 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSL: A Large-scale Chinese Scientific Literature Dataset
Paper and Code

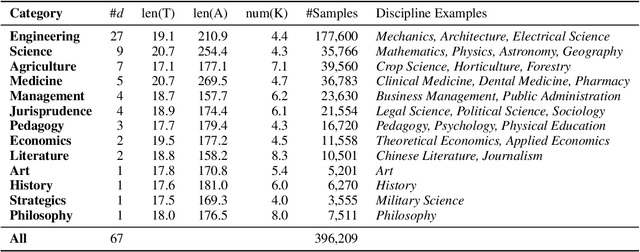
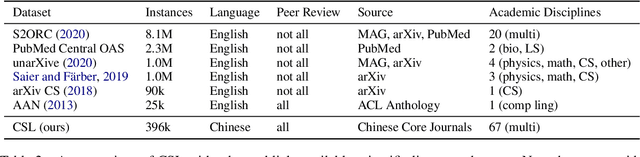
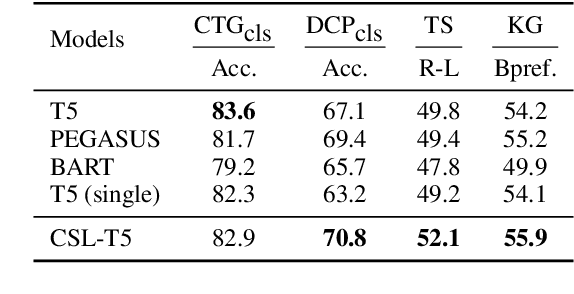
Scientific literature serves as a high-quality corpus, supporting a lot of Natural Language Processing (NLP) research. However, existing datasets are centered around the English language, which restricts the development of Chinese scientific NLP. In this work, we present CSL, a large-scale Chinese Scientific Literature dataset, which contains the titles, abstracts, keywords and academic fields of 396k papers. To our knowledge, CSL is the first scientific document dataset in Chinese. The CSL can serve as a Chinese corpus. Also, this semi-structured data is a natural annotation that can constitute many supervised NLP tasks. Based on CSL, we present a benchmark to evaluate the performance of models across scientific domain tasks, i.e., summarization, keyword generation and text classification. We analyze the behavior of existing text-to-text models on the evaluation tasks and reveal the challenges for Chinese scientific NLP tasks, which provides a valuable reference for future research. Data and code are available at https://github.com/ydli-ai/CSL