 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Matrix Gaussian Mechanism for Differential Privacy
Apr 30, 2021
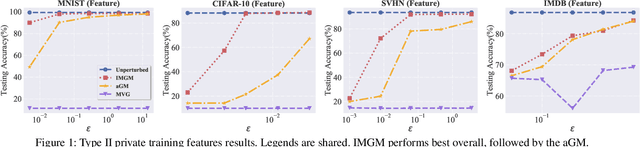
The wide deployment of machine learning in recent years gives rise to a great demand for large-scale and high-dimensional data, for which the privacy raises serious concern. Differential privacy (DP) mechanisms are conventionally developed for scalar values, not for structural data like matrices. Our work proposes Improved Matrix Gaussian Mechanism (IMGM) for matrix-valued DP, based on the necessary and sufficient condition of $ (\varepsilon,\delta) $-differential privacy. IMGM only imposes constraints on the singular values of the covariance matrices of the noise, which leaves room for design. Among the legitimate noise distributions for matrix-valued DP, we find the optimal one turns out to be i.i.d. Gaussian noise, and the DP constraint becomes a noise lower bound on each element. We further derive a tight composition method for IMGM. Apart from the theoretical analysis, experiments on a variety of models and datasets also verify that IMGM yields much higher utility than the state-of-the-art mechanisms at the same privacy guarantee.
Privacy-Preserving Federated Learning on Partitioned Attributes
Apr 29, 2021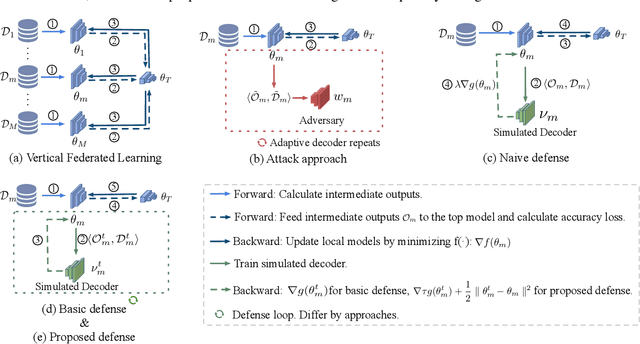

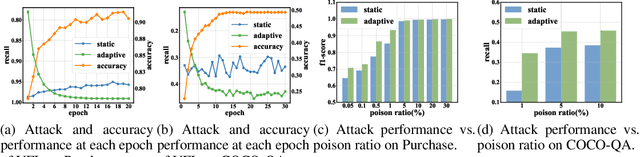
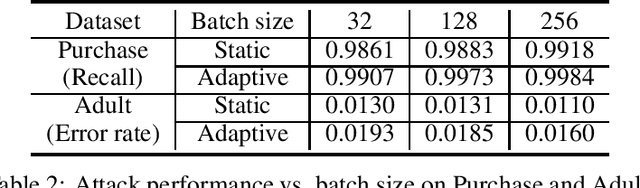
Real-world data is usually segmented by attributes and distributed across different parties. Federated learning empowers collaborative training without exposing local data or models. As we demonstrate through designed attacks, even with a small proportion of corrupted data, an adversary can accurately infer the input attributes. We introduce an adversarial learning based procedure which tunes a local model to release privacy-preserving intermediate representations. To alleviate the accuracy decline, we propose a defense method based on the forward-backward splitting algorithm, which respectively deals with the accuracy loss and privacy loss in the forward and backward gradient descent steps, achieving the two objectives simultaneously. Extensive experiments on a variety of datasets have shown that our defense significantly mitigates privacy leakage with negligible impact on the federated learning task.
A Distributional Robustness Certificate by Randomized Smoothing
Oct 21, 2020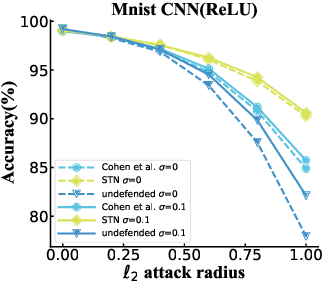

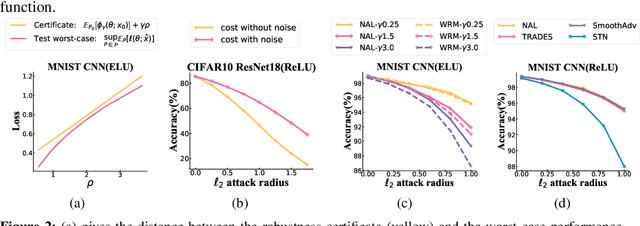
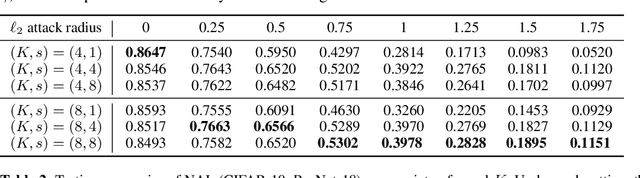
The robustness of deep neural networks against adversarial example attacks has received much attention recently. We focus on certified robustness of smoothed classifiers in this work, and propose to use the worst-case population loss over noisy inputs as a robustness metric. Under this metric, we provide a tractable upper bound serving as a robustness certificate by exploiting the duality. To improve the robustness, we further propose a noisy adversarial learning procedure to minimize the upper bound following the robust optimization framework. The smoothness of the loss function ensures the problem easy to optimize even for non-smooth neural networks. We show how our robustness certificate compares with others and the improvement over previous works. Experiments on a variety of datasets and models verify that in terms of empirical accuracies, our approach exceeds the state-of-the-art certified/heuristic methods in defending adversarial examples.
High-Order Relation Construction and Mining for Graph Matching
Oct 09, 2020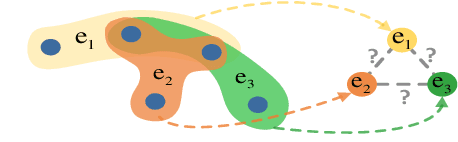
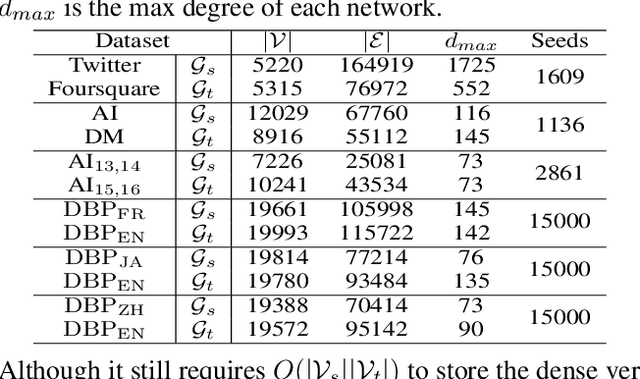
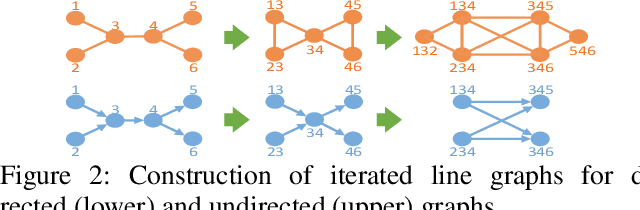
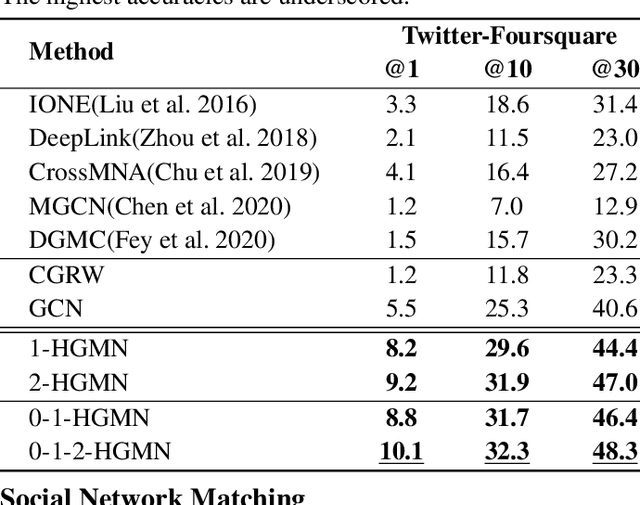
Graph matching pairs corresponding nodes across two or more graphs. The problem is difficult as it is hard to capture the structural similarity across graphs, especially on large graphs. We propose to incorporate high-order information for matching large-scale graphs. Iterated line graphs are introduced for the first time to describe such high-order information, based on which we present a new graph matching method, called High-order Graph Matching Network (HGMN), to learn not only the local structural correspondence, but also the hyperedge relations across graphs. We theoretically prove that iterated line graphs are more expressive than graph convolution networks in terms of aligning nodes. By imposing practical constraints, HGMN is made scalable to large-scale graphs. Experimental results on a variety of settings have shown that, HGMN acquires more accurate matching results than the state-of-the-art, verifying our method effectively captures the structural similarity across different graphs.
Achieving Adversarial Robustness via Sparsity
Sep 11, 2020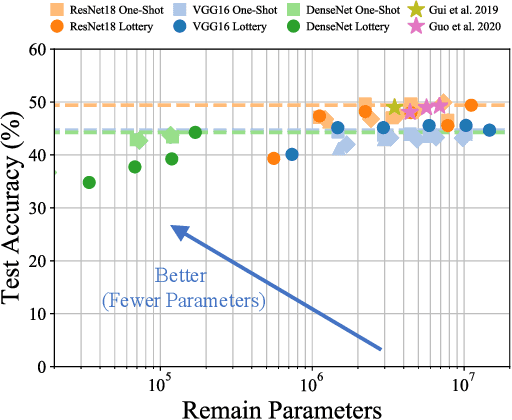
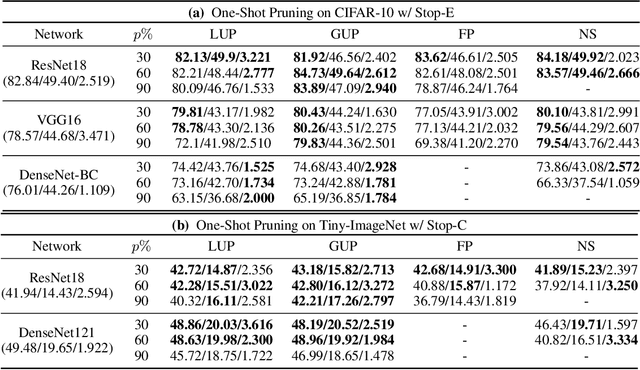
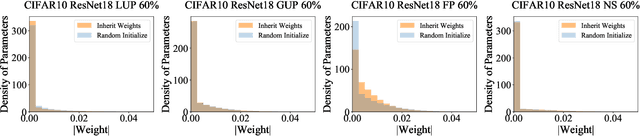

Network pruning has been known to produce compact models without much accuracy degradation. However, how the pruning process affects a network's robustness and the working mechanism behind remain unresolved. In this work, we theoretically prove that the sparsity of network weights is closely associated with model robustness. Through experiments on a variety of adversarial pruning methods, we find that weights sparsity will not hurt but improve robustness, where both weights inheritance from the lottery ticket and adversarial training improve model robustness in network pruning. Based on these findings, we propose a novel adversarial training method called inverse weights inheritance, which imposes sparse weights distribution on a large network by inheriting weights from a small network, thereby improving the robustness of the large network.
Rotation-Equivariant Neural Networks for Privacy Protection
Jun 21, 2020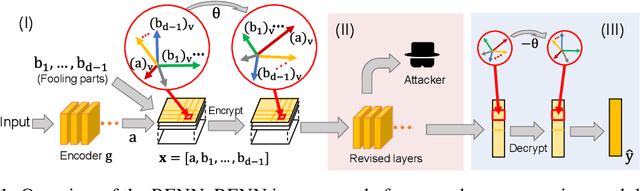
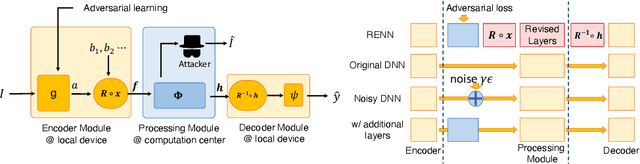
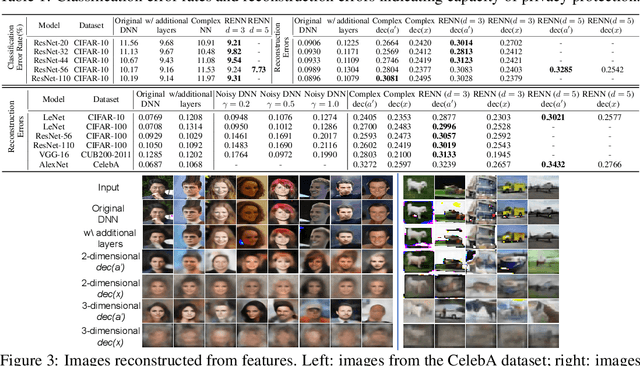
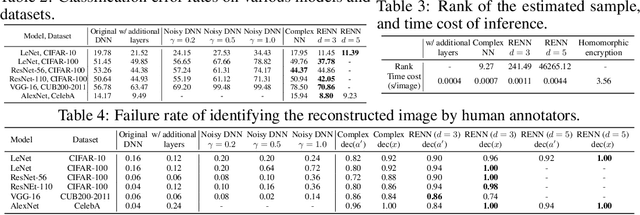
In order to prevent leaking input information from intermediate-layer features, this paper proposes a method to revise the traditional neural network into the rotation-equivariant neural network (RENN). Compared to the traditional neural network, the RENN uses d-ary vectors/tensors as features, in which each element is a d-ary number. These d-ary features can be rotated (analogous to the rotation of a d-dimensional vector) with a random angle as the encryption process. Input information is hidden in this target phase of d-ary features for attribute obfuscation. Even if attackers have obtained network parameters and intermediate-layer features, they cannot extract input information without knowing the target phase. Hence, the input privacy can be effectively protected by the RENN. Besides, the output accuracy of RENNs only degrades mildly compared to traditional neural networks, and the computational cost is significantly less than the homomorphic encryption.
Deep Quaternion Features for Privacy Protection
Mar 18, 2020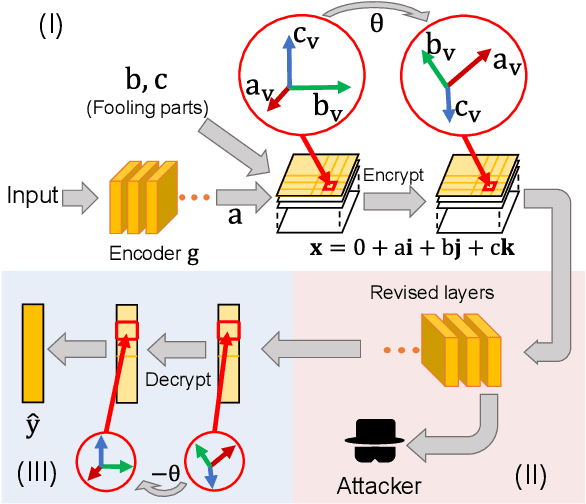
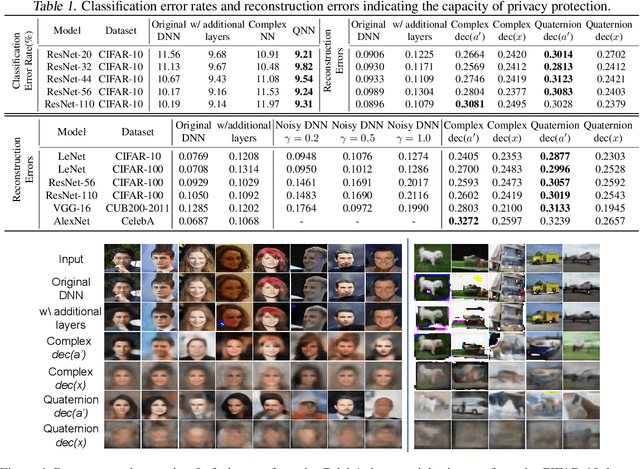
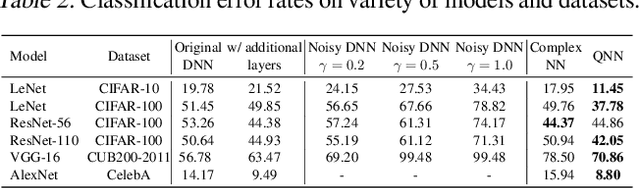
We propose a method to revise the neural network to construct the quaternion-valued neural network (QNN), in order to prevent intermediate-layer features from leaking input information. The QNN uses quaternion-valued features, where each element is a quaternion. The QNN hides input information into a random phase of quaternion-valued features. Even if attackers have obtained network parameters and intermediate-layer features, they cannot extract input information without knowing the target phase. In this way, the QNN can effectively protect the input privacy. Besides, the output accuracy of QNNs only degrades mildly compared to traditional neural networks, and the computational cost is much less than other privacy-preserving methods.
Preventing Information Leakage with Neural Architecture Search
Dec 18, 2019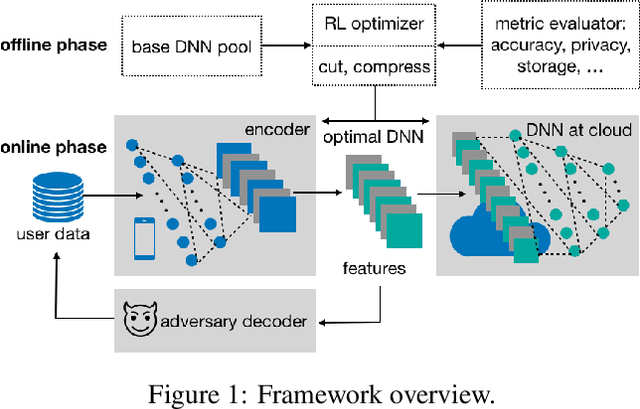
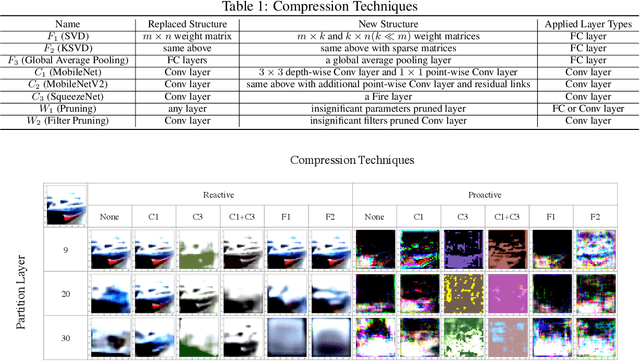
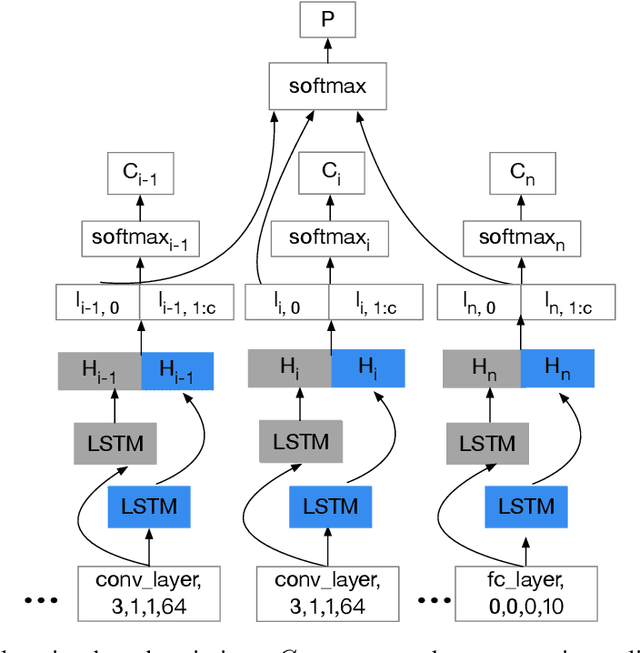
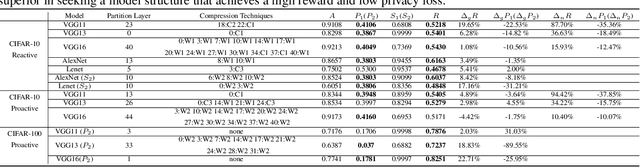
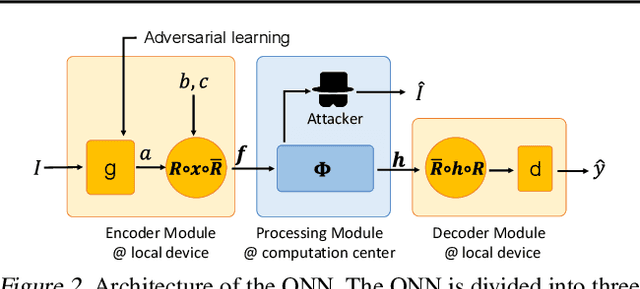
Powered by machine learning services in the cloud, numerous learning-driven mobile applications are gaining popularity in the market. As deep learning tasks are mostly computation-intensive, it has become a trend to process raw data on devices and send the neural network features to the cloud, whereas the part of the neural network residing in the cloud completes the task to return final results. However, there is always the potential for unexpected leakage with the release of features, with which an adversary could infer a significant amount of information about the original data. To address this problem, we propose a privacy-preserving deep learning framework on top of the mobile cloud infrastructure: the trained deep neural network is tailored to prevent information leakage through features while maintaining highly accurate results. In essence, we learn the strategy to prevent leakage by modifying the trained deep neural network against a generic opponent, who infers unintended information from released features and auxiliary data, while preserving the accuracy of the model as much as possible.
Complex-Valued Neural Networks for Privacy Protection
Jan 28, 2019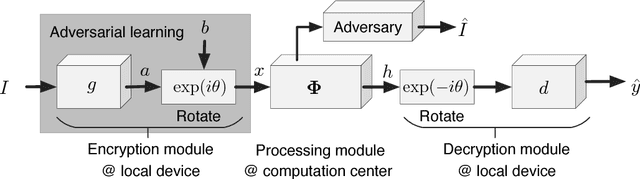
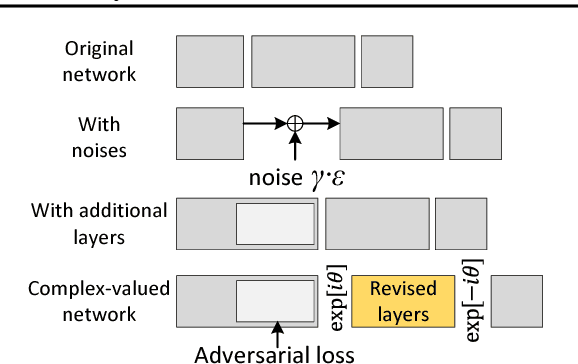
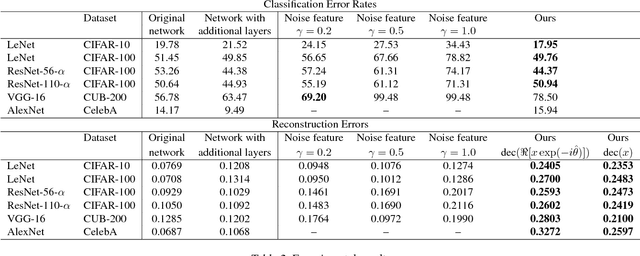
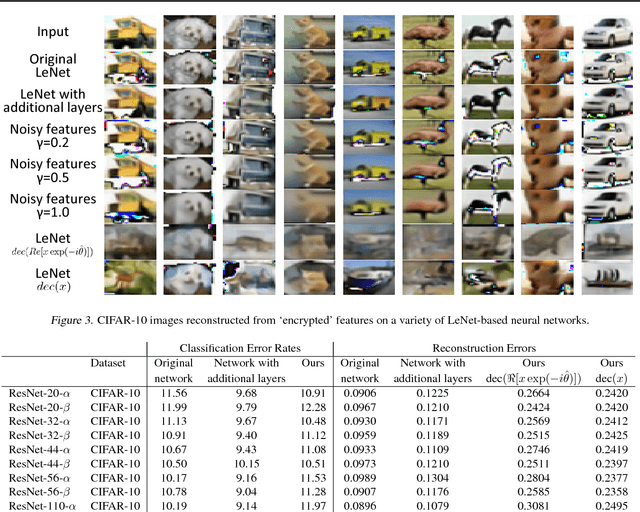
This paper proposes a generic method to revise traditional neural networks for privacy protection. Our method is designed to prevent inversion attacks, i.e., avoiding recovering private information from intermediate-layer features of a neural network. Our method transforms real-valued features of an intermediate layer into complex-valued features, in which private information is hidden in a random phase of the transformed features. To prevent the adversary from recovering the phase, we adopt an adversarial-learning algorithm to generate the complex-valued feature. More crucially, the transformed feature can be directly processed by the deep neural network, but without knowing the true phase, people cannot recover either the input information or the prediction result. Preliminary experiments with various neural networks (including the LeNet, the VGG, and residual networks) on different datasets have shown that our method can successfully defend feature inversion attacks while preserving learning accuracy.