 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Instance Refinement for Cross-domain Action Recognition
Nov 24, 2023



Unsupervised cross-domain action recognition aims at adapting the model trained on an existing labeled source domain to a new unlabeled target domain. Most existing methods solve the task by directly aligning the feature distributions of source and target domains. However, this would cause negative transfer during domain adaptation due to some negative training samples in both domains. In the source domain, some training samples are of low-relevance to target domain due to the difference in viewpoints, action styles, etc. In the target domain, there are some ambiguous training samples that can be easily classified as another type of action under the case of source domain. The problem of negative transfer has been explored in cross-domain object detection, while it remains under-explored in cross-domain action recognition. Therefore, we propose a Multi-modal Instance Refinement (MMIR) method to alleviate the negative transfer based on reinforcement learning. Specifically, a reinforcement learning agent is trained in both domains for every modality to refine the training data by selecting out negative samples from each domain. Our method finally outperforms several other state-of-the-art baselines in cross-domain action recognition on the benchmark EPIC-Kitchens dataset, which demonstrates the advantage of MMIR in reducing negative transfer.
Learning Motion Refinement for Unsupervised Face Animation
Oct 21, 2023Unsupervised face animation aims to generate a human face video based on the appearance of a source image, mimicking the motion from a driving video. Existing methods typically adopted a prior-based motion model (e.g., the local affine motion model or the local thin-plate-spline motion model). While it is able to capture the coarse facial motion, artifacts can often be observed around the tiny motion in local areas (e.g., lips and eyes), due to the limited ability of these methods to model the finer facial motions. In this work, we design a new unsupervised face animation approach to learn simultaneously the coarse and finer motions. In particular, while exploiting the local affine motion model to learn the global coarse facial motion, we design a novel motion refinement module to compensate for the local affine motion model for modeling finer face motions in local areas. The motion refinement is learned from the dense correlation between the source and driving images. Specifically, we first construct a structure correlation volume based on the keypoint features of the source and driving images. Then, we train a model to generate the tiny facial motions iteratively from low to high resolution. The learned motion refinements are combined with the coarse motion to generate the new image. Extensive experiments on widely used benchmarks demonstrate that our method achieves the best results among state-of-the-art baselines.
HFGD: High-level Feature Guided Decoder for Semantic Segmentation
Mar 15, 2023Commonly used backbones for semantic segmentation, such as ResNet and Swin-Transformer, have multiple stages for feature encoding. Simply using high-resolution low-level feature maps from the early stages of the backbone to directly refine the low-resolution high-level feature map is a common practice of low-resolution feature map upsampling. However, the representation power of the low-level features is generally worse than high-level features, thus introducing ``noise" to the upsampling refinement. To address this issue, we proposed High-level Feature Guided Decoder (HFGD), which uses isolated high-level features to guide low-level features and upsampling process. Specifically, the guidance is realized through carefully designed stop gradient operations and class kernels. Now the class kernels co-evolve only with the high-level features and are reused in the upsampling head to guide the training process of the upsampling head. HFGD is very efficient and effective that can also upsample the feature maps to a previously unseen output stride (OS) of 2 and still obtain accuracy gain. HFGD demonstrates state-of-the-art performance on several benchmark datasets (e.g. Pascal Context, COCOStuff164k and Cityscapes) with small FLOPs. The full code will be available at https://github.com/edwardyehuang/HFGD.git.
CARD: Semantic Segmentation with Efficient Class-Aware Regularized Decoder
Jan 11, 2023



Semantic segmentation has recently achieved notable advances by exploiting "class-level" contextual information during learning. However, these approaches simply concatenate class-level information to pixel features to boost the pixel representation learning, which cannot fully utilize intra-class and inter-class contextual information. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. To better exploit class level information, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Moreover, we design a dedicated decoder for CAR (CARD), which consists of a novel spatial token mixer and an upsampling module, to maximize its gain for existing baselines while being highly efficient in terms of computational cost. Specifically, CAR consists of three novel loss functions. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. CAR can be directly applied to most existing segmentation models during training, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. CARD outperforms SOTA approaches on multiple benchmarks with a highly efficient architecture.
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks
Dec 18, 2022



In this work, we study the black-box targeted attack problem from the model discrepancy perspective. On the theoretical side, we present a generalization error bound for black-box targeted attacks, which gives a rigorous theoretical analysis for guaranteeing the success of the attack. We reveal that the attack error on a target model mainly depends on empirical attack error on the substitute model and the maximum model discrepancy among substitute models. On the algorithmic side, we derive a new algorithm for black-box targeted attacks based on our theoretical analysis, in which we additionally minimize the maximum model discrepancy(M3D) of the substitute models when training the generator to generate adversarial examples. In this way, our model is capable of crafting highly transferable adversarial examples that are robust to the model variation, thus improving the success rate for attacking the black-box model. We conduct extensive experiments on the ImageNet dataset with different classification models, and our proposed approach outperforms existing state-of-the-art methods by a significant margin. Our codes will be released.
Multi-rater Prism: Learning self-calibrated medical image segmentation from multiple raters
Dec 01, 2022



In medical image segmentation, it is often necessary to collect opinions from multiple experts to make the final decision. This clinical routine helps to mitigate individual bias. But when data is multiply annotated, standard deep learning models are often not applicable. In this paper, we propose a novel neural network framework, called Multi-Rater Prism (MrPrism) to learn the medical image segmentation from multiple labels. Inspired by the iterative half-quadratic optimization, the proposed MrPrism will combine the multi-rater confidences assignment task and calibrated segmentation task in a recurrent manner. In this recurrent process, MrPrism can learn inter-observer variability taking into account the image semantic properties, and finally converges to a self-calibrated segmentation result reflecting the inter-observer agreement. Specifically, we propose Converging Prism (ConP) and Diverging Prism (DivP) to process the two tasks iteratively. ConP learns calibrated segmentation based on the multi-rater confidence maps estimated by DivP. DivP generates multi-rater confidence maps based on the segmentation masks estimated by ConP. The experimental results show that by recurrently running ConP and DivP, the two tasks can achieve mutual improvement. The final converged segmentation result of MrPrism outperforms state-of-the-art (SOTA) strategies on a wide range of medical image segmentation tasks.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022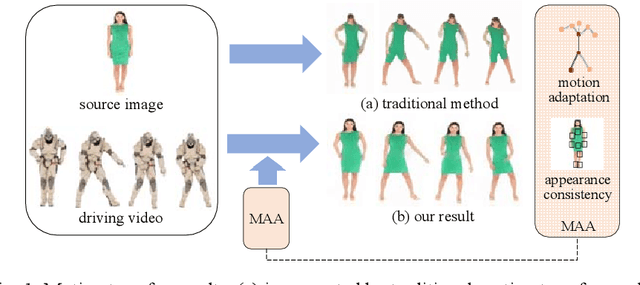
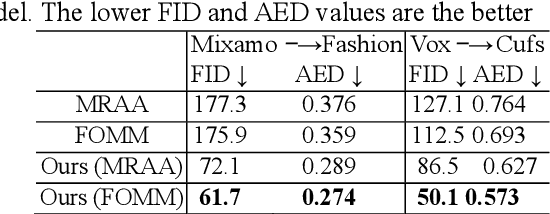
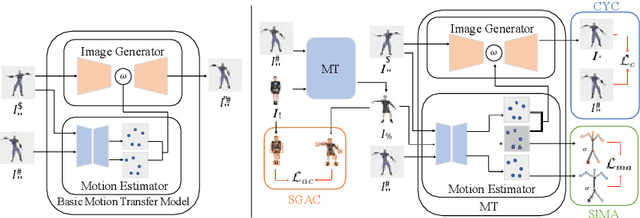
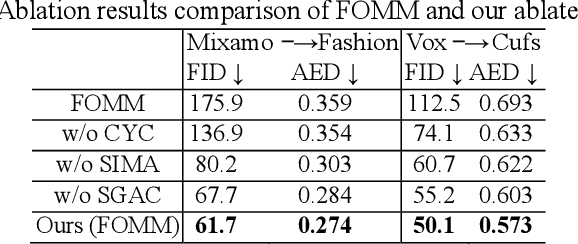
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Motion Transformer for Unsupervised Image Animation
Sep 28, 2022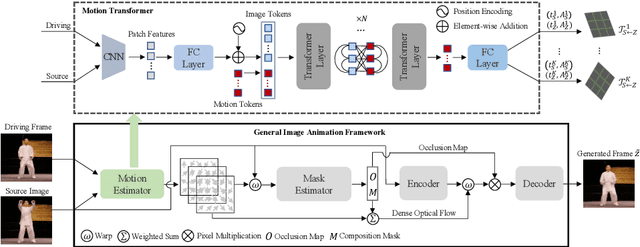
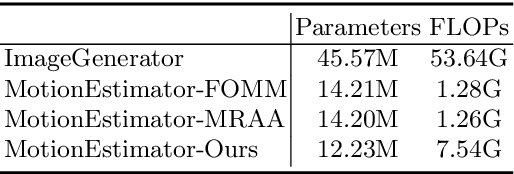


Image animation aims to animate a source image by using motion learned from a driving video. Current state-of-the-art methods typically use convolutional neural networks (CNNs) to predict motion information, such as motion keypoints and corresponding local transformations. However, these CNN based methods do not explicitly model the interactions between motions; as a result, the important underlying motion relationship may be neglected, which can potentially lead to noticeable artifacts being produced in the generated animation video. To this end, we propose a new method, the motion transformer, which is the first attempt to build a motion estimator based on a vision transformer. More specifically, we introduce two types of tokens in our proposed method: i) image tokens formed from patch features and corresponding position encoding; and ii) motion tokens encoded with motion information. Both types of tokens are sent into vision transformers to promote underlying interactions between them through multi-head self attention blocks. By adopting this process, the motion information can be better learned to boost the model performance. The final embedded motion tokens are then used to predict the corresponding motion keypoints and local transformations. Extensive experiments on benchmark datasets show that our proposed method achieves promising results to the state-of-the-art baselines. Our source code will be public available.
Calibrate the inter-observer segmentation uncertainty via diagnosis-first principle
Aug 05, 2022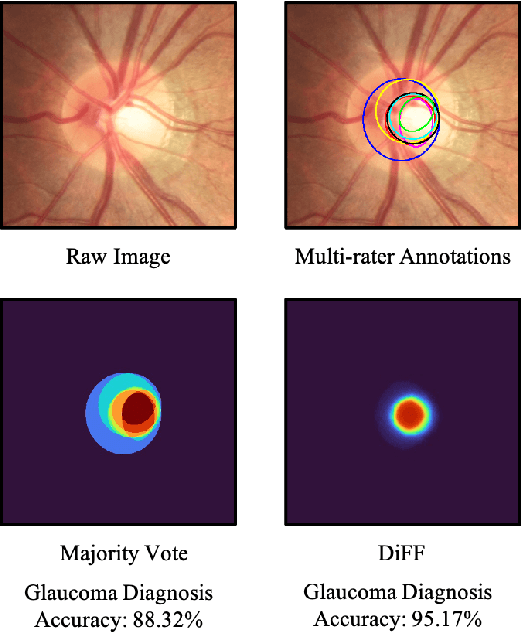
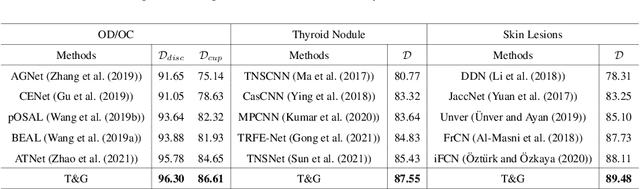
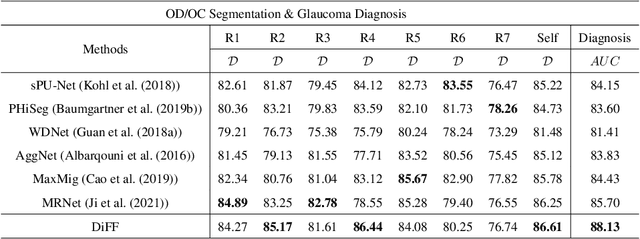
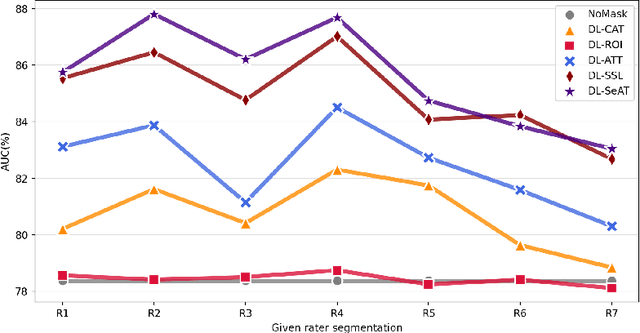
On the medical images, many of the tissues/lesions may be ambiguous. That is why the medical segmentation is typically annotated by a group of clinical experts to mitigate the personal bias. However, this clinical routine also brings new challenges to the application of machine learning algorithms. Without a definite ground-truth, it will be difficult to train and evaluate the deep learning models. When the annotations are collected from different graders, a common choice is majority vote. However such a strategy ignores the difference between the grader expertness. In this paper, we consider the task of predicting the segmentation with the calibrated inter-observer uncertainty. We note that in clinical practice, the medical image segmentation is usually used to assist the disease diagnosis. Inspired by this observation, we propose diagnosis-first principle, which is to take disease diagnosis as the criterion to calibrate the inter-observer segmentation uncertainty. Following this idea, a framework named Diagnosis First segmentation Framework (DiFF) is proposed to estimate diagnosis-first segmentation from the raw images.Specifically, DiFF will first learn to fuse the multi-rater segmentation labels to a single ground-truth which could maximize the disease diagnosis performance. We dubbed the fused ground-truth as Diagnosis First Ground-truth (DF-GT).Then, we further propose Take and Give Modelto segment DF-GT from the raw image. We verify the effectiveness of DiFF on three different medical segmentation tasks: OD/OC segmentation on fundus images, thyroid nodule segmentation on ultrasound images, and skin lesion segmentation on dermoscopic images. Experimental results show that the proposed DiFF is able to significantly facilitate the corresponding disease diagnosis, which outperforms previous state-of-the-art multi-rater learning methods.
Cross-domain Detection Transformer based on Spatial-aware and Semantic-aware Token Alignment
Jun 01, 2022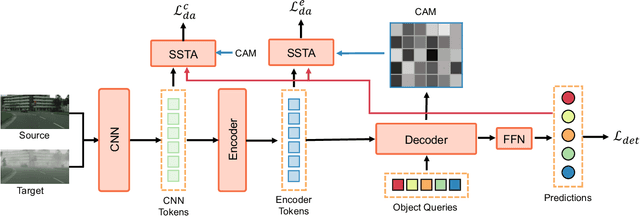
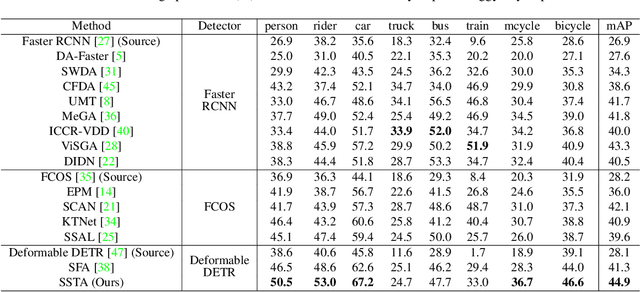
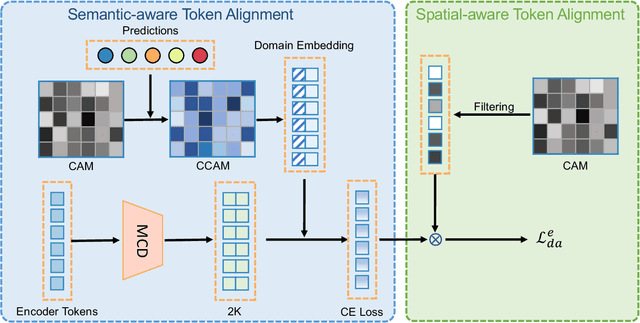
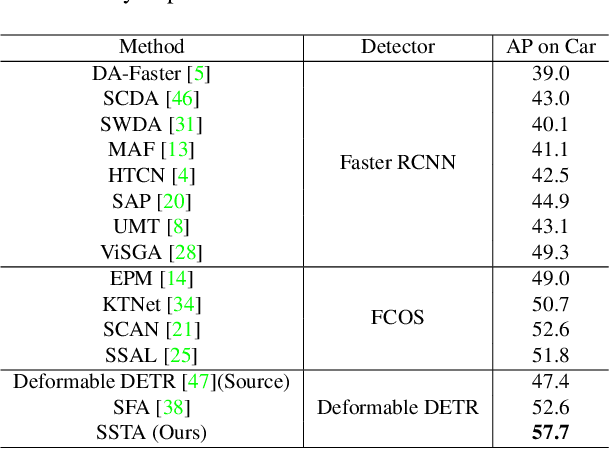
Detection transformers like DETR have recently shown promising performance on many object detection tasks, but the generalization ability of those methods is still quite challenging for cross-domain adaptation scenarios. To address the cross-domain issue, a straightforward way is to perform token alignment with adversarial training in transformers. However, its performance is often unsatisfactory as the tokens in detection transformers are quite diverse and represent different spatial and semantic information. In this paper, we propose a new method called Spatial-aware and Semantic-aware Token Alignment (SSTA) for cross-domain detection transformers. In particular, we take advantage of the characteristics of cross-attention as used in detection transformer and propose the spatial-aware token alignment (SpaTA) and the semantic-aware token alignment (SemTA) strategies to guide the token alignment across domains. For spatial-aware token alignment, we can extract the information from the cross-attention map (CAM) to align the distribution of tokens according to their attention to object queries. For semantic-aware token alignment, we inject the category information into the cross-attention map and construct domain embedding to guide the learning of a multi-class discriminator so as to model the category relationship and achieve category-level token alignment during the entire adaptation process. We conduct extensive experiments on several widely-used benchmarks, and the results clearly show the effectiveness of our proposed method over existing state-of-the-art baselines.