 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo2Sim2Real: Full-Stack Autonomous Dexterous Skill Acquisition from a Single Human Video
Jun 07, 2026Human manipulation videos are a convenient and intuitive source for robot learning. However, directly transferring human dexterity to robots remains challenging due to perception errors and embodiment gap. To address this, we introduce Video2Sim2Real, a full-stack framework for autonomous skill acquisition from a single human manipulation video. Our framework first uses off-the-shelf foundation models to reconstruct a simulator-ready digital twin and extract robot and object motion priors. Rather than treating the extracted robot motion as a reliable reference throughout execution, our key idea is to recover and leverage the most fundamental sources of supervision from the demonstrated skill: We identify object-centric keyframes to optimize the corresponding robot configurations using object information from the simulator, and use these configurations as anchors that refine the robot motion such that it ultimately has the desired impact on the environment. To bridge the remaining sim-to-real gap, we introduce a sim-to-real strategy that decouples robustness to noisy and incomplete perception from variations in hand-object interaction dynamics. Specifically, we learn to recalibrate robot configurations from noisy real-world point clouds via IL, and leverage residual RL to perform local finger-level adaptations to ensure for robust and effective interactions. Finally, a collision-aware motion planning module enables spatial generalization to novel object configurations. Across several everyday manipulation tasks, Video2Sim2Real improves simulated task success, safety, and trajectory coherence over numerous baselines, and achieves better sim-to-real transfer than existing techniques. These results demonstrate a promising path toward autonomous dexterous skill acquisition from human videos.
AGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
Mar 20, 2026Recent advances in reinforcement learning (RL) have enabled impressive humanoid behaviors in simulation, yet transferring these results to new robots remains challenging. In many real deployments, the primary bottleneck is no longer simulation throughput or algorithm design, but the absence of systematic infrastructure that links environment verification, training, evaluation, and deployment in a coherent loop. To address this gap, we present AGILE, an end-to-end workflow for humanoid RL that standardizes the policy-development lifecycle to mitigate common sim-to-real failure modes. AGILE comprises four stages: (1) interactive environment verification, (2) reproducible training, (3) unified evaluation, and (4) descriptor-driven deployment via robot/task configuration descriptors. For evaluation stage, AGILE supports both scenario-based tests and randomized rollouts under a shared suite of motion-quality diagnostics, enabling automated regression testing and principled robustness assessment. AGILE also incorporates a set of training stabilizations and algorithmic enhancements in training stage to improve optimization stability and sim-to-real transfer. With this pipeline in place, we validate AGILE across five representative humanoid skills spanning locomotion, recovery, motion imitation, and loco-manipulation on two hardware platforms (Unitree G1 and Booster T1), achieving consistent sim-to-real transfer. Overall, AGILE shows that a standardized, end-to-end workflow can substantially improve the reliability and reproducibility of humanoid RL development.
D2M: A Decentralized, Privacy-Preserving, Incentive-Compatible Data Marketplace for Collaborative Learning
Dec 11, 2025The rising demand for collaborative machine learning and data analytics calls for secure and decentralized data sharing frameworks that balance privacy, trust, and incentives. Existing approaches, including federated learning (FL) and blockchain-based data markets, fall short: FL often depends on trusted aggregators and lacks Byzantine robustness, while blockchain frameworks struggle with computation-intensive training and incentive integration. We present \prot, a decentralized data marketplace that unifies federated learning, blockchain arbitration, and economic incentives into a single framework for privacy-preserving data sharing. \prot\ enables data buyers to submit bid-based requests via blockchain smart contracts, which manage auctions, escrow, and dispute resolution. Computationally intensive training is delegated to \cone\ (\uline{Co}mpute \uline{N}etwork for \uline{E}xecution), an off-chain distributed execution layer. To safeguard against adversarial behavior, \prot\ integrates a modified YODA protocol with exponentially growing execution sets for resilient consensus, and introduces Corrected OSMD to mitigate malicious or low-quality contributions from sellers. All protocols are incentive-compatible, and our game-theoretic analysis establishes honesty as the dominant strategy. We implement \prot\ on Ethereum and evaluate it over benchmark datasets -- MNIST, Fashion-MNIST, and CIFAR-10 -- under varying adversarial settings. \prot\ achieves up to 99\% accuracy on MNIST and 90\% on Fashion-MNIST, with less than 3\% degradation up to 30\% Byzantine nodes, and 56\% accuracy on CIFAR-10 despite its complexity. Our results show that \prot\ ensures privacy, maintains robustness under adversarial conditions, and scales efficiently with the number of participants, making it a practical foundation for real-world decentralized data sharing.
Learning Flexible Heterogeneous Coordination with Capability-Aware Shared Hypernetworks
Jan 10, 2025
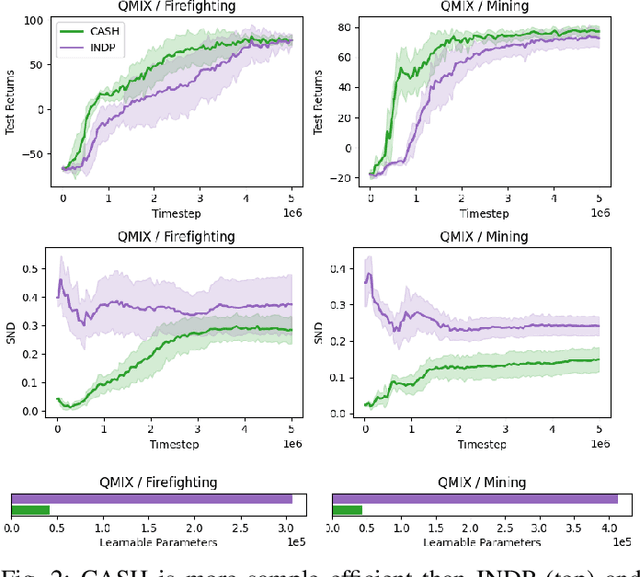

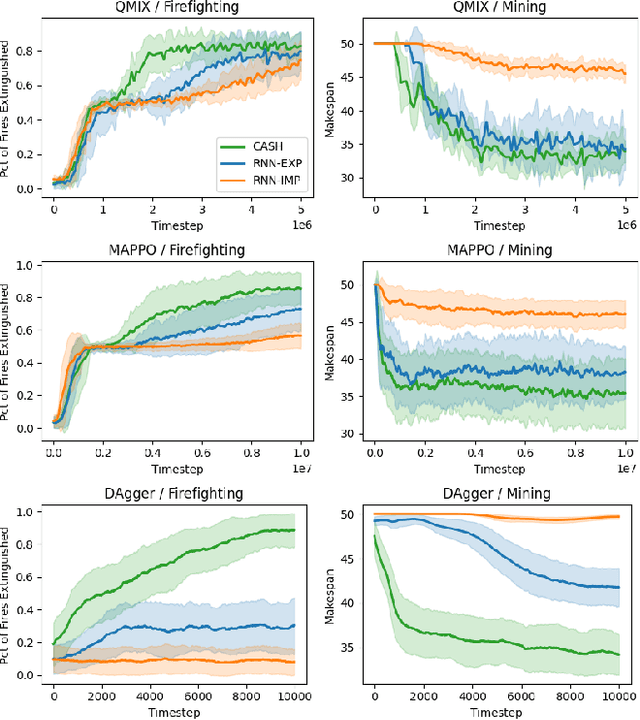
Cooperative heterogeneous multi-agent tasks require agents to effectively coordinate their behaviors while accounting for their relative capabilities. Learning-based solutions to this challenge span between two extremes: i) shared-parameter methods, which encode diverse behaviors within a single architecture by assigning an ID to each agent, and are sample-efficient but result in limited behavioral diversity; ii) independent methods, which learn a separate policy for each agent, and show greater behavioral diversity but lack sample-efficiency. Prior work has also explored selective parameter-sharing, allowing for a compromise between diversity and efficiency. None of these approaches, however, effectively generalize to unseen agents or teams. We present Capability-Aware Shared Hypernetworks (CASH), a novel architecture for heterogeneous multi-agent coordination that generates sufficient diversity while maintaining sample-efficiency via soft parameter-sharing hypernetworks. Intuitively, CASH allows the team to learn common strategies using a shared encoder, which are then adapted according to the team's individual and collective capabilities with a hypernetwork, allowing for zero-shot generalization to unseen teams and agents. We present experiments across two heterogeneous coordination tasks and three standard learning paradigms (imitation learning, on- and off-policy reinforcement learning). CASH is able to outperform baseline architectures in success rate and sample efficiency when evaluated on unseen teams and agents despite using less than half of the learnable parameters.