 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-PRO: Enhancing Instance-Specific Object Detection with Full-Channel Global Self-Attention
Mar 04, 2025



This paper addresses the inherent limitations of conventional bottleneck structures (diminished instance discriminability due to overemphasis on batch statistics) and decoupled heads (computational redundancy) in object detection frameworks by proposing two novel modules: the Instance-Specific Bottleneck with full-channel global self-attention (ISB) and the Instance-Specific Asymmetric Decoupled Head (ISADH). The ISB module innovatively reconstructs feature maps to establish an efficient full-channel global attention mechanism through synergistic fusion of batch-statistical and instance-specific features. Complementing this, the ISADH module pioneers an asymmetric decoupled architecture enabling hierarchical multi-dimensional feature integration via dual-stream batch-instance representation fusion. Extensive experiments on the MS-COCO benchmark demonstrate that the coordinated deployment of ISB and ISADH in the YOLO-PRO framework achieves state-of-the-art performance across all computational scales. Specifically, YOLO-PRO surpasses YOLOv8 by 1.0-1.6% AP (N/S/M/L/X scales) and outperforms YOLO11 by 0.1-0.5% AP in critical M/L/X groups, while maintaining competitive computational efficiency. This work provides practical insights for developing high-precision detectors deployable on edge devices.
MedKAN: An Advanced Kolmogorov-Arnold Network for Medical Image Classification
Feb 25, 2025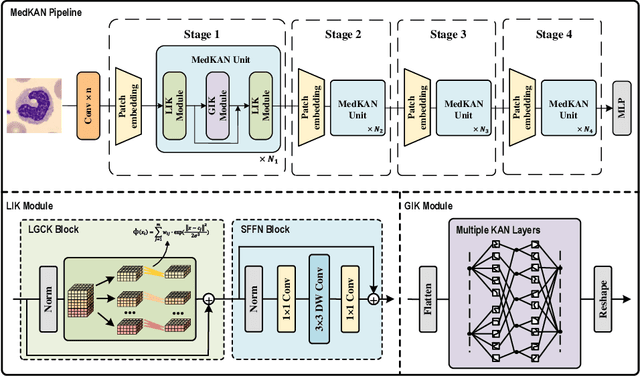
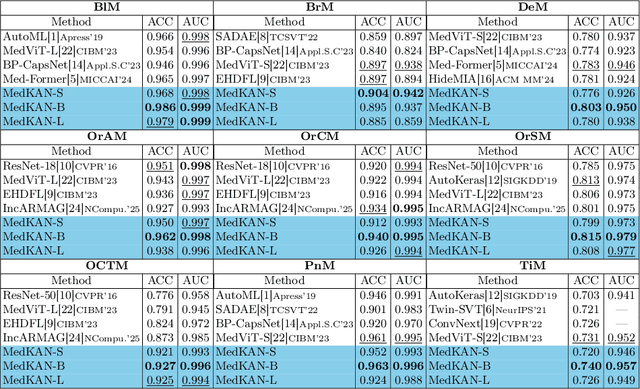
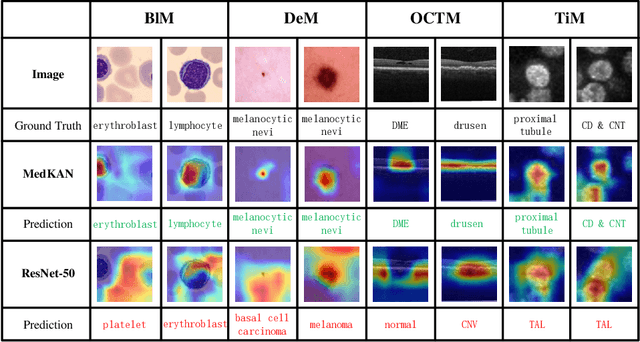
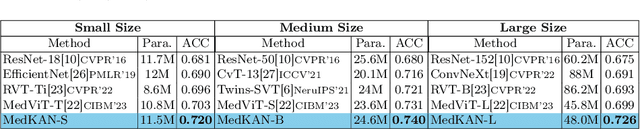
Recent advancements in deep learning for image classification predominantly rely on convolutional neural networks (CNNs) or Transformer-based architectures. However, these models face notable challenges in medical imaging, particularly in capturing intricate texture details and contextual features. Kolmogorov-Arnold Networks (KANs) represent a novel class of architectures that enhance nonlinear transformation modeling, offering improved representation of complex features. In this work, we present MedKAN, a medical image classification framework built upon KAN and its convolutional extensions. MedKAN features two core modules: the Local Information KAN (LIK) module for fine-grained feature extraction and the Global Information KAN (GIK) module for global context integration. By combining these modules, MedKAN achieves robust feature modeling and fusion. To address diverse computational needs, we introduce three scalable variants--MedKAN-S, MedKAN-B, and MedKAN-L. Experimental results on nine public medical imaging datasets demonstrate that MedKAN achieves superior performance compared to CNN- and Transformer-based models, highlighting its effectiveness and generalizability in medical image analysis.
Bringing RGB and IR Together: Hierarchical Multi-Modal Enhancement for Robust Transmission Line Detection
Jan 25, 2025Ensuring a stable power supply in rural areas relies heavily on effective inspection of power equipment, particularly transmission lines (TLs). However, detecting TLs from aerial imagery can be challenging when dealing with misalignments between visible light (RGB) and infrared (IR) images, as well as mismatched high- and low-level features in convolutional networks. To address these limitations, we propose a novel Hierarchical Multi-Modal Enhancement Network (HMMEN) that integrates RGB and IR data for robust and accurate TL detection. Our method introduces two key components: (1) a Mutual Multi-Modal Enhanced Block (MMEB), which fuses and enhances hierarchical RGB and IR feature maps in a coarse-to-fine manner, and (2) a Feature Alignment Block (FAB) that corrects misalignments between decoder outputs and IR feature maps by leveraging deformable convolutions. We employ MobileNet-based encoders for both RGB and IR inputs to accommodate edge-computing constraints and reduce computational overhead. Experimental results on diverse weather and lighting conditionsfog, night, snow, and daytimedemonstrate the superiority and robustness of our approach compared to state-of-the-art methods, resulting in fewer false positives, enhanced boundary delineation, and better overall detection performance. This framework thus shows promise for practical large-scale power line inspections with unmanned aerial vehicles.
Benchmarking Graph Representations and Graph Neural Networks for Multivariate Time Series Classification
Jan 14, 2025Multivariate Time Series Classification (MTSC) enables the analysis if complex temporal data, and thus serves as a cornerstone in various real-world applications, ranging from healthcare to finance. Since the relationship among variables in MTS usually contain crucial cues, a large number of graph-based MTSC approaches have been proposed, as the graph topology and edges can explicitly represent relationships among variables (channels), where not only various MTS graph representation learning strategies but also different Graph Neural Networks (GNNs) have been explored. Despite such progresses, there is no comprehensive study that fairly benchmarks and investigates the performances of existing widely-used graph representation learning strategies/GNN classifiers in the application of different MTSC tasks. In this paper, we present the first benchmark which systematically investigates the effectiveness of the widely-used three node feature definition strategies, four edge feature learning strategies and five GNN architecture, resulting in 60 different variants for graph-based MTSC. These variants are developed and evaluated with a standardized data pipeline and training/validation/testing strategy on 26 widely-used suspensor MTSC datasets. Our experiments highlight that node features significantly influence MTSC performance, while the visualization of edge features illustrates why adaptive edge learning outperforms other edge feature learning methods. The code of the proposed benchmark is publicly available at \url{https://github.com/CVI-yangwn/Benchmark-GNN-for-Multivariate-Time-Series-Classification}.
MedCoDi-M: A Multi-Prompt Foundation Model for Multimodal Medical Data Generation
Jan 08, 2025



Artificial Intelligence is revolutionizing medical practice, enhancing diagnostic accuracy and healthcare delivery. However, its adaptation in medical settings still faces significant challenges, related to data availability and privacy constraints. Synthetic data has emerged as a promising solution to mitigate these issues, addressing data scarcity while preserving privacy. Recently, Latent Diffusion Models have emerged as a powerful tool for generating high-quality synthetic data. Meanwhile, the integration of different modalities has gained interest, emphasizing the need of models capable of handle multimodal medical data.Existing approaches struggle to integrate complementary information and lack the ability to generate modalities simultaneously. To address this challenge, we present MedCoDi-M, a 6.77-billion-parameter model, designed for multimodal medical data generation, that, following Foundation Model paradigm, exploits contrastive learning and large quantity of data to build a shared latent space which capture the relationships between different data modalities. Further, we introduce the Multi-Prompt training technique, which significantly boosts MedCoDi-M's generation under different settings. We extensively validate MedCoDi-M: first we benchmark it against five competitors on the MIMIC-CXR dataset, a state-of-the-art dataset for Chest X-ray and radiological report generation. Secondly, we perform a Visual Turing Test with expert radiologists to assess the realism and clinical relevance of the generated data, ensuring alignment with real-world scenarios. Finally, we assess the utility of MedCoDi-M in addressing key challenges in the medical field, such as anonymization, data scarcity and imbalance learning. The results are promising, demonstrating the applicability of MedCoDi-M in medical contexts. Project page is at https://cosbidev.github.io/MedCoDi-M/.
Distilled Transformers with Locally Enhanced Global Representations for Face Forgery Detection
Dec 28, 2024



Face forgery detection (FFD) is devoted to detecting the authenticity of face images. Although current CNN-based works achieve outstanding performance in FFD, they are susceptible to capturing local forgery patterns generated by various manipulation methods. Though transformer-based detectors exhibit improvements in modeling global dependencies, they are not good at exploring local forgery artifacts. Hybrid transformer-based networks are designed to capture local and global manipulated traces, but they tend to suffer from the attention collapse issue as the transformer block goes deeper. Besides, soft labels are rarely available. In this paper, we propose a distilled transformer network (DTN) to capture both rich local and global forgery traces and learn general and common representations for different forgery faces. Specifically, we design a mixture of expert (MoE) module to mine various robust forgery embeddings. Moreover, a locally-enhanced vision transformer (LEVT) module is proposed to learn locally-enhanced global representations. We design a lightweight multi-attention scaling (MAS) module to avoid attention collapse, which can be plugged and played in any transformer-based models with only a slight increase in computational costs. In addition, we propose a deepfake self-distillation (DSD) scheme to provide the model with abundant soft label information. Extensive experiments show that the proposed method surpasses the state of the arts on five deepfake datasets.
DEGSTalk: Decomposed Per-Embedding Gaussian Fields for Hair-Preserving Talking Face Synthesis
Dec 28, 2024



Accurately synthesizing talking face videos and capturing fine facial features for individuals with long hair presents a significant challenge. To tackle these challenges in existing methods, we propose a decomposed per-embedding Gaussian fields (DEGSTalk), a 3D Gaussian Splatting (3DGS)-based talking face synthesis method for generating realistic talking faces with long hairs. Our DEGSTalk employs Deformable Pre-Embedding Gaussian Fields, which dynamically adjust pre-embedding Gaussian primitives using implicit expression coefficients. This enables precise capture of dynamic facial regions and subtle expressions. Additionally, we propose a Dynamic Hair-Preserving Portrait Rendering technique to enhance the realism of long hair motions in the synthesized videos. Results show that DEGSTalk achieves improved realism and synthesis quality compared to existing approaches, particularly in handling complex facial dynamics and hair preservation. Our code will be publicly available at https://github.com/CVI-SZU/DEGSTalk.
BIG-MoE: Bypass Isolated Gating MoE for Generalized Multimodal Face Anti-Spoofing
Dec 24, 2024In the domain of facial recognition security, multimodal Face Anti-Spoofing (FAS) is essential for countering presentation attacks. However, existing technologies encounter challenges due to modality biases and imbalances, as well as domain shifts. Our research introduces a Mixture of Experts (MoE) model to address these issues effectively. We identified three limitations in traditional MoE approaches to multimodal FAS: (1) Coarse-grained experts' inability to capture nuanced spoofing indicators; (2) Gated networks' susceptibility to input noise affecting decision-making; (3) MoE's sensitivity to prompt tokens leading to overfitting with conventional learning methods. To mitigate these, we propose the Bypass Isolated Gating MoE (BIG-MoE) framework, featuring: (1) Fine-grained experts for enhanced detection of subtle spoofing cues; (2) An isolation gating mechanism to counteract input noise; (3) A novel differential convolutional prompt bypass enriching the gating network with critical local features, thereby improving perceptual capabilities. Extensive experiments on four benchmark datasets demonstrate significant generalization performance improvement in multimodal FAS task. The code is released at https://github.com/murInJ/BIG-MoE.
DAMPER: A Dual-Stage Medical Report Generation Framework with Coarse-Grained MeSH Alignment and Fine-Grained Hypergraph Matching
Dec 19, 2024



Medical report generation is crucial for clinical diagnosis and patient management, summarizing diagnoses and recommendations based on medical imaging. However, existing work often overlook the clinical pipeline involved in report writing, where physicians typically conduct an initial quick review followed by a detailed examination. Moreover, current alignment methods may lead to misaligned relationships. To address these issues, we propose DAMPER, a dual-stage framework for medical report generation that mimics the clinical pipeline of report writing in two stages. In the first stage, a MeSH-Guided Coarse-Grained Alignment (MCG) stage that aligns chest X-ray (CXR) image features with medical subject headings (MeSH) features to generate a rough keyphrase representation of the overall impression. In the second stage, a Hypergraph-Enhanced Fine-Grained Alignment (HFG) stage that constructs hypergraphs for image patches and report annotations, modeling high-order relationships within each modality and performing hypergraph matching to capture semantic correlations between image regions and textual phrases. Finally,the coarse-grained visual features, generated MeSH representations, and visual hypergraph features are fed into a report decoder to produce the final medical report. Extensive experiments on public datasets demonstrate the effectiveness of DAMPER in generating comprehensive and accurate medical reports, outperforming state-of-the-art methods across various evaluation metrics.
{S$^3$-Mamba}: Small-Size-Sensitive Mamba for Lesion Segmentation
Dec 19, 2024Small lesions play a critical role in early disease diagnosis and intervention of severe infections. Popular models often face challenges in segmenting small lesions, as it occupies only a minor portion of an image, while down\_sampling operations may inevitably lose focus on local features of small lesions. To tackle the challenges, we propose a {\bf S}mall-{\bf S}ize-{\bf S}ensitive {\bf Mamba} ({\bf S$^3$-Mamba}), which promotes the sensitivity to small lesions across three dimensions: channel, spatial, and training strategy. Specifically, an Enhanced Visual State Space block is designed to focus on small lesions through multiple residual connections to preserve local features, and selectively amplify important details while suppressing irrelevant ones through channel-wise attention. A Tensor-based Cross-feature Multi-scale Attention is designed to integrate input image features and intermediate-layer features with edge features and exploit the attentive support of features across multiple scales, thereby retaining spatial details of small lesions at various granularities. Finally, we introduce a novel regularized curriculum learning to automatically assess lesion size and sample difficulty, and gradually focus from easy samples to hard ones like small lesions. Extensive experiments on three medical image segmentation datasets show the superiority of our S$^3$-Mamba, especially in segmenting small lesions. Our code is available at https://github.com/ErinWang2023/S3-Mamba.