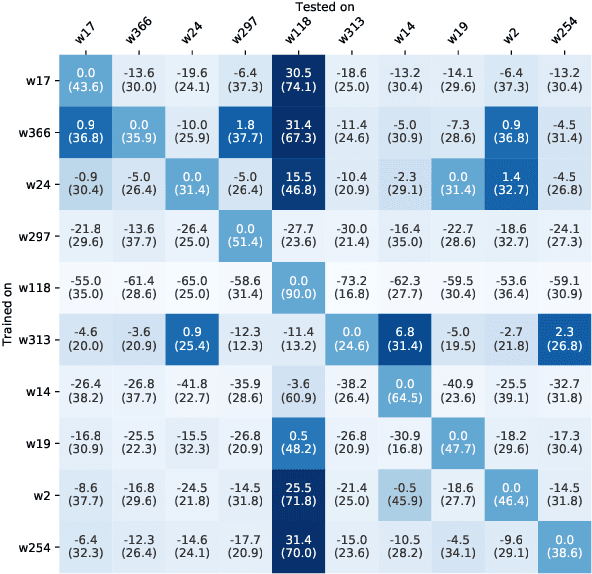

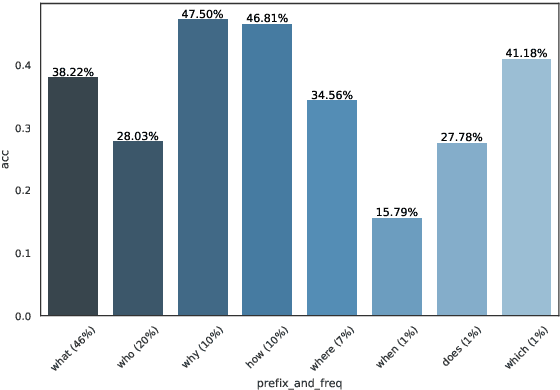
Question answering biases in video QA datasets can mislead multimodal model to overfit to QA artifacts and jeopardize the model's ability to generalize. Understanding how strong these QA biases are and where they come from helps the community measure progress more accurately and provide researchers insights to debug their models. In this paper, we analyze QA biases in popular video question answering datasets and discover pretrained language models can answer 37-48% questions correctly without using any multimodal context information, far exceeding the 20% random guess baseline for 5-choose-1 multiple-choice questions. Our ablation study shows biases can come from annotators and type of questions. Specifically, annotators that have been seen during training are better predicted by the model and reasoning, abstract questions incur more biases than factual, direct questions. We also show empirically that using annotator-non-overlapping train-test splits can reduce QA biases for video QA datasets.
Neural Methods for Point-wise Dependency Estimation
Jun 11, 2020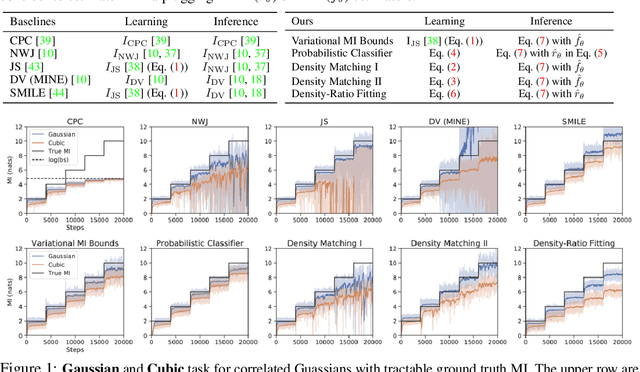
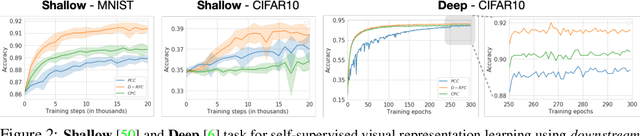
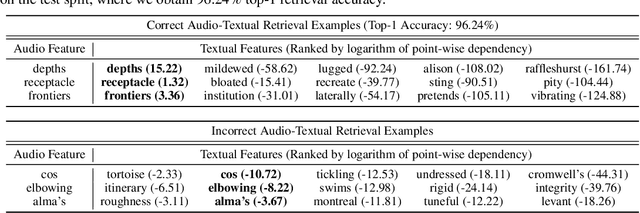
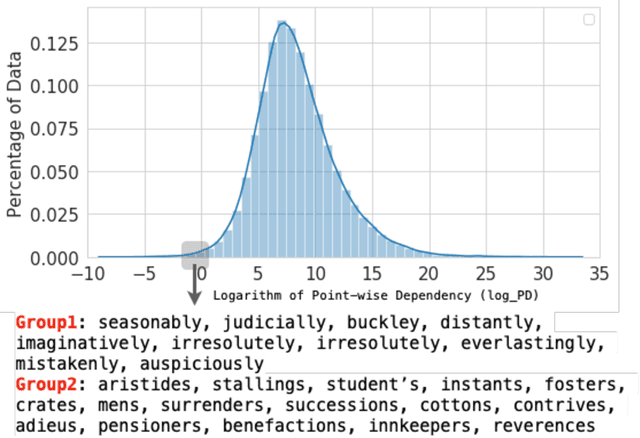
Since its inception, the neural estimation of mutual information (MI) has demonstrated the empirical success of modeling expected dependency between high-dimensional random variables. However, MI is an aggregate statistic and cannot be used to measure point-wise dependency between different events. In this work, instead of estimating the expected dependency, we focus on estimating point-wise dependency (PD), which quantitatively measures how likely two outcomes co-occur. We show that we can naturally obtain PD when we are optimizing MI neural variational bounds. However, optimizing these bounds is challenging due to its large variance in practice. To address this issue, we develop two methods (free of optimizing MI variational bounds): Probabilistic Classifier and Density-Ratio Fitting. We demonstrate the effectiveness of our approaches in 1) MI estimation, 2) self-supervised representation learning, and 3) cross-modal retrieval task.
Demystifying Self-Supervised Learning: An Information-Theoretical Framework
Jun 11, 2020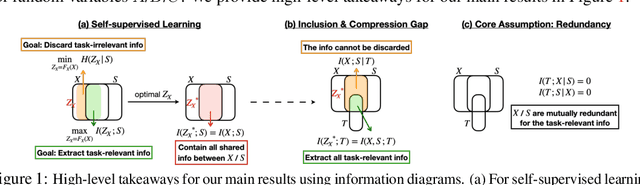
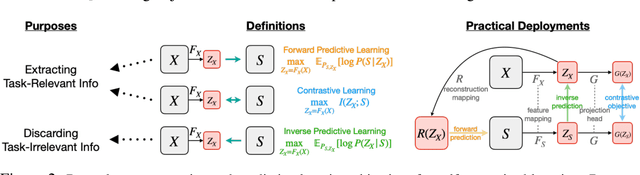
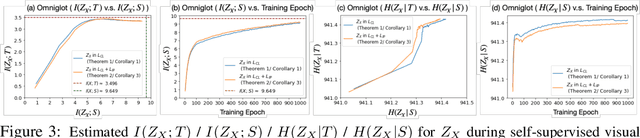

Self-supervised representation learning adopts self-defined signals as supervision and uses the learned representation for downstream tasks, such as masked language modeling (e.g., BERT) for natural language processing and contrastive visual representation learning (e.g., SimCLR) for computer vision applications. In this paper, we present a theoretical framework explaining that self-supervised learning is likely to work under the assumption that only the shared information (e.g., contextual information or content) between the input (e.g., non-masked words or original images) and self-supervised signals (e.g., masked-words or augmented images) contributes to downstream tasks. Under this assumption, we demonstrate that self-supervisedly learned representation can extract task-relevant and discard task-irrelevant information. We further connect our theoretical analysis to popular contrastive and predictive (self-supervised) learning objectives. In the experimental section, we provide controlled experiments on two popular tasks: 1) visual representation learning with various self-supervised learning objectives to empirically support our analysis; and 2) visual-textual representation learning to challenge that input and self-supervised signal lie in different modalities.