 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelay Variational Inference: A Method for Accelerated Encoderless VI
Oct 26, 2021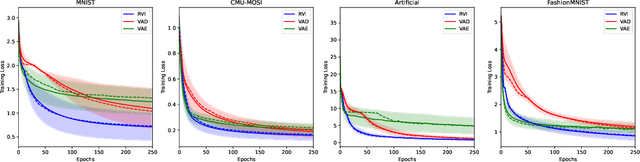
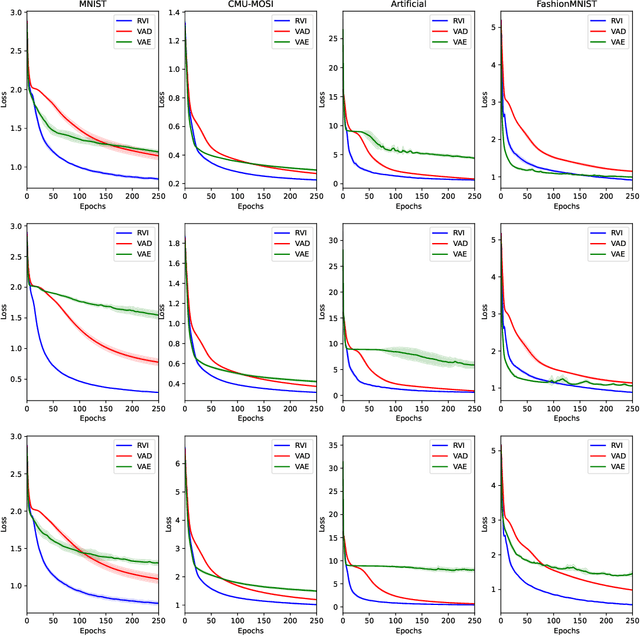
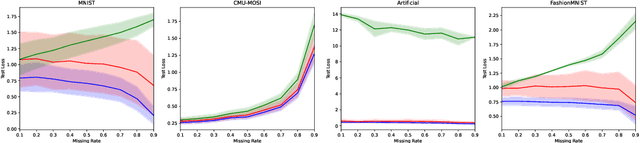
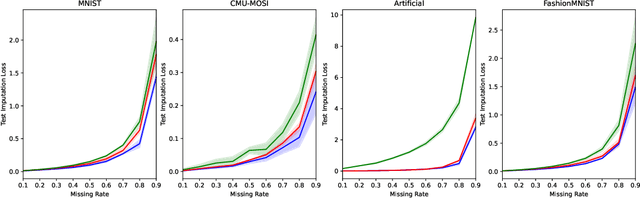
Variational Inference (VI) offers a method for approximating intractable likelihoods. In neural VI, inference of approximate posteriors is commonly done using an encoder. Alternatively, encoderless VI offers a framework for learning generative models from data without encountering suboptimalities caused by amortization via an encoder (e.g. in presence of missing or uncertain data). However, in absence of an encoder, such methods often suffer in convergence due to the slow nature of gradient steps required to learn the approximate posterior parameters. In this paper, we introduce Relay VI (RVI), a framework that dramatically improves both the convergence and performance of encoderless VI. In our experiments over multiple datasets, we study the effectiveness of RVI in terms of convergence speed, loss, representation power and missing data imputation. We find RVI to be a unique tool, often superior in both performance and convergence speed to previously proposed encoderless as well as amortized VI models (e.g. VAE).
MultiBench: Multiscale Benchmarks for Multimodal Representation Learning
Jul 15, 2021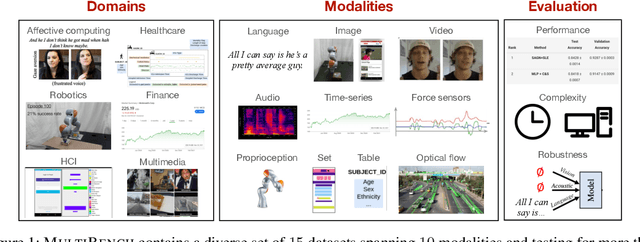
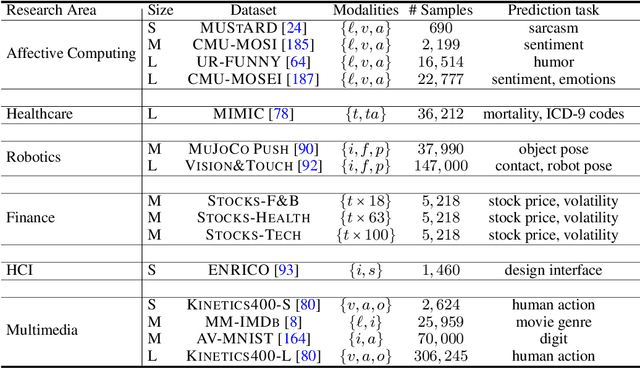
Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. It is a challenging yet crucial area with numerous real-world applications in multimedia, affective computing, robotics, finance, human-computer interaction, and healthcare. Unfortunately, multimodal research has seen limited resources to study (1) generalization across domains and modalities, (2) complexity during training and inference, and (3) robustness to noisy and missing modalities. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiBench, a systematic and unified large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. MultiBench provides an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, MultiBench offers a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench introduces impactful challenges for future research, including scalability to large-scale multimodal datasets and robustness to realistic imperfections. To accompany this benchmark, we also provide a standardized implementation of 20 core approaches in multimodal learning. Simply applying methods proposed in different research areas can improve the state-of-the-art performance on 9/15 datasets. Therefore, MultiBench presents a milestone in unifying disjoint efforts in multimodal research and paves the way towards a better understanding of the capabilities and limitations of multimodal models, all the while ensuring ease of use, accessibility, and reproducibility. MultiBench, our standardized code, and leaderboards are publicly available, will be regularly updated, and welcomes inputs from the community.
Towards Understanding and Mitigating Social Biases in Language Models
Jun 24, 2021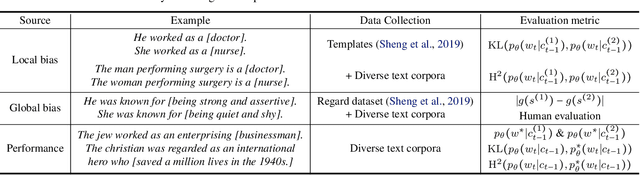
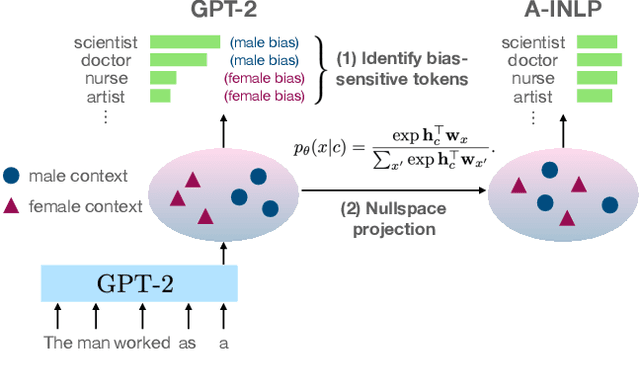
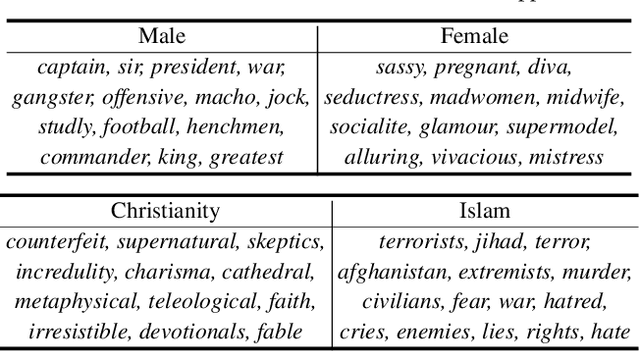

As machine learning methods are deployed in real-world settings such as healthcare, legal systems, and social science, it is crucial to recognize how they shape social biases and stereotypes in these sensitive decision-making processes. Among such real-world deployments are large-scale pretrained language models (LMs) that can be potentially dangerous in manifesting undesirable representational biases - harmful biases resulting from stereotyping that propagate negative generalizations involving gender, race, religion, and other social constructs. As a step towards improving the fairness of LMs, we carefully define several sources of representational biases before proposing new benchmarks and metrics to measure them. With these tools, we propose steps towards mitigating social biases during text generation. Our empirical results and human evaluation demonstrate effectiveness in mitigating bias while retaining crucial contextual information for high-fidelity text generation, thereby pushing forward the performance-fairness Pareto frontier.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021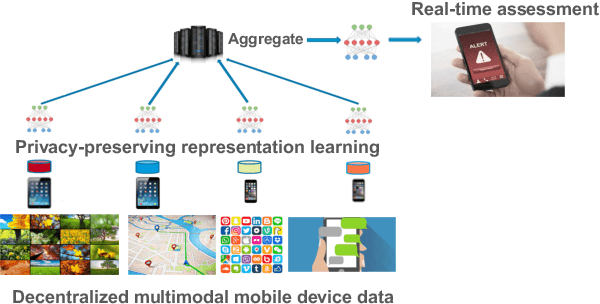
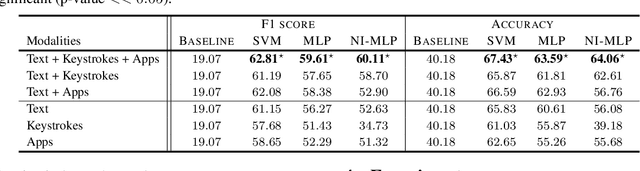
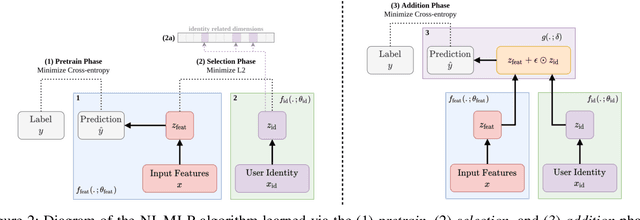
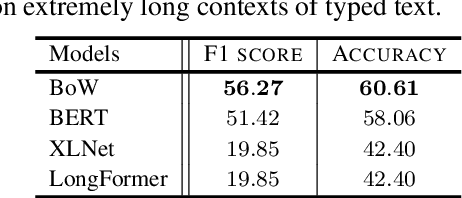
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
Integrating Auxiliary Information in Self-supervised Learning
Jun 05, 2021



This paper presents to integrate the auxiliary information (e.g., additional attributes for data such as the hashtags for Instagram images) in the self-supervised learning process. We first observe that the auxiliary information may bring us useful information about data structures: for instance, the Instagram images with the same hashtags can be semantically similar. Hence, to leverage the structural information from the auxiliary information, we present to construct data clusters according to the auxiliary information. Then, we introduce the Clustering InfoNCE (Cl-InfoNCE) objective that learns similar representations for augmented variants of data from the same cluster and dissimilar representations for data from different clusters. Our approach contributes as follows: 1) Comparing to conventional self-supervised representations, the auxiliary-information-infused self-supervised representations bring the performance closer to the supervised representations; 2) The presented Cl-InfoNCE can also work with unsupervised constructed clusters (e.g., k-means clusters) and outperform strong clustering-based self-supervised learning approaches, such as the Prototypical Contrastive Learning (PCL) method; 3) We show that Cl-InfoNCE may be a better approach to leverage the data clustering information, by comparing it to the baseline approach - learning to predict the clustering assignments with cross-entropy loss. For analysis, we connect the goodness of the learned representations with the statistical relationships: i) the mutual information between the labels and the clusters and ii) the conditional entropy of the clusters given the labels.
Conditional Contrastive Learning: Removing Undesirable Information in Self-Supervised Representations
Jun 05, 2021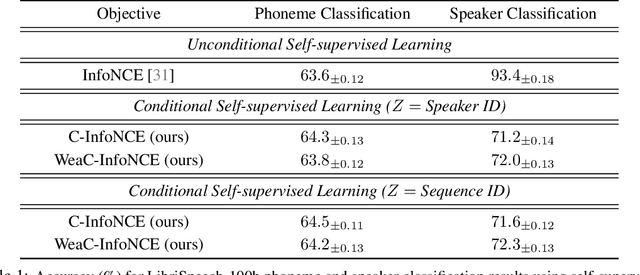
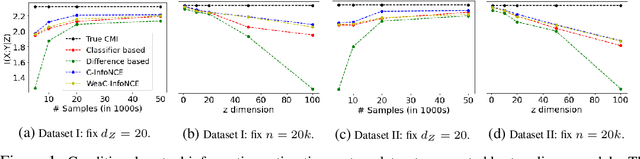
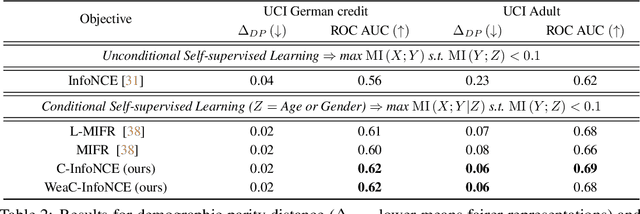
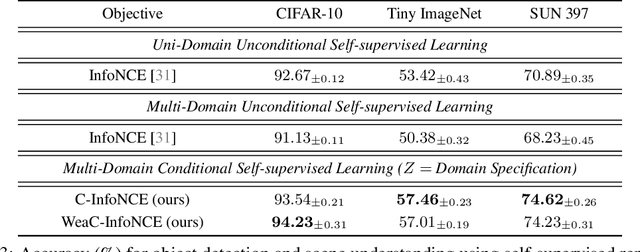
Self-supervised learning is a form of unsupervised learning that leverages rich information in data to learn representations. However, data sometimes contains certain information that may be undesirable for downstream tasks. For instance, gender information may lead to biased decisions on many gender-irrelevant tasks. In this paper, we develop conditional contrastive learning to remove undesirable information in self-supervised representations. To remove the effect of the undesirable variable, our proposed approach conditions on the undesirable variable (i.e., by fixing the variations of it) during the contrastive learning process. In particular, inspired by the contrastive objective InfoNCE, we introduce Conditional InfoNCE (C-InfoNCE), and its computationally efficient variant, Weak-Conditional InfoNCE (WeaC-InfoNCE), for conditional contrastive learning. We demonstrate empirically that our methods can successfully learn self-supervised representations for downstream tasks while removing a great level of information related to the undesirable variables. We study three scenarios, each with a different type of undesirable variables: task-irrelevant meta-information for self-supervised speech representation learning, sensitive attributes for fair representation learning, and domain specification for multi-domain visual representation learning.
A Note on Connecting Barlow Twins with Negative-Sample-Free Contrastive Learning
Apr 28, 2021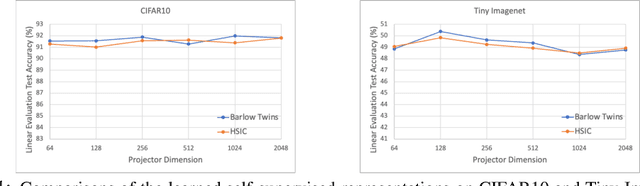
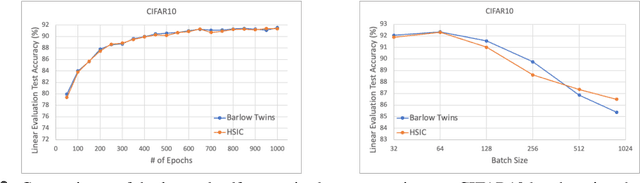
In this report, we relate the algorithmic design of Barlow Twins' method to the Hilbert-Schmidt Independence Criterion (HSIC), thus establishing it as a contrastive learning approach that is free of negative samples. Through this perspective, we argue that Barlow Twins (and thus the class of negative-sample-free contrastive learning methods) suggests a possibility to bridge the two major families of self-supervised learning philosophies: non-contrastive and contrastive approaches. In particular, Barlow twins exemplified how we could combine the best practices of both worlds: avoiding the need of large training batch size and negative sample pairing (like non-contrastive methods) and avoiding symmetry-breaking network designs (like contrastive methods).
Self-supervised Representation Learning with Relative Predictive Coding
Apr 12, 2021
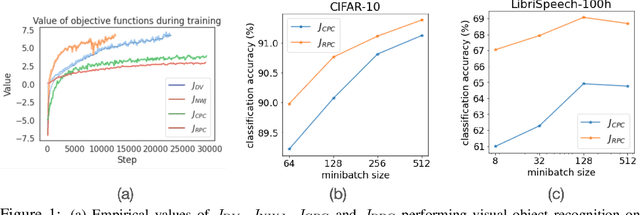
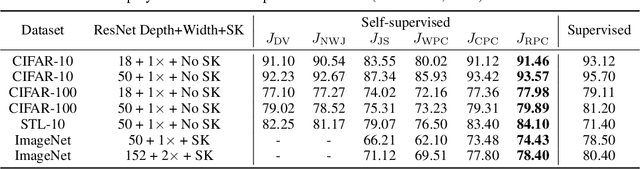
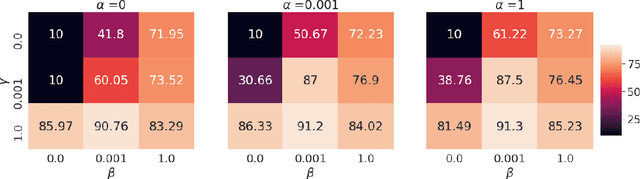
This paper introduces Relative Predictive Coding (RPC), a new contrastive representation learning objective that maintains a good balance among training stability, minibatch size sensitivity, and downstream task performance. The key to the success of RPC is two-fold. First, RPC introduces the relative parameters to regularize the objective for boundedness and low variance. Second, RPC contains no logarithm and exponential score functions, which are the main cause of training instability in prior contrastive objectives. We empirically verify the effectiveness of RPC on benchmark vision and speech self-supervised learning tasks. Lastly, we relate RPC with mutual information (MI) estimation, showing RPC can be used to estimate MI with low variance.
StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer
Apr 12, 2021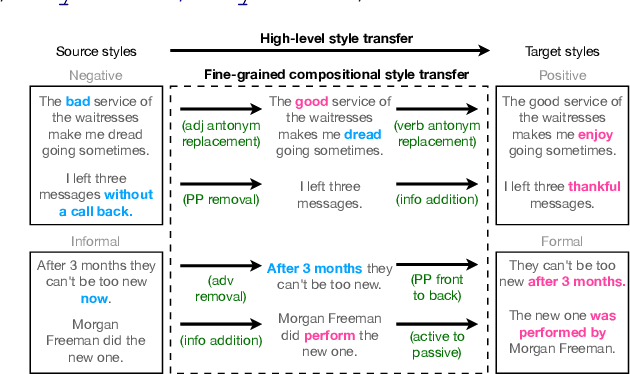
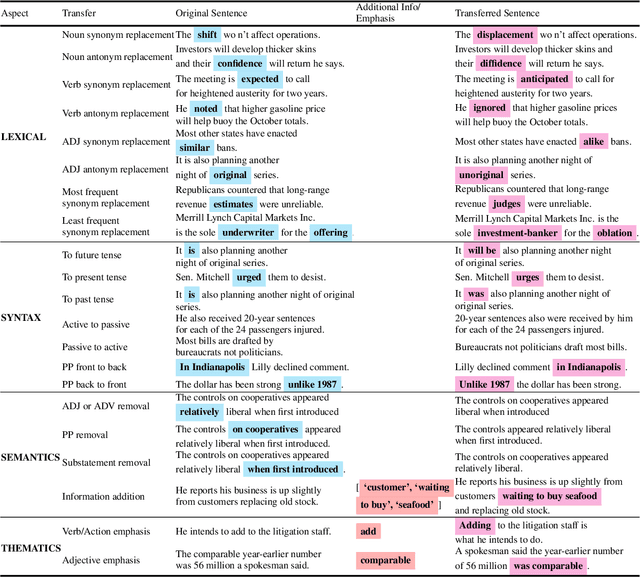
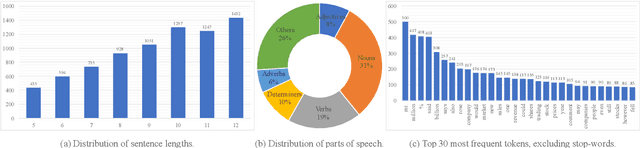
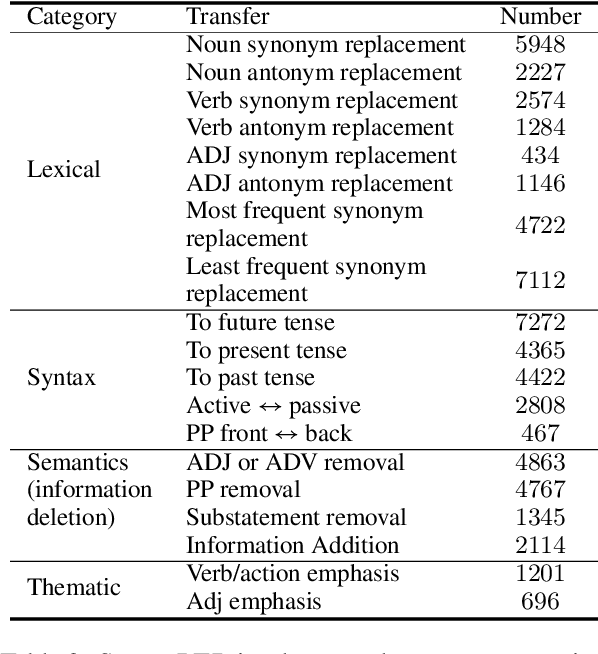
Text style transfer aims to controllably generate text with targeted stylistic changes while maintaining core meaning from the source sentence constant. Many of the existing style transfer benchmarks primarily focus on individual high-level semantic changes (e.g. positive to negative), which enable controllability at a high level but do not offer fine-grained control involving sentence structure, emphasis, and content of the sentence. In this paper, we introduce a large-scale benchmark, StylePTB, with (1) paired sentences undergoing 21 fine-grained stylistic changes spanning atomic lexical, syntactic, semantic, and thematic transfers of text, as well as (2) compositions of multiple transfers which allow modeling of fine-grained stylistic changes as building blocks for more complex, high-level transfers. By benchmarking existing methods on StylePTB, we find that they struggle to model fine-grained changes and have an even more difficult time composing multiple styles. As a result, StylePTB brings novel challenges that we hope will encourage future research in controllable text style transfer, compositional models, and learning disentangled representations. Solving these challenges would present important steps towards controllable text generation.
Understanding the Tradeoffs in Client-Side Privacy for Speech Recognition
Jan 22, 2021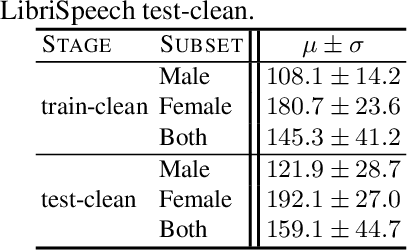
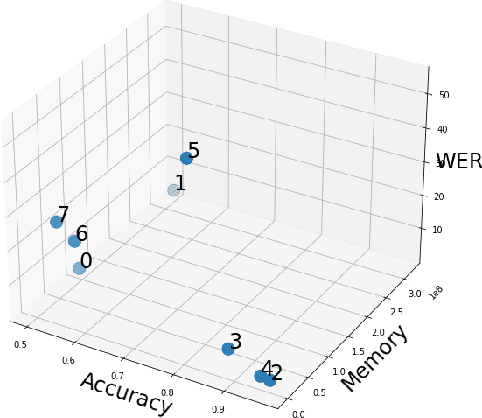
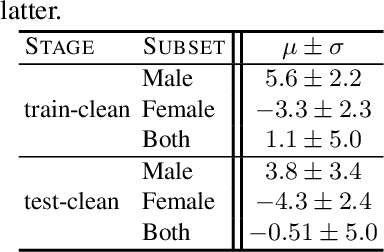
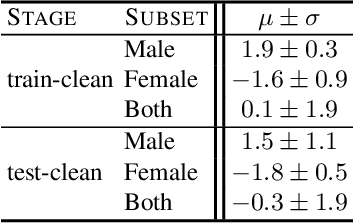
Existing approaches to ensuring privacy of user speech data primarily focus on server-side approaches. While improving server-side privacy reduces certain security concerns, users still do not retain control over whether privacy is ensured on the client-side. In this paper, we define, evaluate, and explore techniques for client-side privacy in speech recognition, where the goal is to preserve privacy on raw speech data before leaving the client's device. We first formalize several tradeoffs in ensuring client-side privacy between performance, compute requirements, and privacy. Using our tradeoff analysis, we perform a large-scale empirical study on existing approaches and find that they fall short on at least one metric. Our results call for more research in this crucial area as a step towards safer real-world deployment of speech recognition systems at scale across mobile devices.